谷歌的Gemini-Exp-1114:新的最佳LLM
超越GPT-4.0,Claude3.5 Sonnet和Gemini 1.5在LMArena。
最终,OpenAI 已被打败,最新的、最好的LLM昨天由谷歌发布,在他们的实验系列中,Gemini-exp-1114夺得桂冠。
Gemini-exp-1114在LLM排名中荣登LMArena榜首,如下图所示。
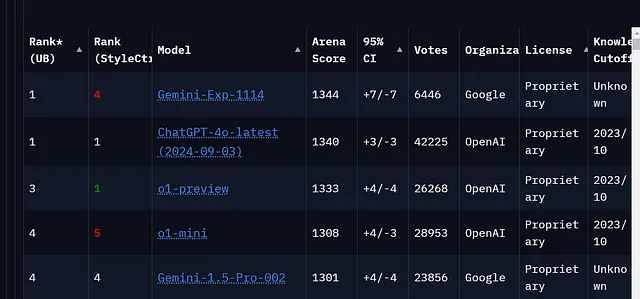
OpenAI已经在这个榜单上长期占据统治地位,因此,取代GPT-4o是一件大事。
什么是LMArena?
Lmarena,或聊天机器人竞技场,是一个旨在评估大型语言模型(LLMs)的开源平台。由LMSYS和加州大学伯克利分校SkyLab成员开发,其主要目标是通过实时评估和成对比较促进社区驱动的LLM性能评估。
了解排行榜
1. 等级 (UB和StyleCtrl):
等级(UB)是基于模型在各种任务中的表现而确定的,没有特定风格控制。
排名(StyleCtrl)表示模型在考虑“风格控制”时的排名,这指的是模型根据提示调整其回复的能力,例如语调、形式等。
Gemini-Exp-1114在样式控制方面排名第4,而ChatGPT-4.0排名第1,表明ChatGPT在样式调整方面表现更好。
2. 竞技场得分: 竞技场得分(例如,双子座为1344,ChatGPT为1340)反映了模型在不同任务上的平均表现分数,可能涉及各种语言理解和生成的基准测试。得分越高,整体表现越好。
在这里,Gemini-Exp-1114的分数稍高一些(1344比1340),使其在总体排名上领先于ChatGPT-4.0。
3. 95%置信区间(Confidence Interval):这显示了95%置信度下模型得分的变化范围。对于Gemini来说,范围是±7,对于ChatGPT来说是±3。较小的置信区间表明性能更加稳定,因此ChatGPT-4.0在得分方面稍微更加稳定,尽管Gemini的平均得分稍微更高。
4. 票数:该列显示每个模型在LMArena上收到的投票或评价数量。ChatGPT-4.0收到了42,225票,远远多于Gemini-Exp-1114,后者只有6,446票。更高的得票数有时可以表明更可靠或经过更广泛使用和评估的结果。
什么是双子座实验模型?
正如其名字所示,这是一系列实验性模型。实验模型主要发布用于收集反馈意见,并让开发人员快速获取最新进展。它们突显了谷歌在人工智能技术方面不断进行的创新。
此外, 实验模型可能随时被另一个模型替换,恕不另行通知。我们不能保证实验模型将来会过渡成一个稳定模型。因此,在生产中应该避免使用。
如何免费使用Gemini-Exp-1114?
- 只需转到Google AI Studio并登录(免费)。
- 前往创建提示
- 從設置更改模型為Gemini Experimental 1114
- 开始聊天
结论
尽管数字庞大,但这仍然处于早期阶段,因为这是一个实验性模型,我们应该等待最终画面。但是,是的,听起来很令人兴奋,看到一些激烈的竞争也很棒。当这个模型变得稳定并发布时,将是一种享受。