使用DeepSpeed和FSDP结合Accelerate——第1部分
一个全面指南到DeepSpeed和完全碎片化数据并行(FSDP)与Hugging Face Accelerate,用于高效训练大型语言模型(LLMs)。学习如何利用先进技术和工具来优化性能和可伸缩性,训练最先进的AI模型。

为什么我们需要 Accelerate? Accelerate 是建立在 PyTorch 分布式框架之上的包装库。它简化了完全分片数据并行 (FSDP) 和 DeepSpeed 在训练过程中的集成,使用户更容易利用这些强大的工具。
使用Accelerate会让我的训练运行更快吗?Accelerate帮助您利用多GPU设置,训练速度受多种因素影响 - 使用的GPU数量,分片算法类型,卸载策略等。
应该使用FSDP还是DeepSpeed?要回答这个问题,我们需要深入研究它们的工作原理,并确定最适合您使用情况的算法。
在这个第一部分中,我将介绍并行概念,帮助您了解各种DeepSpeed零配置和加速器中可用的各种选项。
并行的类型:
1. 数据并行:将数据分布在多个GPU或计算机上。每个进程(GPU)在数据的子集上进行训练,同时拥有模型的完整副本。在这里,每个进程将托管模型的副本,并且每个进程将使用不同的数据子集。
这种配置在你有多个GPU时是理想的,而你的模型(LLM)足够小可以适应单个GPU。我想把它看作是用更大的批量大小进行训练。数据并行通常是训练模型的最快方式。
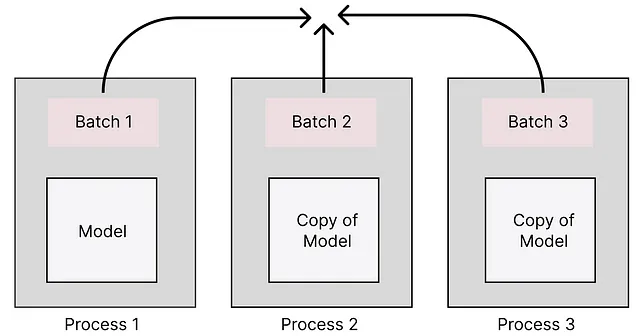
2. 模型并行:将模型分成多个 GPU 或机器。每个进程(GPU)将保存模型的一个顺序部分。在这种情况下,每次训练步骤仅使用一批数据。以下是以最简单形式展示的模型并行的示例。
这种配置在您有多个GPU并且您的LLM不能加载到单个GPU时非常理想。模型并行通常是最慢的选择,因为一次只处理一批数据。
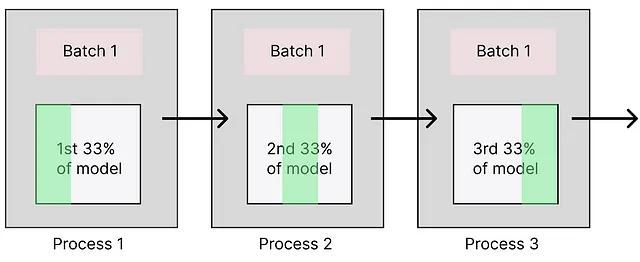
3. 管道并行性:管道并行性类似于模型并行性,但不同之处在于不是按批次依次处理,而是根据阶段划分模型,允许每个进程持有一个独特的阶段。这意味着批次的不同部分可以在不同进程之间同时处理(即:分片发生在层内),从而更有效地利用资源。
这种配置可在您拥有多个GPU且无法将LLM加载到单个GPU时使用。在这种情况下,您无法访问模型的层,因为它们被分散到多个处理过程中,需要先合并。管道并行比模型并行快,但比数据并行慢。
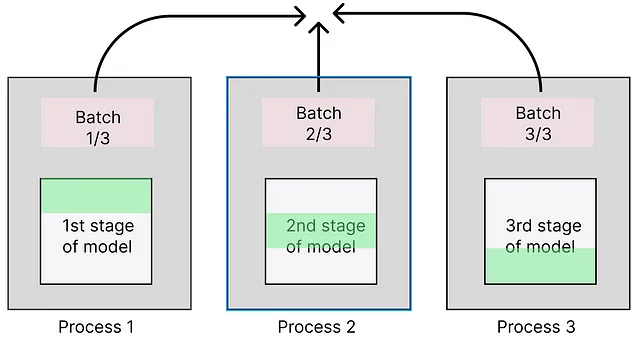
也有其他可用的并行组合(混合并行)。
加速配制
Accelerate提供交互式的QA菜单来设置您的理想配置文件。您可以使用以下命令开始此菜单:
accelerate config
Q1. 您正在哪个计算环境中运行?您可以选择是在本地机器上设置训练,还是在AWS环境中进行。为简单起见,让我们专注于本地环境。
Q2. 你正在使用哪种类型的机器?在这个下拉列表中,你可以指定你所拥有的系统类型。如果你在使用带有GPU的环境进行训练,则相关选项如下:
- 不进行分布式训练 - 如果您选择此选项,训练将仅使用主进程完成。
- 多 GPU — 正如其名称所示,将使用多个 GPU 进行训练。
Q3. 您将使用多少不同的机器(多节点训练时使用多个)?您可以在这里指出您的训练中涉及多少台机器。机器是具有一个或多个GPU的计算单元。如果您使用多台机器,请确保它们彼此联网(例如:对于NVIDIA GPU,请使用NVLink)。
Q4:在运行过程中应该检查分布式操作以查找错误吗?这样可以避免超时问题,但会变得更慢。启用此选项允许加速器在训练运行期间检查错误(超时、通信和硬件)。虽然这可以帮助您避免超时问题,但可能会减慢训练过程。您可以选择“否”以进行简化的训练运行,而不进行错误检查。
Q5. 您是否希望通过torch dynamo来优化您的脚本?使用PyTorch Dynamo后端进行加速编译您的代码,加快复杂模型的训练和推理速度。但是,Dynamo可能会使调试变得复杂。为了避免问题,开始训练时禁用Dynamo以确保一切正常运行,然后在确认稳定性后启用Dynamo重新启动。
火炬编译器解释了为您的任务使用哪个后端。
Q6. 您是否想要使用DeepSpeed / FullyShardedDataParallel / Megatron-LM?通过选择此选项,您可以为您的训练启用所选的引擎。我们稍后将深入研究它们的配置。
Q7. 您想启用NUMA效率吗?如果每个节点有2个或更多个CPU,此选项将增强效率。
Q8。您是否希望使用混合精度?尽可能使用混合精度,因为它可以显著减少 GPU 内存的使用。请注意,NVIDIA V100 不支持 BF16,所以在这种情况下只能选择使用 FP16。深入了解混合精度训练。
计算内存要求
计算为特定任务训练大型语言模型(LLM)所需的确切内存可能具有一定挑战性。但我们可以对所需内存进行估计。这篇文章解释了不同训练流程(完全微调与部分微调)的近似内存需求。
内存需求可以分为两个主要类别:加载模型和激活。
加载模型:一个模型由三个部分组成——参数、梯度和优化器状态。请注意,如果我们启用混合精度,精度和优化器的精度不会相同。
使用AdamW优化器时,每个模型参数都由两个组件(动量和速度)组成。由于我们正在使用混合精度,为了优化器状态计算,需要在完整精度(FP32)下保存模型权重的副本。
param = 模型大小 * 精度grad = 模型大小 * 精度optim = 3 * 模型大小 * 优化精度
mem_req = 参数 + 梯度 + 优化
假设我们将启用混合精度(BF16 / FP16),精度将为16位(2字节),优化精度将为32位(4字节)。
mem_req = (2*model_size) + (2*model_size) + (3*model_size*4)
内存需求 = 14 * 模型大小
DeepSpeed 深速
DeepSpeed是一种混合方法,结合了模型和数据并行,使其成为通过其ZeRO优化器进行多GPU训练的强大引擎。您可以在加速中使用交互式菜单激活DeepSpeed。
DeepSpeed 使用 ZeRO(Zero Redundancy Optimizer)作为其优化引擎。ZeRO 通过将模型的状态 — 参数、梯度和优化器 — 进行分片,使得可以在 GPU、CPU 或硬盘之间进行训练大型模型。它由四个阶段组成,每个阶段都提供不同级别的优化。
阶段0:
ZeRO优化器的Stage 0实现了普通的数据并行。如果您的模型、优化器和激活函数可以适应单个GPU,那么在Accelerate中使用标准数据并行比使用DeepSpeed或完全分片数据并行(FSDP)更有效。
这里是在Accelerate中的数据并行配置示例:
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: allya
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
第一阶段:
ZeRO优化器的第一阶段是一种混合方法,结合了数据并行和半模型并行。在这里,仅优化器状态的权重分片存储在GPU上。每个GPU将持有优化器状态的一部分,在训练过程中,每个GPU仅更新自己的分区。
以下是 Accelerate 中 Stage 1 DeepSpeed 配置的示例:
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 4
zero3_init_flag: false
zero_stage: 1
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
阶段2:
类似于ZeRO优化器的第1阶段,第2阶段在GPU之间分配模型参数的32位梯度。此外,第2阶段提供了将模型参数的优化器状态和梯度从GPU转移至CPU或磁盘的选项。
请记住,卸载优化器状态/参数会导致训练速度减慢,因为访问系统内存会有延迟。
Q:卸载优化器状态与卸载模型参数的梯度?哪个更快?一般来说,卸载优化器状态会比卸载模型参数更快地训练速度稍微快一点,因为梯度只在反向传播过程中需要。
Q. 您需要多少次梯度累积步骤?在训练较大的模型时,在资源受限环境中保持较高的批次大小可能具有挑战性。梯度累积步骤允许您通过每n步计算梯度来模拟较大的有效批次大小。
有效批次大小可以通过以下方式计算:
有效批次大小 = 梯度累积步数 * 批次大小
需要启用渐变截断吗?渐变截断通常用于解决梯度爆炸或不稳定的训练损失。DeepSpeed 在幕后使用最大梯度范数来进行梯度截断。
需要启用Deepspeed.zero.Init吗?Deepspeed使用zero.Init来以高效的方式初始化大模型,这将提高内存管理和动态内存分配效率。请参考本文获取详细信息。
Q. 您要启用专家混合训练吗?如果您计划训练一个专家混合模型,强烈建议使用DeepSpeed MoE,因为它通过避免将基础模型在所有GPU上复制来减少内存使用量。DeepSpeed MoE还支持训练非常大的模型,例如Switch Transformers。请参考微软的这篇文章以获取详细报告。
以下是在加速器中的Stage 2 DeepSpeed配置示例:
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 4
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
阶段三:
在第三阶段——优化器、梯度和模型参数分布在多个GPU/Data Parallel工作器上。加速器在第3阶段的设置与第2阶段类似,但包括以下问题。
Q. 使用ZeRO阶段-3时,您想要保存16位模型权重吗?启用此选项将导致检查点以16位精度保存。这种方法的优势是检查点文件占用的磁盘空间更少。但是,可能会导致性能损失(特定情况)和较慢的训练速度,因为每次保存检查点时都必须进行模型整合。
这是在Accelerate中一个阶段3的DeepSpeed配置示例:
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 1
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
一旦设置适当的DeepSpeed(加速)配置,训练可以通过简单的命令开始。
accelerate launch <your_training_file.py>
结论
在这个博客中,我们讨论了各种类型的并行性——数据、模型和管道,并且用户可以根据自己的特定需求和硬件配置来优化他们的训练策略。在加速中的交互式配置菜单简化了设置过程。
正如我们在第一部分中探讨的那样,建立一个有效的训练环境需要仔细考虑因素,比如梯度累积步骤和优化器状态。在继续这个系列时,我们将更深入地探讨优化训练配置的复杂细节,确保您可以充分发挥多GPU设置的潜力,实现稳健高效的LLM训练。
请继续关注第二部分,我们将讨论FSDP的世界!







