英伟达 Hymba:最好的小型LLM?
根据Mamba x Attention混合机制,胜过Llama3.2,SmolLM
所以,NVIDIA 卷土重来,这一次他们推出了一种独特的 LLM,利用了混合架构,同时使用 Transformers 和 Mamba。根据结果,这个模型在性能上超越了大多数小型 LLM,包括 Llama3.2 3B 和HuggingFace的 SmolLM。
退一步
通常来说,LLM(语言模型)基于两种最流行的架构,即Transformers或Mamba。
Here is the translated text with the same HTML structure: ```html Transformers 使用自注意力机制,而 Mamba 使用状态空间模型。 ```
Sure! Could you confirm if you want the translation to keep any specific HTML tags or structure intact?
在这里了解更多关于曼巴的信息:
什么是NVIDIA Hymba?
- NVIDIA Hymba是一种新颖的小型语言模型架构,结合了注意力机制和状态空间模型(SSM)的优势,即注意力和Mamba。
- Sure! Here’s the translation while keeping the HTML structure intact: ```html This hybrid approach allows for parallel information processing, enhancing both memory recall and context summarization capabilities. ``` ```html 这种混合方法允许并行信息处理,增强了记忆回忆和上下文总结的能力。 ```
- Hymba集成了注意力头,这些头在高分辨率回忆方面表现出色,与SSM头在同一层内提供高效的上下文处理,从而提高模型在各种任务中的灵活性和性能。
建筑
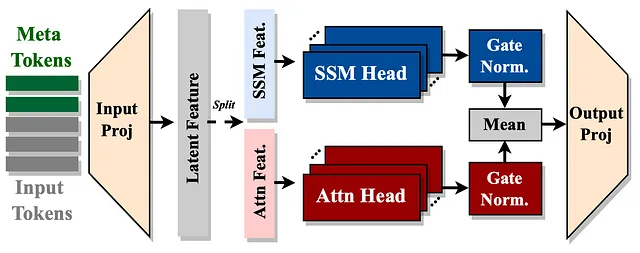
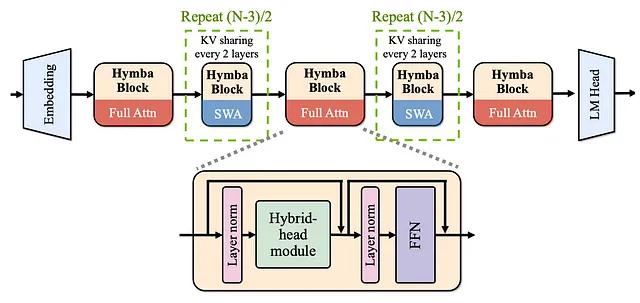
结合注意力和SSM头
- 注意力头部:它们就像聚光灯,聚焦在输入数据的特定部分,帮助模型清晰地记住重要细节。
- SSM 头部:可以将其视为一种随时间总结或浓缩信息的方法,类似于我们可能会忘记不那么重要的细节,同时保持故事的本质。
通过在一个层中融合这两种类型的头部,Hymba能够更有效地处理信息。它可以快速地回忆特定细节,同时也可以高效地总结更广泛的背景,从而使其能够同时处理不同类型的信息。
Here is the translation of "Introduction of Meta Tokens" into Simplified Chinese, while keeping the HTML structure intact: ```html 介绍元代币 ```
Hymba 使用特殊的令牌称为元标记,这些元标记被添加到输入序列的开头。这些标记帮助存储和管理输入处理过程中的重要信息。它们起到的作用类似于记忆辅助,确保模型专注于重要内容,而不会被过多的细节所压倒。
通过跨层共享提高效率
此外,Hymba集成了技术,使其能够在模型的不同层之间共享内存和注意力。这意味着它可以在处理新数据的同时访问来自早期层的相关信息,这提高了内存使用和计算效率。
性能和指标
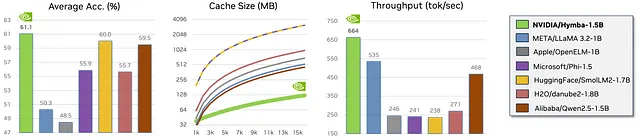
- Here’s the translated text with the HTML structure kept intact: ```html Token Throughput (Tokens/sec): Hymba 实现了 664 tokens/sec,显著高于大多数模型,包括 LLaMA-3.2–3B(191 tokens/sec)和 Qwen2.5(469 tokens/sec)。这表明 Hymba 处理数据的速度更快,这是实时或高需求任务的关键特性。 ```
- 缓存效率:Hymba仅使用79MB的缓存,与其他模型如Phi-1.5(1573MB)和SmolLM(1573MB)相比要小得多。这使其在内存使用方面非常高效,尤其适用于在资源有限的设备上部署。
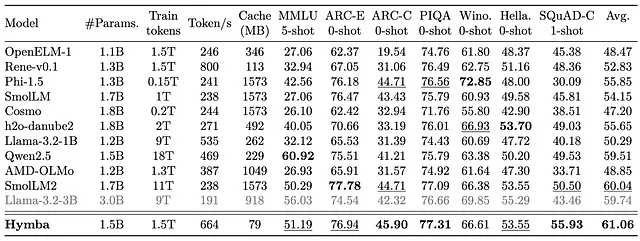
- Here's the translation of "Task Performance" to Simplified Chinese, keeping the HTML structure intact: ```html 任务执行: ```
ARC-E(0射击):Hymba得分76.94,是此基准测试中的顶级表现之一,略低于SmolLM2(77.78)。
PIQA(0-shot):得分为77.31,表现优于所有其他模型,包括Llama-3.2-3B(76.66)和SmolLM2(77.09)。
```html
所有任务的平均分数:Hymba的平均分为61.06,领先于其他模型,如AMD-OLMo(59.51)和LLaMA-3.2–3B(59.74)。
```- 平衡的权衡:尽管参数数量相对较高(1.5B),Hymba仍保持着令人印象深刻的吞吐量、低缓存使用率和优越的任务准确性,使其成为一个同时优化了效率和性能的平衡模型。
Here is the translation of "How to use Hymba?" into Simplified Chinese, keeping the HTML structure intact: ```html 如何使用Hymba? ```
```html
HuggingFace是一个好地方。只需按照模型页面上的代码操作,你就可以开始了。模型权重将于明天(11月23日)发布。
```Here’s the translation with the HTML structure kept intact: ```html Concluding, it's an exciting time to be alive and be a Data Scientist where we are witnessing some crazy innovations every day. Leading the pack of small LLMs now, Hymba can be the actual game changer and may disrupt edge AI and Mobile LLM space 总结来说,现在是活着并作为数据科学家的一段激动人心的时光,我们每天都在见证一些疯狂的创新。目前,Hymba 领跑小型 LLM 的发展,可能会成为真正的游戏规则改变者,并可能颠覆边缘 AI 和移动 LLM 领域。 ```