大型语言模型实践:全面评估
简介
通过使机器能更好地理解和生成类似人类语言,LLMs在人工智能领域开辟了新的可能性,并影响了整个行业。
这篇由杰伊·阿拉玛和马尔滕·格鲁滕多斯特撰写的《大型语言模型实战》开篇语热身,为我们深入探讨当今最具变革性技术之一铺平道路。随着人工智能的不断发展,大型语言模型(LLMs)站在最前沿,彻底改变了我们与机器的互动方式,信息处理方式,甚至对语言本身的理解。

大型语言模型实用指南既是开发人员、数据科学家和人工智能爱好者的指南,又是工具包,旨在帮助他们理解、实施和创新LLMs。无论您是经验丰富的人工智能实践者,希望深入了解知识,还是初学者,渴望深入了解语言模型的世界,本书提供了理论和实践应用的独特融合。随着ChatGPT和GitHub Copilot等工具的影响力不断扩大,本书作为一个重要资源脱颖而出,帮助理解和应用这些强大工具在实际场景中的运用。
让我们深入探讨,探索这本书是如何成为一份宝贵的资源的。
目标受众
✅ 硕士法学专业人士
机器学习工程师、数据科学家、软件工程师和数据工程师在积极使用LLMs的情况下,会发现这本书是必不可少的宝库,其中包含了实现基于LLM应用所需的工具和知识。
✅ 人工智能爱好者
具有对机器学习基础知识的理解并对LLMs感兴趣的个人将发现大量信息来探索LLMs的能力和应用,即使他们没有特定的使用案例。
⚠️ 机器学习的完全初学者
缺乏机器学习概念先验知识的读者可能会觉得内容有些困难。作者假设读者熟悉模型训练、验证和评估等基本主题。对于从零开始的人来说,建议先探索入门资源来建立基础。
提示:《百页机器学习书》是一个推荐的起点,它在深入探讨语言模型的复杂性之前,提供了关键概念的简明概述。
什么让这本书脱颖而出
1. 语言模型的综合概述
第1章提供了对语言模型内部工作原理的高层次摘要,而第2章和第3章进一步解释了这些概念。作者巧妙地使用图表、插图和代码示例来解释诸如标记化、嵌入、变压器模型和注意机制等复杂主题。
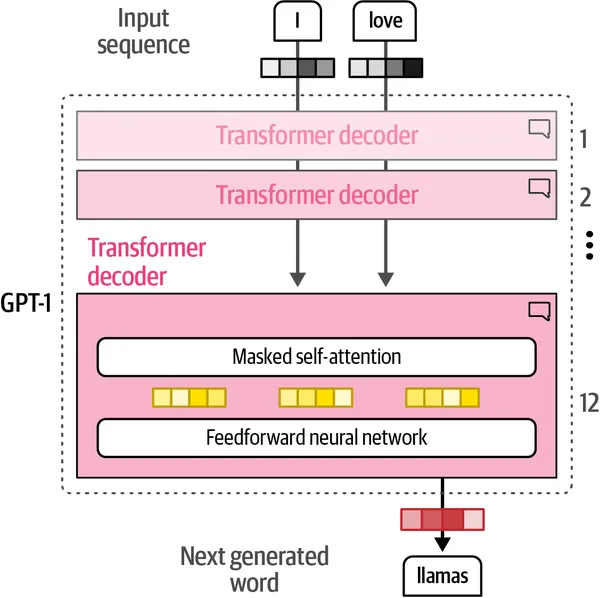
阅读建议:虽然第1章的概述可能会引起有机器学习背景的人的共鸣,但对其他人来说可能会有些困惑。如果您发现这一部分有挑战性,考虑略读一下;大多数细节在第2章和第3章中有更深入的阐述。
2. 嵌入模型的适用性
几乎不可能过分强调将模型嵌入到领域中的重要性,因为它们是许多应用程序背后的驱动力。
来自软件工程背景,我之前并不知道嵌入模型。然而,阅读了这本书之后,我惊讶地发现,嵌入模型除了用于生成任务外,还具有捕捉文本语义本质的能力,非常强大。
文本分类在各种应用中被使用,包括情感分析、意图检测、实体提取和语言检测。许多人将LLMs仅与生成式任务联系在一起,或尝试使用像ChatGPT这样的模型进行分类 - 通常通过零样本或一次性提示达到混合结果。第四章探讨了使用开源嵌入式模型进行分类的创新解决方案,这些解决方案不需要昂贵的微调或GPU培训。这些解决方案可以与通用模型一起使用,甚至可以处理未标记的数据。在没有标记数据的情况下执行多类别分类的能力特别引人入胜,并开辟了许多用例。
文本聚类是另一个嵌入模型发光的领域,可以实现创意解决方案,例如识别异常值,加速标注过程,并帮助在大型文本数据集(主题建模)中揭示抽象主题。虽然许多人最初可能不会将LLMs与聚类任务联系起来,但第5章很好地说明了嵌入模型如何有效地应用于处理这些挑战,使用HDBSCAN和BERTopic等技术。
3. 提示工程学
没有涉及即时语言模型(LLMs)的讨论是不完整的,而本书也不例外。即使您不是在开发带有LLMs的应用程序,而只是使用类似ChatGPT这样的工具来完成日常任务,第6章也是必读之处。提示在您从这些模型中获得的结果中起着至关重要的作用。
个人备忘录:虽然我对很多与提示工程相关的概念都很熟悉,“思维树”技术对我来说是新颖而富有洞察力的。这种方法通过一个简单的提示模板,使模型能够深入探讨多个想法!
4. 检索辅助生成(RAG)
类似于prompt engineering,检索增强生成(RAG)是与LLMs相关的另一个热门话题。RAG代表LLMs最具影响力的应用之一,被广泛采用于公司创建“与我的数据交谈”机器人,减少产出的幻觉并增强事实准确性。第8章清晰易懂地解释了RAG。
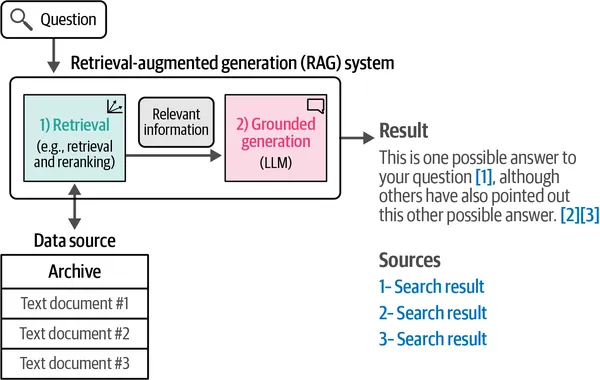
个人笔记:虽然我已经熟悉RAG并且之前使用过它,但“高级RAG技术”部分提供了改进这些系统的宝贵见解。该章节还讨论了评估RAG系统的挑战,我觉得特别有用。
5. LangChain介绍
在通过代码与LLM工作时,LangChain是最广泛采用的框架。它简化了工作流程,减少了基于LLM的应用程序的开发时间。第七章提供了对LangChain的深入介绍,涵盖了其入门所需的基本功能。对于领域新手来说,代理的概念无疑会引起您的兴趣,展示LLM提供的广泛可能性。这一章对于任何希望使用LLM开发应用程序的人来说都是必读的!
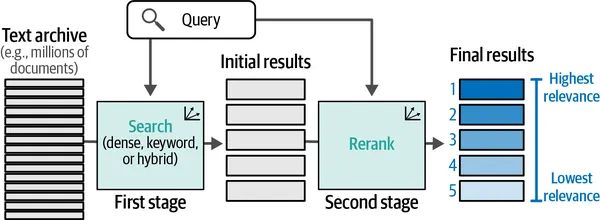
6. 在搜索引擎中应用LLMs
搜索引擎是最早采用大规模语言模型的应用之一。第8章深入探讨了语义搜索,展示了像谷歌和必应这样的主要搜索引擎如何利用LLMs进行一种称为重新排名的优化技术,从而显著改进搜索结果。我发现这部分内容非常有趣!
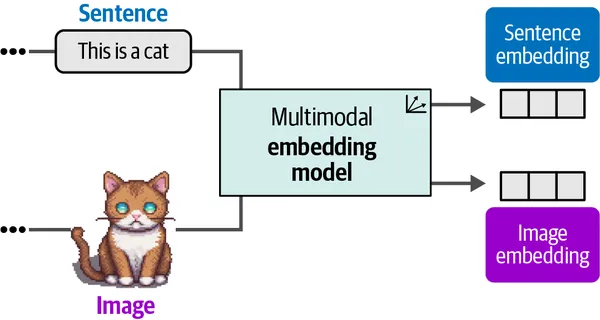
7. 多模型LLMs
第9章着重于多模态LLM,它将LLM功能与图像集成在一起。它精美地解释了如何利用这些功能来构建更强大的应用程序,这些应用程序可以从图像中获取语义见解。
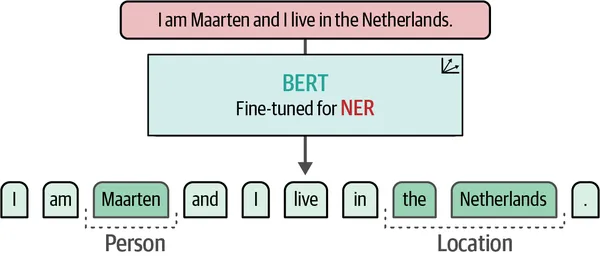
8. 命名实体识别(NER)
命名实体识别(NER)是本书涵盖的另一个引人入胜的主题。 这一过程允许对单个标记或单词进行分类 - 例如人和地点 - 而不是整个文档。 NER 对于涉及敏感数据的去标识化和匿名化任务特别有帮助。
9. 为自定义用例培训和微调LLMs
这一部分是我急切期待的;将LLMs调整到特定的使用情况中突显了它们的灵活性和广泛应用。第10至12章集中讨论了嵌入和生成模型在这一主题上的应用。
我发现第10章探讨如何使用增强的SBERT来调整模型与有限数据,并介绍了无监督训练的TSDAE是多么有趣。在无法获取大型、完全标记的数据集的情况下,这些方法是非常宝贵的。
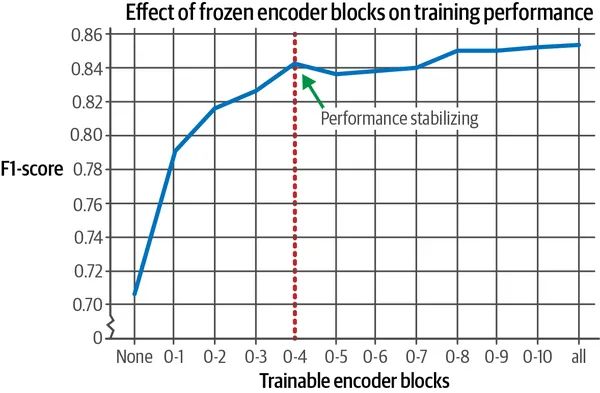
第11章超越了对分类模型进行微调;它提供了有关根据计算容量有选择地微调层的见解。对微调一些层和所有层的分析在资源或培训时间有限时提供了实用的权衡。
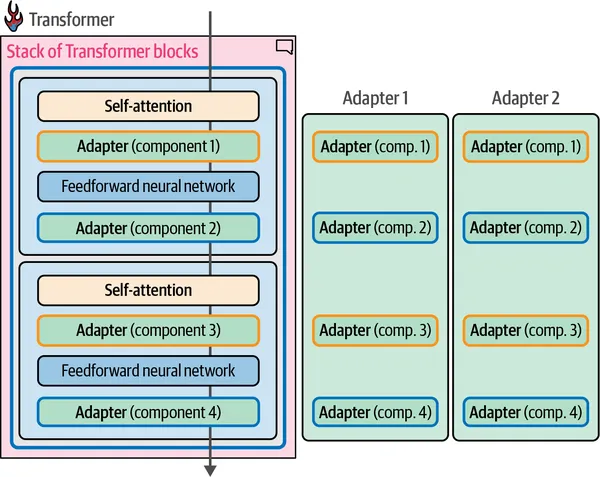
第12章介紹了Adapter的概念,為每個下游任務提供了一種不需要完全微調模型的替代方案。這種方法與“構建可組合軟件”的理念完全契合,這是我們作為工程師始終努力實現的目標。此外,探索量化以提高訓練效率結合了數學原理與計算機科學概念,突出了模型優化中的創新策略。
什么可能会更好
尽管大部分书籍都非常有信息量,但有几个地方可以从改进中受益:
- 需要机器学习专业知识的部分: 第1章中LLM工作原理的概述,关于“使文本生成模型多模式化”的部分,以及第10章的某些部分可能对没有机器学习专业知识的读者构成挑战。提供更清晰的解释或补充资源将增进更广泛受众的理解。
- 缺乏对LLM应用生产化挑战的讨论:尽管该书涵盖了许多与LLM合作的方面,但在解决生产化这些应用程序的实际挑战方面仍有不足。诸如可伸缩性、部署策略以及维护LLM系统的实际考虑等主题,对于那些希望在生产环境中应用这些技术的读者来说,将会增加显著的价值。
- 多模LLMs的有限讨论:第9章介绍了多模LLMs,讨论主要集中在使用图像进行嵌入和问题回答。我很想深入了解涉及图像生成任务的扩散模型,尤其是那些支持Adobe Firefly和Midjourney等工具的模型。
最后的想法
大型语言模型(LLMs)在世界上产生了深远而广泛的影响。
对于任何希望深入学习LLMs领域或加深对该领域及其应用的理解的人来说,亲手试验的大型语言模型是一本必读的书籍。通过清晰的解释,全面的图表和实例代码,这本书使得即使是最复杂的概念也变得易于理解和可操作。同时,引用公开可获取的论文进一步丰富了学习体验,鼓励读者更深入地探索相关主题。
随着人工智能领域的不断发展,理解和操作LLM(大型语言模型)的能力变得至关重要。这本书不仅教授基础知识,还让你能够应对真实世界的挑战。无论你是机器学习从业者、软件工程师还是人工智能爱好者,这本书都提供了你在这个快速发展领域立于不败的工具和见解。
在一个适应性和知识至关重要的世界中,这本书是掌握人工智能最激动人心领域之一的入口。踏入其中,拥抱旅程 — 快乐学习!
跟随DevReads获取更多来自科技文学世界的重要书籍和白皮书的评论。