现场学习技巧

在我们的另一篇文章中,我们介绍了不同的技术,使LLM在商业场景中更易于使用。大多数情况下,这些情景需要模型了解业务数据和要查询的文件。实现这种认知的一种有前途的方法是上下文学习的概念,在查询时为LLM提供相关数据。由于模型没有经过精细调整,因此可以节省调整模型权重的计算成本,并同时具有查询上下文的灵活性。在本文中,我们将例举基本的上下文学习方法及其在外部提供和自托管的LLM中的缺点。
文档查询的魅力与诅咒
在上下文学习中,将您想要查询的数据封装到LLM提示中:例如查找特定细节的全部合同,或查找最高收入周的长销售表,或查找最新空缺职位与最佳匹配的候选人简历 - 所有这些都只需要用一种明确的英语问题定义。这种方法可能看似非常简单:通过提示将您考虑相关的所有文档馈送给LLM,添加您的问题,并等待LLM回答。但是,即使最终获得所需的结果,您也可能会对等待答案的时间感到失望,或因模型提供者的高额账单而感到沮丧。当您将文档馈送到LLM时,您正在增加其处理的令牌数量,从而增加了履行您的请求所需的时间和昂贵的计算资源。简而言之:我们需要比不进行前期筛选而将所有文档传递给模型的更好策略。
选择相关文件。
在接下来的内容中,我们将使用LlamaIndex库为例,探讨以下战略:我们希望询问LLM在一组潜在候选人中认为谁是最适合担任一个开放职位的人选。我们建议它在候选人的简历旁边加入工作描述。
The Llama Index library提供了一些非常有用的工具集,用于选择和传递适当的文档给LLM。文档集被分解成节点,这些节点又按索引组织。这些索引可以是有序列表,文档树或向量空间中无序的文档集,称为向量索引。为每种类型的文档选择正确的索引对于可靠地检索所需的文档以及查询的性能至关重要。
矢量指数
翻译如下: 向量索引对于具有大量文档的情况特别有趣,这些文档一次性输入到LLM中太多了。它们是通过给集合中每个文档分配一个向量表示,称为嵌入,来构建的。这些嵌入编码了文档的语义相似性,并使用另一个嵌入LLM(通常是比要求节省成本或资源的模型低效的模型)创建。现在通过语义接近性查询索引意味着检索与查询向量最接近的文档的嵌入。
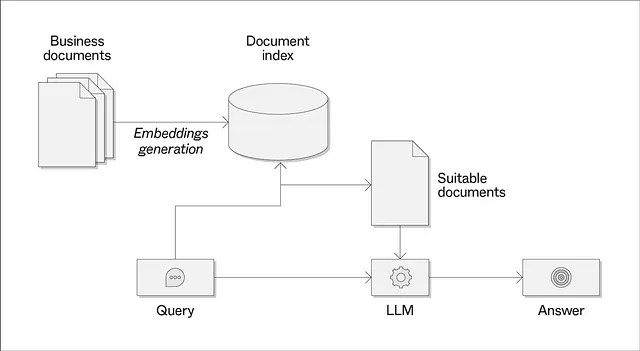
一种天真的索引方法
回到使用LlamaIndex库的人力资源用例,第一次尝试可能是将所有文件,即工作提供和候选人简介,全部放入一个向量索引中,并让库选出适合我们的文件。
我们首先使用LlamaIndex的SimpleDirectoryReaders分别加载两组文档:
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
profile_documents = SimpleDirectoryReader('data/employee_profiles').load_data()
job_offer_documents = SimpleDirectoryReader('data/job_offers').load_data()然后我们从中创建一个向量索引。
combined_index = GPTVectorStoreIndex([])
for documents in [profile_documents, job_offer_documents]:
for document in documents:
combined_index.insert(document)查询LLM,我们可以从索引对象中创建一个查询引擎:
query_engine = combined_index.as_query_engine()
query_string = '''
Give me a score to what extent each of the candidates is suited for the 'freelance
project manager' project?
'''
query_engine.query(query_string)虽然理论上可能有效,但在我们的例子中,重新运行它产生随机结果。
First run:
Candidate D: 8/10
Candidate I: 6/10
Candidate X: 5/10
Candidate M: 7/10
Second run:
Candidate I: 8/10
Candidate X: 6/10
Candidate D: 5/10
Candidate M: 7/10经仔细检查后发现,仅有两份文件传递给LLM,使LLM无法对所有潜在候选人发表声明。
定制检索机制
因此,在此特定情况下,我们需要让LlamaIndex根据我们的需要选择文件。 对于上述查询,这意味着将所有候选人简介传递给LLM,因为我们希望得到关于所有候选人和单个招聘职位的声明。
为此,我们实施了一个自定义文档检索器,依赖于两个文档索引:所有候选人资料的列表索引和所有潜在工作机会的向量索引。
from llama_index.indices.base_retriever import BaseRetriever
class ProfileQueryRetriever(BaseRetriever):
def __init__(self, profile_index: GPTListIndex, job_offer_index: GPTVectorStoreIndex) -> None:
super().__init__()
self._profile_index = profile_index
self._job_offer_index = job_offer_index在定制的检索器类中,我们实现了方法 _retrieve,使得每个查询都会返回所有的候选档案以及与查询在语义上最接近的工作提供。它使用方法 _get_embeddings 获取查询和工作提供文档的嵌入,以在语义上比较工作提供和查询。
from llama_index.data_structs import Node, NodeWithScore
from llama_index.indices.query.schema import QueryBundle
from llama_index.indices.query.embedding_utils import get_top_k_embeddings
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""Collect all nodes from the profile index and
the closest node from the job offer index."""
# include all profile nodes
nodes_with_scores = [
NodeWithScore(node=node, score=1)
for node in self._profile_index.docstore.get_nodes(
self._profile_index.index_struct.nodes
)
]
# include the job offer node whose semantic embedding is closest
# to the embedding of the query
job_offer_nodes = self._job_offer_index.docstore.get_nodes(
self._job_offer_index.index_struct.nodes_dict.values()
)
query_embedding, job_offer_node_embeddings = self._get_embeddings(
query_bundle, job_offer_nodes
)
top_similarities, top_idxs = get_top_k_embeddings(
query_embedding,
job_offer_node_embeddings,
similarity_top_k=1,
embedding_ids=list(range(len(job_offer_nodes))),
)
nodes_with_scores += [
NodeWithScore(node=node, score=score)
for node, score in zip(
[job_offer_nodes[idx] for idx in top_idxs], top_similarities
)
]
return nodes_with_scores
def _get_embeddings(
self, query_bundle: QueryBundle, nodes: List[Node]
) -> Tuple[List[float], List[List[float]]]:
"""Get embeddings of the query and a list of nodes."""
if query_bundle.embedding is None:
query_bundle.embedding = self._job_offer_index._service_context.embed_model.get_agg_embedding_from_queries(
query_bundle.embedding_strs
)
node_embeddings: List[List[float]] = []
for node in nodes:
if node.embedding is None:
node.embedding = self._job_offer_index.service_context.embed_model.get_text_embedding(
node.get_text()
)
node_embeddings.append(node.embedding)
return query_bundle.embedding, node_embeddings或者,人们可以选择一种简单的关键字匹配方法,它可以足以找到所需的工作职位。
现在可以通过自定义文档检索器来发送查询,具体方法如下:
retriever = ProfileQueryRetriever(profile_index, job_offer_index)
retriever_engine = RetrieverQueryEngine(retriever=retriever)
query='''
Give me a score to what extent each of the candidates is suited for the
'freelance project manager' project?
'''
response = retriever_engine.query(query)现在,所有候选人的个人资料和有关工作的招聘信息都会始终传送到LLM,并针对每位候选人给出一致的评分。此外,现在还可以对候选人的具体能力进行更详细的询问。
自托管模型的潜力
在像我们上面所做的那样直接使用LlamaIndex时,该库使用OpenAI的LLM进行嵌入的生成和查询的回答。在具有专有数据的业务场景中,这通常是不可取的,因为数据受数据保护或保密政策的约束。随着越来越强大的开源和商业友好的授权模型的出现,例如gpt4all或MPT 7B,数据感知的LLM查询在受控和安全的环境中,如私有云网络或本地环境中,现在只有一步之遥。
作为概念验证,我们将我们的人力资源用例从默认的LlamaIndex设置与OpenAI移植到具有GPU设备的云笔记本上,在此设置中,我们加载了MPT 7B模型。通过这种设置,我们也能够查询我们的文档。由于随着输入的大小而急剧增加的内存需求,当将两个以上的文档传递给LLM时,云环境很快达到其限制。除此之外,要使用MPT 7B模型进行推理,需要使用顶级GPU才能从LLM获得即时响应。
虽然这表明在您自己的硬件或自己的云网络上运行数据感知的LLM应用程序是可能的,但它强调需要考虑周全的方法来选择和提供LLM中的文档,因为计算资源在今天的LLM所需的数量级上是有限的。








