ChatGPT-4o 可以运行主成分分析 — 但我不建议将它用于其他类似的多元技术。
在过去几周里,我在进行对ChatGPT-4o正确可靠地运行一系列单变量统计技术的基准测试时发现,虽然它能够运行和解释简单的模型,但在处理更复杂的技术时却遇到困难。然而,当处理大量数据时,包括许多不同的响应和预测变量时,单变量统计是不够的,需要使用多变量技术。这适用于许多需要调查植物物种组成变化、微生物组变化或基因表达变化等许多基因变化的研究生。因此,我需要教授多元技术给我的学生。在我的课堂上,我们以一周的线性代数入门课开始,教授学生矩阵乘法和特征值分解,因为如果不理解特征值和特征向量的概念,就无法理解这些技术的运作方式。之后,我介绍基于Bray-Curtis排序方法的排序方法,这可以通过手动完成。最后,我开始讨论多元方法,介绍主成分分析及其解释性对应物——冗余分析,然后是对应分析和经典对应分析。这些方法相当复杂,我不指望学生们对它们有深入的理论理解,而是更专注于这些方法的应用和结果的解释。在课堂上演示这些方法后,学生们需要完成一项任务,展示他们对结果的正确使用和解释的理解。由于运行这些方法并不那么具有挑战性,我提供给学生一个RMarkdown文件,他们可以编织,然后回答我与结果相关的问题。
本周,我的目标是将ChatGPT-4o与这个任务进行基准测试,看看它运行和解释这些方法的结果能有多可靠。因为我在RMarkdown文件中提供给学生R代码,所以我需要将这些代码转换为ChatGPT-4o的提示,这样它就可以创建自己的代码来运行这些技术,尽可能接近在R中运行的情况,然后回答关于生成的结果的问题。以下是我总结ChatGPT-4o能够做到这一切的情况。
这项作业使用了与之前的作业相同的制表符分隔的海洋十足动物数据集。在指定样本ID的列之后,数据集的前12列表示样本中不同十足动物的数量(物种数据集),而最后的7列表示与样本相关的一组环境变量。
首先,我要求ChatGPT-4o对物种数据集运行简单的主成分分析,同时对变量进行归一化处理。归一化很重要,因为否则拥有更大丰度或更大方差的物种可能会在前几个主成分中占据主导地位,而不考虑它们与其他变量的关系。ChatGPT-4o完全有能力完成这个任务,使用了sklearn.decomposition模块中的PCA函数。它提取了主成分,并根据它们解释的总变异百分比进行排序。在询问后,它能够创建一个正确的screeplot,可以在y轴上显示解释的方差(惯性)或解释方差的比例。所有这些结果与在R中获得的结果完全相同。当询问前两个轴是否累积解释了足够的方差以忽略其余的轴时,ChatGPT-4o正确推理认为它们不够(因为它们只解释了总方差的41.31%),并正确指出screeplot得出相同的结论。ChatGPT-4o还正确地创建了一个双标图,其中样本点和箭头表示特定物种变量的载荷与前两个主成分的关系。然而,双标图的比例有所偏差,样本分布更广泛,箭头比在R中通过双标命令产生的双标图中要短得多,无论是相关性还是距离的双标图。有趣的是,获得的载荷值与R中产生的值完全相同。
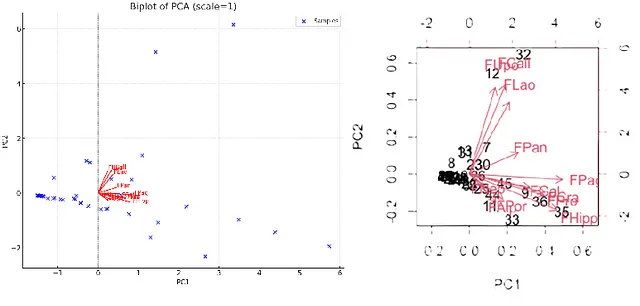
```html 当被问及识别哪些物种与第一主成分呈正相关时,ChatGPT-4o 仅列出几个物种,并建议其他物种呈负相关,尽管所有物种实际上都与该轴呈正相关。然而,当被提及这一点时,它纠正了自己。ChatGPT-4o 在识别哪些物种与第二主成分轴呈正相关时也出现了类似的问题,最初建议了两个错误的物种,然后声称所有物种都呈负相关,明显混淆了第一和第二主成分轴。在经过几次提示后,它最终能够正确识别与第二主成分轴呈正相关的四个物种。相比之下,它在识别哪些样本与特定样本最相似方面表现得更好,依据是根据两个主成分定义的二维空间中具有最小欧几里得距离的样本。它同样能够识别与特定物种最相似和最不相似的物种,尽管它再次使用箭头端点的欧几里得距离作为标准,而不是使用相关双变量图中箭头的角度。 ```
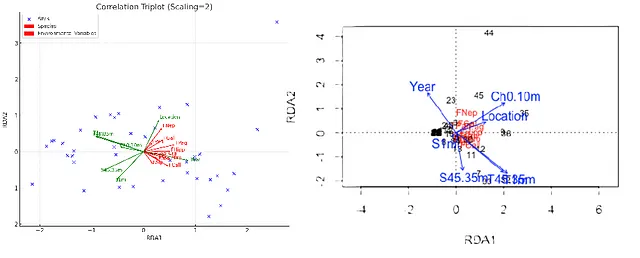
接下来,我让ChatGPT-4o对相同物种数据集进行冗余分析,以查看环境变量的变异中有多少比例可以由相同样本的变异来解释。其中一个环境变量存在缺失值,因此必须删除这些行并对数据集进行归一化,然后再运行分析。ChatGPT-4o顺从了,但我注意到,它没有调用专用的冗余分析函数,而是从sklearn.linear_model模块中调用了LinearRegression函数。鉴于冗余分析结合了多元回归和主成分分析,这似乎是恰当的。当我确保在运行冗余分析之前重新缩放所有变量时,ChatGPT-4o提供了个体冗余分析轴解释的比例值正确,以及物种数据集变异中由环境变量变异解释的比例值正确。ChatGPT-4o还生成了一个不错的屏幕绘图,显示了每个冗余分析轴的惯性,并得出结论说,这个绘图与先前的数字是一致的。
事情开始走向崩溃当我开始要求相关性和距离三重图,显示样本点,物种载荷箭头或标签,以及环境变量的典型系数或双标得分为不同颜色的箭头。这些三重图看起来完全不像在R中使用vegan软件包中的plot.cca()命令生成的三重图。样本点似乎被扭曲了,虽然物种箭头似乎对应于物种标签,但环境变量箭头完全指向错误的方向。有时这可能是由于旋转,或典型系数的符号被交换,这是完全任意的,但在这种情况下似乎并非如此。这些差异导致了各种各样的问题,识别哪些样本与其他样本最相似(或不同),尽管ChatGPT-4o能够从物种载荷(标签)的欧氏距离再次选择出哪些物种最相近。然而,在哪些环境变量与哪些冗余分析轴正相关或负相关方面完全错误。这并不是因为它无法解释典型系数或阅读自己的三重图,而是因为与R中vegan软件包的rda()函数获得的典型系数不同。这也导致了识别哪些环境变量与彼此最相关,哪些不相关的类似问题。
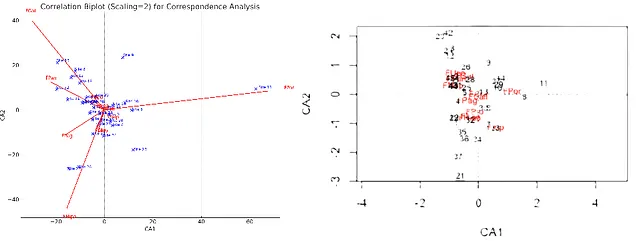
Here's the translation of the provided English text into Simplified Chinese, while keeping the HTML structure intact: ```html Next, I asked ChatGPT-4o to conduct a correspondence analysis of the species dataset, after removing all rows that had zero values for all the species present (samples with no organisms), as the correspondence analysis technique cannot handle that. 下一步,我要求ChatGPT-4o对物种数据集进行对应分析,在此之前删除了所有在所有物种上均为零值的行(即没有生物的样本),因为对应分析技术无法处理这种情况。 ChatGPT-4o decided to use the TruncatedSVD function from the sklearn.decomposition module for this purpose, which conducts Truncated Singular Value Decomposition, which it claimed was similar to Correspondence Analysis. ChatGPT-4o决定使用来自sklearn.decomposition模块的TruncatedSVD函数来完成此任务,该函数进行截断奇异值分解(Truncated Singular Value Decomposition),并声称这与对应分析类似。 However, here already the proportion of variance explained by the correspondence analysis axes did not match those obtained using the cca() function in the vegan package in R. 然而,在这里,对应分析轴所解释的方差比例与使用R中vegan包的cca()函数获得的结果不匹配。 When pressed, ChatGPT-4o acknowledged that it wasn’t actually doing Correspondence Analysis, and attempted to do that by calculating row and column profiles, and running singular value decomposition on the chi-square residuals matrix. 在被追问后,ChatGPT-4o承认它实际上并没有进行对应分析,而是尝试通过计算行和列的轮廓,以及对卡方残差矩阵进行奇异值分解来实现这一点。 The proportion of variance explained by the correspondence analysis axes were closer, but not identical to those obtained in R. 虽然对应分析轴所解释的方差比例更接近,但仍与R中获得的结果不完全相同。 ChatGPT-4o correctly concluded that the cumulative proportion of variance explained by the first two axes (57.42%) would be insufficient to solely rely on these two axes for interpretation. ChatGPT-4o正确地得出结论:前两个轴所解释的方差的累计比例(57.42%)不足以仅依赖这两个轴进行解释。 When asked if Python has dedicated libraries to run correspondence analysis, ChatGPT-4o suggested using the prince library, but it did not have access to this library. 当被问及Python是否有专门的库来进行对应分析时,ChatGPT-4o建议使用prince库,但它无法访问该库。 It was able to generate a screeplot that was qualitatively similar to the one created in R, but the inertia values were off by like 5 magnitudes. 它能够生成一个与R中创建的碎石图(screeplot)在质量上相似的图形,但惯性值相差大约5个数量级。 ChatGPT-4o was able to correctly assess that this screeplot supported the same conclusion about needing more than two axes for interpretation. ChatGPT-4o能够正确地评估出该碎石图支持需要超过两个轴进行解释的相同结论。 ``` This translation keeps the technical and scientific terms consistent, while ensuring that the content is accurate and understandable in Simplified Chinese. Let me know if you need any further adjustments!
当我要求ChatGPT-4o创建一个双标图,以显示样本为点,物种为标签或箭头时,所得到的图与R中vegan软件包中plot.cca()命令生成的图不相似,无论是相关性还是距离双标图。虽然一些样本具有正确的模式,但并非所有样本都如此,这可能是由于原始标签或在去除具有缺失值或没有生物体的站点后的顺序造成的。物种标签的位置和方向也与使用R获得的不同,但存在一些定性的一致性。查看行和列分数时,它们与在R中获得的分数具有定性一致性,但它们的比例不同。ChatGPT-4o拒绝生成同时根据特征值的平方根对物种和样本进行缩放的图,称这不是一个标准方法,尽管plot.cca()有一个scaling=3的选项。尽管存在这些问题,它能够准确识别哪些物种与哪些对应分析轴正相关或负相关。但它无法正确识别哪个样本与特定样本最相似,或哪个物种与其他物种最相似(或最不相似)。
```html
最后,我让 ChatGPT-4o 进行规范对应分析,以评估在同一样本中,所描述的物种数据集中的变异百分比可以通过环境数据集中的变异来解释。由于一些环境变量缺失值,我们不得不将这些行从物种和环境数据集中删除。在开始时,似乎 ChatGPT-4o 遵循了请求,并在 sklearn.cross_decomposition 模块中使用 CCA 函数编写了代码,打印出关于执行规范对应分析的注释,并生成物种和环境得分。然而,由规范对应轴解释的方差百分比与使用 R 中的 vegan 包的 cca() 函数获得的结果相差很大,而且要小得多。此外,环境数据集中的变异解释的物种数据集中的方差比例非常微小(0.0023%),而在 R 中获得的比例为 54.88%,这也与约束的惯性和总惯性的比率一致。碎石图看起来异常奇怪,后面的轴解释的总方差比例大于前面的轴。当我要求它创建一个相关性和距离三维图,显示样本为点,物种为标签,环境变量为箭头时,生成的图形与 R 的 vegan 包中的 plot.cca() 生成的图形完全不同。基于此,当 ChatGPT-4o 尝试回答有关哪些样本或物种彼此更相似或较不相似、哪些环境变量与两个规范对应分析轴的正相关或负相关,或哪些环境变量彼此关系密切的问题时,表现不佳。
```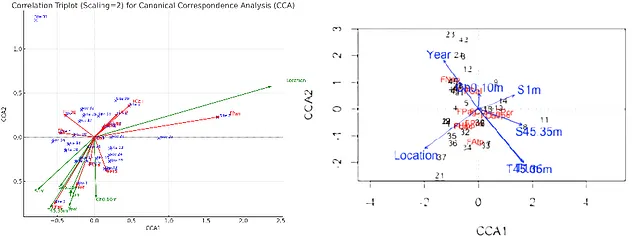
之后,当询问为什么ChatGPT-4o没有使用相同的CCA函数来运行对应分析时,我明白了其中的区别。显然,它使用的CCA函数并不是在进行典型对应分析(Canonical Correspondence Analysis),而是进行典型相关分析(Canonical Correlation Analysis)!这两种方法非常不同,但缩写却相同!典型相关分析是一种线性回归技术,用于找出两个数据集之间的相关性,而实际的典型对应分析是利用种类和环境之间残差卡方距离的奇异值分解。难怪结果会不同!不幸的是,根据ChatGPT-4o的说法,Python中没有直接的函数可以复制R中vegan软件包中的cca()函数的功能,它建议使用各种手动解决方案,但我并不信任。
当被要求比较主成分分析(PCA)和对应分析得到的结果,以及冗余分析和规范对应分析得到的结果时,ChatGPT-4o能够正确地比较和对比不同的方法,并讨论它们的基本假设,尽管它错误地声称PCA假设正态分布。它甚至制作了一个方便的假设表。它正确选择规范对应分析作为这个特定数据集的最合适选择,考虑到它的生态性质以及PCA的线性假设可能被违反。然而,在PCA/RDA双图中,它未能检测到马蹄形或拱形效应,尽管所有物种与第一主分量/冗余分析轴呈正相关,并且样本被排列成一种“楔形”状。当要求推荐替代分析时,它正确推荐非度量多维缩放作为首选,但列出了一堆其他选择(如GAMs),这些选择不太相关。
总的来说,我在使用ChatGPT-4o运行这些多元技术方面取得了有限的成功。它能够相当不错地运行和解释PCA,除了在解释其自身结果时会感到困惑,无法确定哪些物种与哪些轴正面或负面相关。在运行冗余分析时,它能够找到一个合理地复制R中结果的技术,但由于生成的规范系数是错误的,这破坏了解释,我也难以始终获得相同的结果。我还能够让ChatGPT-4o手动提出一个半合理的方法来运行对应分析,结果与R中获得的结果接近但并非完全相同。双标图与R中生成的图不相似,但在某些定性结果上有所复制。最后,规范对应分析是彻底失败的,应用了一个类似拼写的不合适方法,生成了无用且可能误导的结果。然而,像往常一样,ChatGPT-4o在解释(有时不正确的)结果方面大多正确,也有一些例外。因此,根据这个实验,我只建议使用ChatGPT-4o运行PCA,并仔细检查解释,而不是尝试其他技术。
下周,我们将看到ChatGPT-4o能够如何运行MANOVA、线性判别分析以及相关的分类技术。