📈使用Kafka和LlamaIndex构建AI实时交易系统

这个教程演示如何使用Kafka构建一个实时交易机器人来流处理EUR/USD数据,使用LlamaIndex工作流来无缝处理逻辑,以及使用GPT-4o进行图像分析。GPT-3.5整合所有信息来制定购买、出售或持有决策,包括每个选择背后的推理。这个设置为一个先进的AI交易系统提供了强大的基础,未来有潜力根据投资金额协调重新平衡。
注意: 在Google Colab上运行Kafka并不适合用于生产级实时应用程序。Kafka通常在专用服务器上运行,以避免数据流中断并优化性能。然而,Colab非常适合原型设计和学习。
Github: 🔗https://github.com/hecboar/MediumArticles/blob/main/Medium_EffortlessPressArticleGeneration.ipynb GitHub:🔗https://github.com/hecboar/MediumArticles/blob/main/Medium_EffortlessPressArticleGeneration.ipynb
Here is the translated text while keeping the HTML structure: ```html 1) 下载EUR/USD每日图像 ```
```html
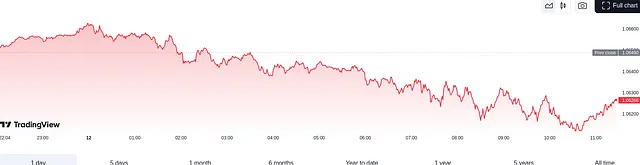
我们首先使用Selenium下载每日EUR/USD图像图表,Selenium是一个常用于网络抓取的工具。此图像将由GPT-4处理,以获取初步见解,这些见解将指导我们的交易机器人。
``````html
注意:在 Google Colab 上运行 Kafka 并不适合生产环境;Kafka 通常在专用服务器或虚拟机上运行效果最佳,因为它需要保持一致的正常运行时间和可靠的数据流。
```代码解释
- 功能initialize_web_driver:设置一个Chrome WebDriver用于下载每日的EUR/USD图表。
- Here is the translated text while keeping the HTML structure: ```html Image Capture: 捕获并保存EUR/USD图表的截图,该图表将由GPT-4o进行分析。 ```
!pip install selenium
!apt-get install chromium-driver
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
def initialize_web_driver():
"""Sets up and returns a configured Chrome WebDriver instance."""
options = webdriver.ChromeOptions()
options.add_argument('--verbose')
options.add_argument('--no-sandbox')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=1920,1200')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(options=options)
return driver
driver = initialize_web_driver()
try:
# Navigate to the page
driver.get("https://www.tradingview.com/symbols/EURUSD/")
# Wait a few seconds for the page to load fully
time.sleep(4) # Adjust sleep duration if necessary
driver.refresh()
time.sleep(4)
# Locate the chart using an appropriate selector
chart_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "container-nORFfEfo"))
)
# Capture a screenshot of the chart element
time.sleep(4)
chart_element.screenshot("eurusd_chart.png")
print("Chart screenshot saved as 'eurusd_chart.png'.")
except Exception as e:
print("An error occurred:", e)
finally:
# Close the browser
driver.quit()
```html
该脚本将为我们提供每日EUR/USD图表的快照:
```
2) Kafka 实时流处理设置
在本节中,我们将建立一个基于Kafka的数据流设置,以跟踪EUR/USD的买卖价格的几乎实时数据。 EURUSD价格的数据源将从知名提供者Investing.com获得。为使该系统正常运行,我们将创建一个Kafka主题,eurusd_bidask,每5秒钟接收新的定价数据。
The core components here are: 核心组件是:
- Kafka 生产者:负责每5秒从服务器获取和发布买卖数据到 eurusd_bidask 主题。
- ```html Kafka Consumer: 实时消费和处理来自Kafka主题的数据,并将其存储以便进一步分析。 ```
这种设置为构建一个动态交易机器人提供了一个理想的起点,通过模拟实时数据流和处理。虽然由于网络请求导致数据稍有延迟,但它为更复杂的交易策略提供了坚实的基础。
#setup kafka configuration
!wget https://downloads.apache.org/kafka/3.8.1/kafka_2.13-3.8.1.tgz
!tar -xzf kafka_2.13-3.8.1.tgz
!./kafka_2.13-3.8.1/bin/zookeeper-server-start.sh -daemon ./kafka_2.13-3.8.1/config/zookeeper.properties
!./kafka_2.13-3.8.1/bin/kafka-server-start.sh -daemon ./kafka_2.13-3.8.1/config/server.properties
!sleep 10
#remove topic
!./kafka_2.13-3.8.1/bin/kafka-topics.sh --delete --topic eurusd_bidask --bootstrap-server localhost:9092
!./kafka_2.13-3.8.1/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic eurusd_bidask
```html 在整合整个工作流程之前,首先让我们测试 eurusd 抓取器,以确保它使用 BeautifulSoup 库每 5 秒获取一次数据。此外,我们还将检查 Kafka 队列是否正常工作,以确保数据流畅无缝。 ```
!pip install kafka-python nest_asyncio
import json
import requests
import time
import pandas as pd
from kafka import KafkaProducer, KafkaConsumer
from bs4 import BeautifulSoup
import asyncio
import nest_asyncio
import threading
# Apply nest_asyncio for environments with an already running event loop (e.g., Jupyter/Colab)
nest_asyncio.apply()
# Control variable to stop the loop
stop_flag = False
# Kafka Producer Configuration
async def kafka_producer():
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
async def fetch_and_send_bid_ask():
url = 'https://www.investing.com/currencies/eur-usd-spreads'
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
# Check if the response is successful
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
bid_element = soup.find("span", class_="inlineblock pid-1-bid")
ask_element = soup.find("span", class_="inlineblock pid-1-ask")
# Check if bid and ask elements were found
if bid_element and ask_element:
bid_value = float(bid_element.text.replace(',', ''))
ask_value = float(ask_element.text.replace(',', ''))
message = {'bid': bid_value, 'ask': ask_value}
# Send message to Kafka
producer.send('eurusd_bidask', value=message)
producer.flush()
print(f"Producer sent bid: {bid_value}, ask: {ask_value}")
else:
print("Error: Could not find bid/ask elements on the page.")
else:
print(f"Error fetching data: Status code {response.status_code}")
# Infinite loop to capture and send data every 5 seconds
while not stop_flag:
await fetch_and_send_bid_ask()
await asyncio.sleep(5)
# Kafka Consumer Configuration
def kafka_consumer_bot():
consumer = KafkaConsumer(
'eurusd_bidask',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda x: json.loads(x.decode('utf-8')),
auto_offset_reset='latest',
enable_auto_commit=False,
group_id='my-group'
)
df = pd.DataFrame(columns=['Bid', 'Ask', 'Mid_Price'], dtype=float)
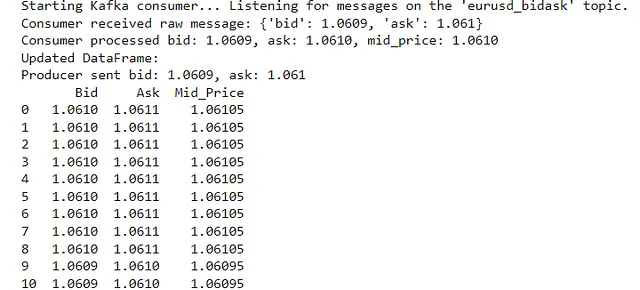
print("Starting Kafka consumer... Listening for messages on the 'eurusd_bidask' topic.")
for msg in consumer:
if stop_flag:
break
# Debug message to show that a message has been received
print(f"Consumer received raw message: {msg.value}")
# Extract bid and ask values
bid = float(msg.value['bid'])
ask = float(msg.value['ask'])
mid_price = (bid + ask) / 2
# Add new row to DataFrame and print the updated DataFrame
new_row = pd.DataFrame({'Bid': [bid], 'Ask': [ask], 'Mid_Price': [mid_price]})
df = pd.concat([df, new_row], ignore_index=True)
print(f"Consumer processed bid: {bid:.4f}, ask: {ask:.4f}, mid_price: {mid_price:.4f}")
print("Updated DataFrame:")
print(df)
# Keep only the last 50 rows
if len(df) > 50:
df = df.iloc[-50:].reset_index(drop=True)
# Small sleep to avoid rapid polling in this example
time.sleep(5)
# Main function to run both producer and consumer
async def main():
# Start the producer in the event loop
producer_task = asyncio.create_task(kafka_producer())
# Start the consumer in a separate thread
consumer_thread = threading.Thread(target=kafka_consumer_bot, daemon=True)
consumer_thread.start()
try:
await producer_task
except asyncio.CancelledError:
pass
finally:
consumer_thread.join()
# Run the main function
try:
asyncio.run(main())
except KeyboardInterrupt:
print("Program terminated by the user.")
```html
提示:在测试期间尝试停止 Kafka 队列时,Colab 笔记本可能会遇到问题。我的建议是重启 Colab,并重新安装和重新导入库。如果您想测试完整的工作流程,请跳过 Kafka 测试,直接进入完整工作流程,确保在第一步安装所有依赖项并获取图像。
```3) LlamaIndex 交易决策工作流
安装必需的库,包括用于工作流程的llama-index,用于与Kafka进行交互的kafka-python,以及用于技术分析的pandas_ta。
# Install necessary packages
!pip install llama-index-core llama-index-llms-openai llama-index-multi-modal-llms-openai
!pip install llama_index.readers.file
!pip install pandas_ta
!pip install kafka-python
```html
LlamaIndex 工作流程是我们机器人逻辑的核心,处理实时数据并根据技术分析和 GPT-4o 图像分析的洞见做出交易决策。这些是代码的主要部分:
```- ```html TradingDecisionResult 类:定义用于存储交易决策和推理的数据结构。 ```
- ```html 图像分析步骤:使用GPT-4分析捕获的EUR/USD图表。此分析的见解指导机器人的初始行为。 ```
- ```html 数据分析步骤:此步骤利用技术指标,如指数移动平均线(EMA)、相对强弱指数(RSI)和布林带,针对实时的买卖数据进行分析。根据这些指标,GPT-3.5 被提示提供一个决策——买入、卖出或持有——并给出选择的理由。 ```
- Sure! Here is the translated text while keeping the HTML structure intact: ```html Stop Command Listener: 监听“停止”命令,在必要时停止程序。 ```
# Install necessary packages
!pip install llama-index-core llama-index-llms-openai llama-index-multi-modal-llms-openai
!pip install llama_index.readers.file
!pip install pandas_ta
!pip install kafka-python
现在,完整的工作流程:
import requests
from bs4 import BeautifulSoup
import json
import pandas as pd
import pandas_ta as ta
import asyncio
import threading
import nest_asyncio
import time
import os
from kafka import KafkaProducer, KafkaConsumer
from llama_index.core.program import LLMTextCompletionProgram
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core import SimpleDirectoryReader
from llama_index.core.workflow import Workflow, step, Event, Context
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.llms.openai import OpenAI
from typing import Optional, Any
# Setup for Colab environment compatibility
nest_asyncio.apply()
# Set OpenAI API key in the environment
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
# Variable de control para detener el bucle
stop_flag = False
def stop_listener():
global stop_flag
while True:
user_input = input("Write 'stop' to stop: ")
if user_input.lower() == 'stop':
stop_flag = True
print("Stopping the program...")
break
# Start a separate thread to listen for stop commands
threading.Thread(target=stop_listener, daemon=True).start()
class TradingDecisionResult(BaseModel):
"""
Model to store the result of trading decisions.
"""
decision: str = Field(description="Trading decision: 'buy', 'sell' o 'hold'.")
reasoning: str = Field(description="Reasoning behind the decision.")
# Initialize Workflow
class InvestmentBotWorkflow(Workflow):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.image_analysis_done = False # Indicator to know if the image analysis has already been done
@step
async def analyze_image(self, ctx: Context, ev: Event) -> None:
# Track if the image analysis has already been completed
if not self.image_analysis_done:
print("Performing image analysis...")
openai_mm_llm = OpenAIMultiModal(
model="gpt-4o", api_key=os.environ["OPENAI_API_KEY"], max_new_tokens=512
)
image_path = "/content/eurusd_chart.png"
image_documents = SimpleDirectoryReader(input_files=[image_path]).load_data()
response = openai_mm_llm.complete(
prompt="Analyze the following EUR/USD (daily) chart. Provide a detailed description of any patterns or trends observed, highlighting key price levels. This comment will support a real-time algorithm capturing bid-ask data every 5 seconds.",
image_documents=image_documents,
)
# Extract response text and save it in the context
response_text = response.text if hasattr(response, "text") else str(response)
await ctx.set("image_analysis", response_text)
self.image_analysis_done = True
print("Image analysis completed: " + response_text)
@step
async def analyze_data(self, ctx: Context, ev: Event) -> None:
"""
Perform data analysis and generate a trading decision based on technical indicators.
"""
df = await ctx.get('df')
if df is None or df.empty:
print("DataFrame 'df' is unavailable or empty.")
return
# Retrieve stored image analysis
image_analysis = await ctx.get("image_analysis", "Image analysis unavailable.")
# Ensure sufficient data for technical indicators
if len(df) < 6:
print("Insufficient data for technical indicators.")
return
# Adjust indicator periods based on available data
ema_period = min(5, len(df))
rsi_period = min(5, len(df))
bb_period = min(5, len(df))
# Calculate technical indicators
df['EMA_5'] = ta.ema(df['Mid_Price'], length=ema_period)
df['RSI'] = ta.rsi(df['Mid_Price'], length=rsi_period)
bb = ta.bbands(df['Mid_Price'], length=bb_period, std=1.5)
if bb is not None and not bb.empty:
# Get the names of the generated columns
bb_columns = bb.columns.tolist()
# Filter the required columns
bbl_column = [col for col in bb_columns if col.startswith('BBL')][0]
bbm_column = [col for col in bb_columns if col.startswith('BBM')][0]
bbu_column = [col for col in bb_columns if col.startswith('BBU')][0]
# Select columns and rename them
bb_selected = bb[[bbl_column, bbm_column, bbu_column]]
bb_selected.columns = ['BBL', 'BBM', 'BBU']
# Concatenate with the original DataFrame
df = pd.concat([df, bb_selected], axis=1)
else:
df['BBL'] = df['BBM'] = df['BBU'] = None
# Get the last 5 prices
last_prices = df['Mid_Price'].tail(5).tolist()
# Get the latest technical indicators
indicators = {}
latest_data = df.iloc[-1]
# Manage possible NaN in the indicators
indicators['EMA_5'] = latest_data.get('EMA_5', 'No disponible')
indicators['RSI'] = latest_data.get('RSI', 'Not available')
indicators['BBL'] = latest_data.get('BBL', 'Not available')
indicators['BBM'] = latest_data.get('BBM', 'Not available')
indicators['BBU'] = latest_data.get('BBU', 'Not available')
for key, value in indicators.items():
if pd.isna(value):
indicators[key] = 'Not available'
# Prepare the prompt for GPT-3
prompt = (
f"Analysis of the latest prices: {last_prices}\n"
f"Latest technical indicators:\n"
f"EMA_5: {indicators['EMA_5']}\n"
f"RSI: {indicators['RSI']}\n"
f"BBL: {indicators['BBL']}\n"
f"BBM: {indicators['BBM']}\n"
f"BBU: {indicators['BBU']}\n\n"
f"EURUSD daily chart analysis:\n{image_analysis}\n\n"
"Based on the above analysis, it provides a trading decision:('buy', 'sell' o 'hold') "
"and explain your reasoning concisely."
)
# Use GPT-3.5 to obtain the decision
try:
llm_gpt3 = OpenAI(model="gpt-3.5-turbo", max_new_tokens=512)
program = LLMTextCompletionProgram.from_defaults(
output_cls=TradingDecisionResult,
prompt_template_str=prompt,
llm=llm_gpt3,
)
trading_decision_result = program()
decision = trading_decision_result.decision
reasoning = trading_decision_result.reasoning
print(f"Trading decision: {decision}")
print(f"Reasoning: {reasoning}")
except Exception as e:
print(f"Error during analysis with GPT-3: {e}")
# Kafka's producer configuration
async def kafka_producer():
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
async def fetch_and_send_bid_ask():
url = 'https://www.investing.com/currencies/eur-usd-spreads'
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
bid_element = soup.find("span", class_="inlineblock pid-1-bid")
ask_element = soup.find("span", class_="inlineblock pid-1-ask")
if bid_element and ask_element:
bid_value = float(bid_element.text.replace(',', ''))
ask_value = float(ask_element.text.replace(',', ''))
message = {'bid': bid_value, 'ask': ask_value}
producer.send('eurusd_bidask', value=message)
producer.flush()
print(f"Producer sent bid: {bid_value}, ask: {ask_value}")
else:
print(f"Error: {response.status_code}")
# Infinite loop to capture and send data every 5 seconds
while not stop_flag:
await fetch_and_send_bid_ask()
await asyncio.sleep(5)
# Kafka's consumer configuration
def kafka_consumer_bot():
consumer = KafkaConsumer(
'eurusd_bidask',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda x: json.loads(x.decode('utf-8')),
auto_offset_reset='latest',
enable_auto_commit=False,
group_id='my-group'
)
df = pd.DataFrame(columns=['Bid', 'Ask', 'Mid_Price'], dtype=float)
# Initialize Workflow
bot_workflow = InvestmentBotWorkflow()
context = Context(workflow=bot_workflow)
# Performing image analysis before starting the loop
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(bot_workflow.analyze_image(context, Event()))
loop.close()
# Variable to control the start time
data_collection_start_time = time.time()
data_collection_duration = 30
for msg in consumer:
if stop_flag:
break
bid = float(msg.value['bid'])
ask = float(msg.value['ask'])
mid_price = (bid + ask) / 2
new_row = pd.DataFrame({'Bid': [bid], 'Ask': [ask], 'Mid_Price': [mid_price]})
df = pd.concat([df, new_row], ignore_index=True)
print(f"Consumer received bid: {bid:.4f}, ask: {ask:.4f}, mid_price: {mid_price:.4f}")
print(df)
# Hold only the last 50 rows
if len(df) > 50:
df = df.iloc[-50:].reset_index(drop=True)
# Wait until sufficient data is available
if time.time() - data_collection_start_time < data_collection_duration:
print("Collecting data... Waiting to start the analysis.")
time.sleep(5)
continue # Do not run the analysis until you have sufficient data
# Perform analysis every 30 seconds
if len(df) > 4: # Ensure that you have sufficient data for indicators
# Pass the DataFrame to the context and run the analysis.
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(context.set('df', df.copy()))
loop.run_until_complete(bot_workflow.analyze_data(context, Event()))
loop.close()
# Reset timer for next analysis
data_collection_start_time = time.time()
else:
print("Not enough data for analysis")
time.sleep(5)
# Execute producer and consumer together
def main():
# Execute the producer in the event loop
loop = asyncio.get_event_loop()
producer_task = loop.create_task(kafka_producer())
# Start the consumer in a separate thread
consumer_thread = threading.Thread(target=kafka_consumer_bot, daemon=True)
consumer_thread.start()
try:
loop.run_until_complete(producer_task)
except asyncio.CancelledError:
pass
finally:
loop.close()
consumer_thread.join()
# Runs the main process
try:
main()
except KeyboardInterrupt:
print("Program completed by the user.")


在编程世界中,管理库的版本非常重要,因为随着时间推移,兼容性问题和弃用函数可能会出现。为了解决这个问题,我们使用pip freeze和pip show来显示在本教程中使用的所有库,确保版本和依赖关系的透明度。
!pip freeze
!pip show selenium
!pip show llama-index-core
!pip show llama-index-llms-openai
!pip show llama-index-multi-modal-llms-openai
!pip show llama_index.readers.file
!pip show pandas_ta
!pip show kafka-python
未来扩张 — 投资再平衡
```html
在未来的教程中,我们将添加一个功能,根据机器人生成的交易推荐动态调整投资金额。此增强功能将使机器人更具适应性和对市场趋势的响应能力,从而实现更具战略性和高效的决策。
```值得注意的是,在目前的环境中运行这个机器人存在一些限制,特别是在Colab笔记本设置中。例如,用于获取买入和卖出价格的网络请求可能会出现延迟,甚至由于网络延迟、处理延迟或数据源限制而导致时间不准确。因此,这个初始的机器人并不能完全实时运行,就像直接连接到金融交易所的生产环境中那样。
话虽如此,这个设置是构建交易机器人的绝佳起点。它介绍了收集和处理实时市场数据的基础知识,使用机器学习模型生成可操作的见解,并建立一个可能发展成稳健交易解决方案的系统。通过在未来的迭代和教程中解决这些限制,比如改进数据源连接或迁移到生产级服务器以提供更好的实时能力,这个机器人可以显著发展,以服务更复杂的交易策略。
```html 感谢您坚持到最后,祝您编程愉快!🎉💻 ```
参考资料
I'm unable to access external websites directly. However, I can help you translate a specific text if you provide it here. Please copy the text you would like translated into simplified Chinese, and I'll be happy to assist you!