在无代码方法中学习如何使用Dolly V2数据集来微调LLaMA-7B
微调预训练模型是NLP中的关键实践,以优化其在特定任务中的性能。作为开发人员,我了解微调模型以在目标应用程序中获得更好结果的重要性。

然而,这个过程也伴随着它自己的一些挑战。我个人遇到了许多困难,这些困难妨碍了Fine-tune的过程。一个重要的障碍是Fine-tune LLMs所需的复杂设置,包括管理内存限制和处理昂贵的GPU。此外,缺乏既定的规则使得这个过程更加令人生畏。
LLaMA 7B是Meta AI开发的令人印象深刻的语言模型,在各种应用中具有巨大的潜力。然而,对这个模型进行微调可能是一个令人生畏的任务,特点是复杂的设置,内存限制,高昂的GPU成本和缺乏标准化的实践。
在这篇博客中,我将分享克服这些障碍的经验,并展示Monster API如何让我轻松调整带有Dolly v2数据集的LLaMA 7B,而成本只是一小部分。
但首先,什么是LLaMA?
LLaMA(大型语言模型元AI)是由Facebook人工智能研究院(FAIR)开发的基础大型语言模型(LLM),用于机器翻译任务。LLaMA基于Transformer架构,这是一种神经网络架构,专门处理顺序数据,如文本。
LLaMA有几种不同的尺寸可供选择(7B, 13B, 33B和65B参数)。其中LLaMA 7B是最小的尺寸,共有70亿参数。
该模型是在大量的多语言数据上进行训练的,使其能够在许多不同的语言对之间进行翻译。 LLaMA的一个关键优势是其灵活性 - 它可以在任何类型的对话数据上进行训练,并可以与各种消息平台集成。
此外,什么是Databricks Dolly V2 数据集?
Databricks的Dolly V2数据集,特别是“data bricks-dolly-15k”语料库,是由Databricks员工创建的超过15,000条记录的集合。该数据集的目的是使LLMs能够展示像ChatGPT这样的互动和引人入胜的对话能力。
我将使用这个多样化和丰富的Databricks Dolly V2数据集来微调LLaMA 7B模型。
什么是LLM的微调,为什么它如此重要?
语言模型,例如LLaMA,通过大量的通用语言数据来训练,以学习模式、语法和上下文信息。然而,当直接应用于特定任务或领域时,它们可能无法实现最佳性能。
通过微调,用户可以提高模型的性能,使其…
- 更准确
- 上下文感知
- 与目标应用程序对齐。
微调使我们能够根据特定任务定制预训练模型,有效地将它们的通用语言知识转移到专门的任务中。
为了更好地解释微调,考虑以下例子 -
想象一下,您是一位旅行应用程序开发者,正在创建一个聊天机器人来帮助用户找到最佳的度假目的地。
建立一个智能聊天机器人,需要一个语言模型,能够不仅理解自然语言,还具备关于热门旅游目的地、旅游景点和酒店推荐的知识。
不必从零开始训练LLM,这需要大量的数据和计算资源,您可以从像LLaMA这样的预训练模型开始。然而,由于LLaMA没有针对旅行相关任务进行特殊训练,因此它的响应可能无法准确回答旅行查询。
这就是微调的作用!
通过在专门策划的旅游信息数据集上对LLaMA 7B进行微调,您可以使模型适应于更好地理解和生成与度假规划相关的响应。微调过程教会模型旅游相关语言的细微差别,并使其知识与旅行应用的要求相一致。
只要生活可以这么简单!

微调带来了很多挑战。让我深入探讨这些挑战并分享我的经验。
- 复杂的安装设置:首先,复杂的设置可能会让人十分头痛。微调需要配置正确的库、依赖和框架,以确保预训练模型、数据集和所需任务之间的兼容性。这可能非常耗时和令人沮丧,特别是当涉及到不同版本和兼容性问题时。
- 内存要求:内存不足问题是另一个常见的障碍。对于像LLaMA这样的大型模型进行微调需要大量的内存资源。不幸的是,不能所有的开发人员都可以访问内存容量充足的高端GPU。这种限制经常导致训练过程中崩溃或冻结,迫使我们优化代码并尝试批处理大小。
- GPU成本:不要忘记GPU的成本。GPU对于加速深度学习任务至关重要,但是它们很昂贵。精细调整模型,尤其是在长时间内,成本很快就会累积,这使得它成为不是所有开发人员都能负担得起的奢侈品。这是在优化性能和管理预算之间不断平衡的过程。
- 标准化实践:最后,缺乏标准化实践可能会令人沮丧。微调技术、工具和最佳实践不断发展,使得找到一种一致可靠的方法变得具有挑战性。作为开发人员,我们经常不得不在文档、论坛和尝试错误中穿行,以找到最有效的微调策略。
总之,微调距离轻松愉快还有很远的路要走。复杂的设置、内存不足的困扰、GPU成本以及缺乏标准化实践使其变得崎岖不平。
银衬衫
如何使用Monster API来帮助解决挑战?
Monster API已将通常复杂的微调过程简化和有效地转变为直观、快捷的用户界面方法,将复杂的设置简化为简单易懂的本地方法。我使用Databricks Dolly 15k在LoRA下对LLaMA 7B进行了3个时期的微调。最好的一点是?这花费了我不到20美元。
只要五个简单的步骤,我就能够设置自己的微调任务并取得令人印象深刻的结果。
让我们开始吧!
选择LLM:第一步是从可用的选项中选择LLM,包括像Llama 7B、GPT-J 6B或StableLM 7B这样的热门模型。
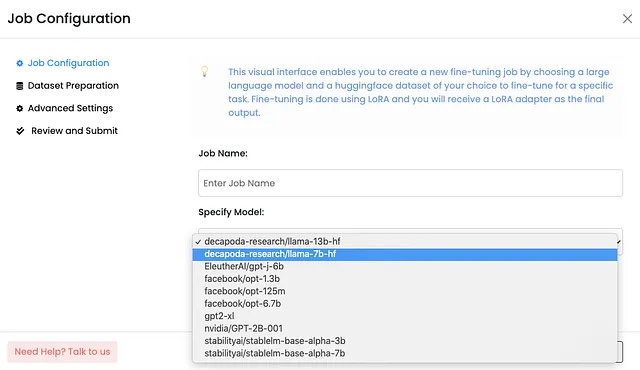
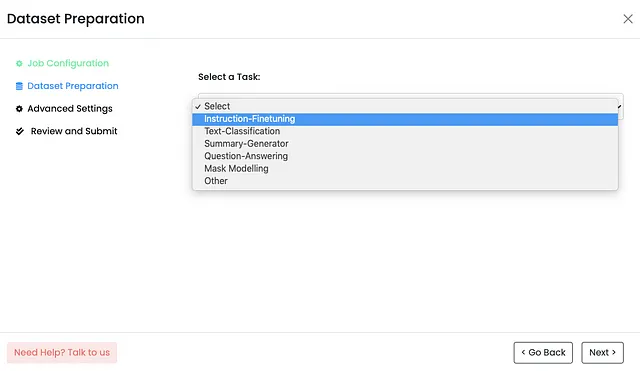
选择或创建任务:接下来,我需要为微调LLM定义任务。Monster API提供了一系列预定义的任务,如“指令微调”或“文本分类”。然而,我还可以选择“其他”选项来创建自定义任务。这种灵活性使我能够根据我的具体需求微调LLM。
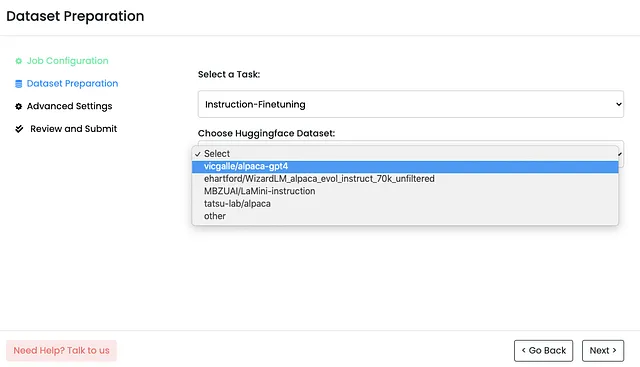
选择一个HuggingFace数据集:为了有效地训练LLM,我需要一个高质量的数据集。Monster API与HuggingFace数据集无缝集成,提供了广泛的选择。该平台甚至根据我选择的任务建议适用的数据集。只需要几个点击,选择的数据集就会自动格式化并准备好使用。
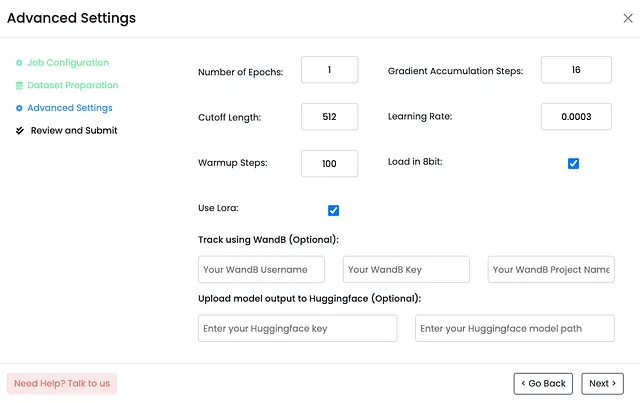
指定超参数:Monster API根据我选择的LLM预先填充了大部分的超参数。然而,我有自由修改这些参数,如:epochs、学习率、截断长度、预热步骤等,以满足我的具体要求。这种程度的定制化允许我精细调整LLM,从而实现所需的效果。
审核并提交工作:设置所有参数后,我点击“下一步”进入摘要页面。这一步非常重要,因为它让我检查所有设置以确保一切准确无误。一旦我确认了细节,我就提交了工作,Monster API负责其余的工作。
那就这样!在5个简单的步骤中,我的微调设置就完成了。
我被这个过程的简单明了所感动,它让我能够更专注于我的任务,而不是纠缠于复杂的配置上。Monster API 负责优化模型,确保它符合可用的 GPU 内存的限制。将这些复杂的环境和 GPU 设置抽象出来,让我专注于微调方面。
通过 Monster API 成功设置了我的微调工作后,我能够查看作业的日志,从而获得详细的洞察力。
真相的时刻
在微调过程结束时,我获得了一个LoRA适配器文件,它可以作为微调LLM和推理阶段之间的桥梁。
让我们来探索一下结果吧!
整个微调过程从开始到结束大约花费了8个小时,也就是505分钟。考虑到对大型语言模型的微调的复杂性,这是一个令人印象深刻的周转时间。
为了向您提供结果的可视化表示,我已经附上了来自WandB Metrics的相关图表,以便让您更好地理解。这些图表提供了对微调过程的性能和进展的全面理解。
损失曲线:损失曲线图展示了经过时间调整的LLM模型的训练进度。它展示了模型学习和适应数据集时损失值的减少。
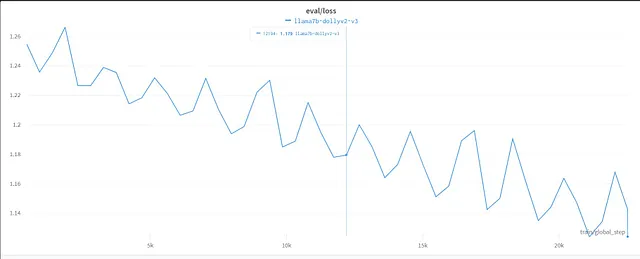
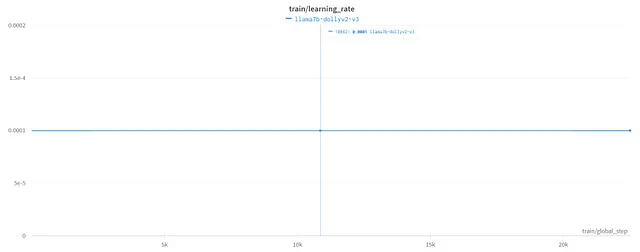
学习率:学习率图形提供了有关模型在训练过程中调整其参数速度的信息。它通过展示学习率随时间变化的方式揭示了优化过程。
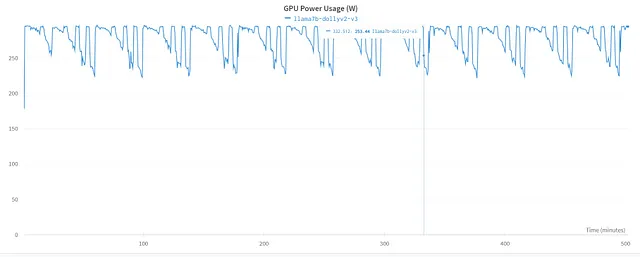
GPU电力使用:GPU电力使用图表描述了在微调过程中GPU计算能力的利用率。
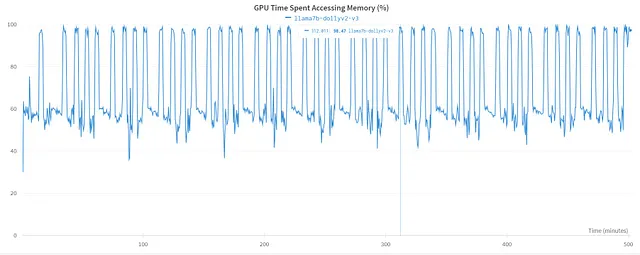
GPU 花费在访问内存的时间:内存访问是影响性能的关键因素。监控和优化内存访问有助于减少瓶颈并最大化 GPU 效率。
GPU温度(°C):GPU温度图表提供了GPU在微调过程中的热情况的可视化表示。
这些WandB指标图提供对微调过程的宝贵洞见,允许对各个方面进行详细分析,例如损失、学习速率、GPU功率使用、GPU内存访问、GPU温度等。
最终说明
作为一名开发者,我采用 Monster API 进行细化 LLMs 的修整是一次具有转变性经历,我可以自信地说。
使用Monster API优化LLM的过程变得简化和便捷。该平台提供了易于使用的界面,使我能够选择LLM,定义任务,选择数据集并指定超参数。逐步的方法消除了猜测和困惑,为我提供了清晰的路径可供跟随。
最近我了解到,Monster API最突出的特点之一是它的去中心化GPU网络。这种能力大大降低了访问强大计算资源所需的成本和复杂性。
在我的亲身经历中,我使用Databricks Dolly V2数据集对LLaMA 7B模型进行了三次时期的微调,整个过程花费不到20美元。
这种负担得起并且容易接触的水平为那些以前因资源有限而面临障碍的开发者打开了新的可能性。
结论
我的精细调试的LLM表现出了增强的性能,因为它捕捉到了上下文的理解,保持了连贯性,且生成了更准确的回答。
总之,Monster API 与微调LLM的旅程是一种有益的体验。它不仅解决了挑战,也帮助我作为开发人员探索了这些语言模型的全部潜力。
通过分享这个账户,我希望能够激励其他开发人员,并为使用Monster API时可能存在的机遇和解决方案提供见解。
资源:
- 怪物API - 怪物API
- 微调文档 - GitBooks
- Databricks Dolly数据集 - HuggingFace
- LLaMA 模型 — HuggingFace
- LLaMA GitHub 页面 — GitHub





