动态小样本指导:克服ChatGPT文本分类的上下文限制
近期,像ChatGPT这样的大型语言模型的普及引发了它们在经典的NLP任务中,比如语言分类,的使用增加。这些任务包括提供上下文(样本)和候选标签给模型来进行推理。更准确地说,这个方法被称为零样本分类,这意味着模型不必重新训练以推广到新的/未见过的类别。自然地,从商业角度来看,不必调整模型以适应特定任务可以极大地受益,因为它显著缩短了开发时间并减轻了维护自定义模型的额外负担。
然而,零样本方法的一个缺点是它有限的能力利用现有标注样本(训练数据)。在本文中,我们将看到如何使用动态少样本提示来解决这个问题,该提示仅包括提示中相关的训练数据子集。
本文中的所有代码示例都使用Scikit-LLM库。请查看我的先前帖子获取更多信息。
回顾: 零样本 vs 少样本提示
在深入探讨动态少样本提示之前,让我们简要回顾零样本和少样本提示的概念。
零射发是一种方法,在此方法中ChatGPT,或任何其他语言模型被用于分类文本,而无需任何额外的任务特定训练。它涉及针对模型制定问题或任务,并为其提供选择。基本上,模型利用它所受的训练知识来完成任务。
一个非常简单的零-shot提示可以像这样:
Input: "The rover landed on Mars after a seven-month journey."
Prompt: "Is this text about Science, Sports, or Politics?"在底层,Scikit-LLM的`ZeroShotGPTClassifier`也使用零样本提示,只需三行代码就可以构建一个估计器。
from skllm import ZeroShotGPTClassifier
clf = ZeroShotGPTClassifier(openai_model = "gpt-3.5-turbo")
clf.fit(X, y)
labels = clf.predict(X)另一方面,少量示例提示使ChatGPT在输入旁边提供了几个例子。这有助于为任务提供背景,并为模型的响应提供方向。看到这些例子,模型就能理解期望的输出,从而提高其在各种任务中的性能。
示例提示:
Example 1:
Input: "The athlete won a gold medal at the Olympics."
Output: "Sports"
Example 2:
Input: "The legislation was passed after a long debate in the Senate."
Output: "Politics"
Example 3:
Input: "The discovery of the Higgs boson at CERN marked a milestone in particle physics."
Output: "Science"
Task:
Input: "The rover landed on Mars after a seven-month journey."
Prompt: "Is this text about Science, Sports, or Politics?"示例代码:
from skllm import FewShotGPTClassifier
clf = FewShotGPTClassifier(openai_model="gpt-3.5-turbo")
clf.fit(X, y)
labels = clf.predict(X)动态少样本提示
虽然在纸面上,少量提示看起来很不错,因为它允许利用训练数据集中的信息来进行预测,但它具有显着的可伸缩性问题。
为了理解问题,让我们来看看之前的几个样本任务提示。
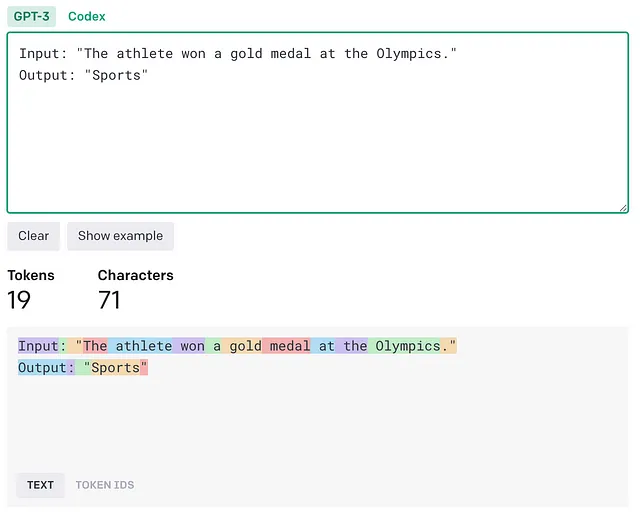
Input: "The athlete won a gold medal at the Olympics."
Output: "Sports"如果我们通过OpenAI分词器的网络界面进行传递,我们可以看到该文本对应于19个标记。
为什么这很重要?
首先,现代 LLMs 具有有限的上下文长度。例如,最流行的 OpenAI 模型 gpt-3.5-turbo 的上下文限制为 4096 个令牌,而大多数当前代开源模型则限制为 2048 个令牌。考虑到我们的样本长度只有 19 个令牌,我们最多只能为 gpt-3.5-turbo 提供 215 个样本或为像 LLaMA 这样的开源 LLM 提供 107 个样本。在实际情况下,这个数字会更低,因为我们没有考虑提示本身消耗的额外令牌。此外,需要分类的文本样本通常要长得多。
即使上下文大小没有限制,处理更长的提示需要更多的计算资源,这通常与更高的财务成本相关。
一个非常自然的解决问题的方法是仅针对提示本身使用训练数据的子集。
这正是`DynamicFewShotGPTClassifier`的作用。在推理过程中,针对每个未标记的数据点,它动态地选择每个类别中的N个训练样本用于提示。
from skllm import DynamicFewShotGPTClassifier
clf = DynamicFewShotGPTClassifier(n_examples=3)
clf.fit(X, y)
labels = clf.predict(X)为了更好地理解它是如何运作的,让我们考虑一个玩具例子,目标是弄清楚这个人是在谈论书 还是电影。
from skllm import DynamicFewShotGPTClassifier
X = [
"I love reading science fiction novels, they transport me to other worlds.",
"A good mystery novel keeps me guessing until the very end.",
"Historical novels give me a sense of different times and places.",
"I love watching science fiction movies, they transport me to other galaxies.",
"A good mystery movie keeps me on the edge of my seat.",
"Historical movies offer a glimpse into the past.",
]
y = ["books", "books", "books", "movies", "movies", "movies"]
query = "I have fallen deeply in love with this sci-fi book; its unique blend of science and fiction has me spellbound."
clf = DynamicFewShotGPTClassifier(n_examples=1).fit(X, y)
prompt = clf._get_prompt(query)
print(prompt)以下是分类器自动选择用于提示的示例:
Sample input:
```I love reading science fiction novels, they transport me to other worlds.```
Sample target: books
Sample input:
```I love watching science fiction movies, they transport me to other galaxies.```
Sample target: movies注意到这两个例子都与查询非常相似,因为这些人在所有情况下都在谈论科幻题材。
但是它如何根据新输入动态选择示例的呢?
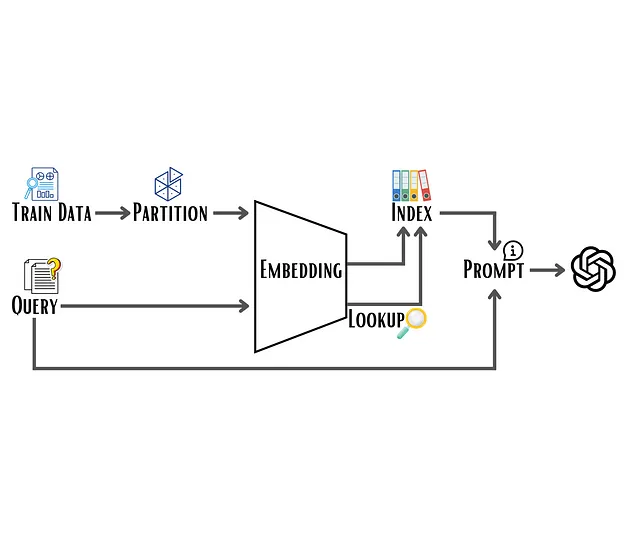
这是通过添加一个经典的KNN(K-最近邻)算法作为额外的预处理器来实现的。如果我们假定最相关的例子是最相似的,那么问题就简化为最近邻搜索,并可以通过三个步骤来解决:
(1) 矢量化
在进行最近邻搜索之前,训练集必须嵌入到固定维度的向量中。这可以很容易地使用OpenAI嵌入API(或任何其他替代品)来实现。
(2) 索引构建
虽然任何最近邻算法都可以用于此任务,甚至可以使用scikit-learn的蛮力选项,但重要的是要注意可扩展性方面,因为我们正在处理非常高维的数据,潜在地还有大量的样本。幸运的是,有很多工具可以非常好地处理这些情况。例如,Spotify开发的用于快速近似最近邻搜索的Annoy库。通过在训练期间仅构建索引,可以在推理期间执行快速的邻居搜索。
(3) 平衡抽样
需要考虑的最后一件事是类别平衡。如果仅选择N个最近的邻居进行少量训练,那么某些类别很有可能会被低估或者完全缺失。为了缓解这个问题,我们不再创建一个单一的索引,而是按类别对训练数据进行分区。通过这种方式,我们能够从每个类别中抽取N个样本,确保每个类别的平衡表示。
结论
在本文中,我们探讨了动态少样本提示的概念,这是一种对文本分类进行零样本和少量样本提示方法的增强,可用于像ChatGPT这样的大型语言模型。我们学习了它如何利用现有的标记数据通过动态选择相关示例来提高分类准确性。通过利用类似于KNN的算法,动态少样本提示过程在使用语言模型固有的从有限示例中进行概括和处理实际应用大规模数据的需求之间创建了一种平衡。
此外,这是一种有效的方法,适应了当前语言模型中上下文长度的限制,并优化了计算资源的使用。