ChatGPT-4o 从技术上来说可以运行线性混合模型——但我不推荐将其用于这个目的。
随着我在研究生阶段的生物统计课程中完成作业,我们从简单模型和方法逐渐过渡到更复杂的模型和方法,为ChatGPT-4o带来越来越多的挑战。上周,我们发现它无法正确运行广义加法模型。这周,我调查了它运行线性混合模型的能力。
混合模型是一组特定的回归模型,结合了固定效应和随机效应。固定效应通常是指当预测变量对响应变量产生影响时我们通常假设的情况,我们通常想要了解这个预测变量对响应变量的影响。我们使用随机效应来模拟一个我们知道与响应变量相关的变量的影响,但我们并不特别关心这种影响是什么,我们只是想避免由于不考虑它而引起的潜在偏差。我向我的学生教授这些模型,因为他们经常需要运行为他们的论文项目收集的数据的分析。
我经常告诉学生们的一个喜欢例子是教育研究,我们正在测试新教学法对学生群体的影响。我们可以比较使用新教学法教授的学生与没有使用的学生的学习情况。然而,不同的学生组是由不同的老师教授的,我们知道不同教师的教学效果存在变化。我们不能忽视这一点,尤其是因为同一老师教授不同学生组,如果我们不考虑老师的影响,我们会假设同一教室中的所有学生是相互独立的。我们会犯伪重复的错误。然而,我们当然不想特别测量和比较老师在教学效果方面的差异(出于各种原因)。将老师作为固定效应也会严重限制我们检测新教学法影响的统计能力。相反,我们将老师(或教室)作为随机效果。这将假设老师的教学效果以平均值为中心是正态分布的,每个老师都是从这个正态分布中抽样的,我们只需要估计这个正态分布的方差。这样就可以在不必互相比较老师的情况下考虑老师之间的差异,而且损失的自由度更少。
Here is the translated text in simplified Chinese while keeping the HTML structure: ```html
另一个混合效应模型的常见示例是重复测量设计,其中一个响应变量(如温度)在同一动物身上随着时间的推移反复测量,例如在某些治疗之前和之后。不同的动物可能对治疗的反应不同,但我们只关心所有动物的平均反应,而不需要将每只动物进行比较。然而,忽视某个测量来自于哪个动物又假设所有来自同一动物的测量彼此独立,显然这不是事实,这将再次导致伪重复。将动物身份作为随机效应纳入考虑,再次假设响应的正态分布,使我们能够考虑动物之间的反应差异,并估计这种变异性,而不需要比较所有动物,且损失的自由度更少。
```我向班上的学生们描述了这些问题,并展示了日益复杂的线性模型,包括有交互项和主效应的模型,以及带有随机截距和有或没有随机斜率的混合模型。我的目标是展示如何选择将预测变量作为固定效应或随机效应的选择会如何影响结果,以及如何决定最佳方法。我们还运行R代码,使用nlme软件包中的lme命令来拟合这些模型,并解释摘要输出和效果和诊断图。之后,他们被要求完成一项作业,练习运行和解释类似模型的结果。这就是我这周挑战ChatGPT-4o完成的任务。您可以在下面看到我尝试的视频会话:
```html
在加载我们之前使用的阿根廷数据集之后,我首先请 ChatGPT-4o 列出列名,它毫无困难地完成了这个任务。我还要求它创建三个新的分类变量,以确保尽管它们被编码为数字,但仍然被视为分类变量。在稍稍抱怨之后,它同意了。然后,我请它运行一个简单的线性回归,将 L. acuta 鸟的数量作为响应变量,以中等密度沙子的比例作为唯一的预测变量。ChatGPT-4o 能够正确地拟合线性回归,并提供与我的学生在 R 中得到的相同的回归线和摘要统计数据。唯一的例外是 AIC 值,在 ChatGPT-4o/Python 中比在 R 中低了 2 个单位,因为 R 在对数似然计算(用于离散参数)中包括了一个额外的自由度,而 Python 则没有。重要的是,该模型发现响应变量和预测变量之间存在显著的正相关关系。
```然而,这个模型的问题在于数据是在分配给三个不同横切线的地块上收集的,由于没有将横切线作为预测变量包括进来,我们基本上假设了同一横切线内的地块彼此独立,可能会出现伪重复。因此,我要求它运行一个线性回归,响应变量相同,但MedSand和fTransect(横切线的分类版本)以及它们的交互作为预测变量(因此是一个交互模型)。在变量名'L.acuta'中有一些问题(可能不是最佳选择)后,ChatGPT-4o能够拟合出正确的模型,并提供了所有正确的摘要统计数据,除了AIC中的2单位一致差异。重要的是,MedSand和L.acuta之间的关系不再显著(显示包括fTransect变量的重要性)。当要求比例变动中由预测变量解释的响应变量的比例时,ChatGPT-4o选择了多重R平方,而不是更合适的调整R平方,但这也是我学生们经常犯的错误。在创建效果图时,我在确保其正常工作时遇到了真正的麻烦。首先,它单独绘制了三个面板。然后,当我要求它叠加三条回归线时,它为三个横切线分别拟合了模型。这对于最佳拟合线来说可能是可以接受的,但当我要求它还绘制95%置信区间带时,这绝对是不可以接受的。当我试图使轴的范围与R中的范围相同,并且发现置信区间看起来不同时,我才意识到这一点,然后我回过头看到它正在按照横切线对数据进行子集化。当要求使用交互模型时,它同意了,我可以看到它是在使用Python的get_prediction命令为每个横切线获取预测值和95%置信区间带。这令人担忧,因为如果不查看Python代码,可能会错过这种差异。
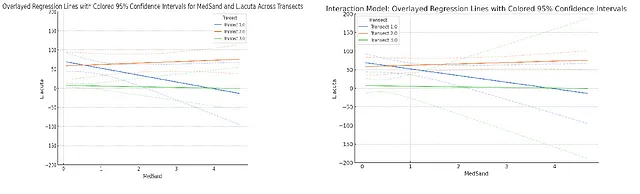
接下来,我要求它使用与响应变量相同的加法模型,但仅包括MedSand和fTransect的主效应,没有交互作用。该模型允许每条传输线的截距不同,但强制回归线之间的斜率相同。ChatGPT-4o/Python能够运行加法模型,并生成所有正确的汇总统计数据(AIC中有一致的2单位差异)。然而,它使用先前的交互式模型创建效应图。这是因为它在Python中使用“sns.lmplot”命令创建图表,而没有选项来不包括交互作用。当我提出这个问题时,它能够使用“get_prediction”命令提供正确的加法模型线条。然而,当我要求它创建“效应”图,就像R中的plot(allEffects())命令所做的那样,虽然它制作了效果图,但完全搞乱了置信区间和区间范围。首先,它使用标准偏差来制作错误栏:
sns.pointplot(x='fTransect', y='L_acuta', data=df_clean, ci="sd")
当我指出这一点时,它使用了95%的置信区间。但是,结果图形仍然与R中的效果图不匹配。当我询问时,原来是基于观测数据使用简单的点估计来估计数据的95%置信区间。我并不太确定它是如何做到这一点的,但它们并不是基于附加模型的。在提示之后,它能够在R中复制fTransects的效果图。当我要求MedSand变量的相同图形时,它出现错误,因此我决定继续前进。
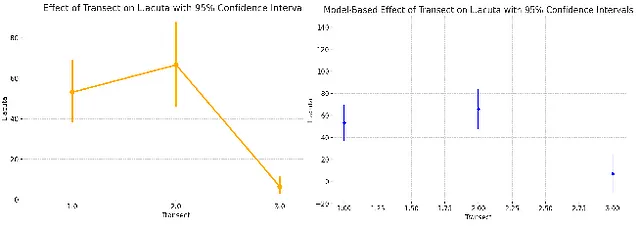
接下来,我要求运行一个模型,使用相同的响应变量,以MedSand作为预测变量,但仅将MedSand和fTransect的交互作为另一个预测变量,不包括fTransect的主要影响。这相当于允许回归线的斜率在不同的横断面之间有所不同,但强制它们的截距相同。ChatGPT-4o能够建立和运行模型,总结统计数据都是正确的,AIC值相差2个单位。然而,它仍然显示了交互模型的图表。在提示之后,它明白我希望它使用模型生成预测和95%置信区间带,因此它能够在R中重新创建效果图。
```html
这是我们进入任务关键部分的地方。我要求它运行一个混合效应模型,使用相同的响应变量和MedSand作为固定预测变量,但将fTransect作为随机截距。随机截距允许三个不同横断面之间的截距略有不同,假设这三个横断面是潜在横断面的随机样本,且这些潜在横断面呈正态分布。在这里,我们没有假设随机斜率,这意味着我们假设每个横断面的斜率是相同的。因此,这是我们之前没有交互作用的模型的随机效应版本。幸运的是,ChatGPT-4o能够使用Python中的“statsmodels”库中的“mixed_linear_model”命令来运行这个混合效应模型,因此我们没有像我上一篇帖子那样失败。它创建了一个效果图,并提供了一个正确的最佳拟合线,及一个接近正确的p值。它误解了我关于随机成分解释的方差比例的问题,但这可能是因为我的措辞。当尝试在效果图中添加95%的置信区间时,结果显示Python中的statsmodels库并没有适用于混合模型的get_prediction命令,因此无法提供准确的95%置信区间。ChatGPT-4o试图仅使用固定效应提供置信区间带,但这些当然是不准确的。当被提示时,它试图通过将随机截距方差纳入标准误差计算来考虑随机效应,但结果仍然不准确,可能是由于使用了Wald近似。它尝试实施自助法以生成更准确的95%置信区间,但很快超时,我就继续进行。ChatGPT-4o能够正确计算类内相关系数(随机效应解释的方差比例),并能够正确解释它。它还能够提供边际和条件R平方值(只考虑固定效应,或同时考虑固定和随机效应)。然而,它没有提供AIC值。
```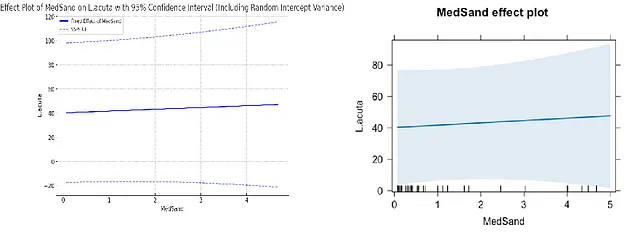
接下来,我要求它拟合一个具有相同响应和预测变量的模型,为fTransect设定一个随机截距,同时为MedSand设定一个随机斜率。这将允许回归线对不同的样本具有不同的斜率,但这种斜率的变化被假定为正态分布,其中三个样本是从这个分布中随机抽取的。 ChatGPT-4o 能够使用MixedLM.from_formula命令来拟合和运行这个模型,并产生了一个正确的最佳拟合线和接近正确的p值。我能够得到这个模型的AIC值,以及之前的模型(具有2单位的差异),通过让它手动计算这些模型的对数似然和参数数量。有趣的是,对于只有随机斜率的模型,这个2单位的差异并不存在,也就是说在R和Python中AIC值是相同的。ChatGPT-4o 能够计算组内相关系数,但在尝试为效果图获取准确的95%置信区间时又失败了。它建议我使用R,或者是一个包装了R的pymer4库,或者是实验性的scikit-mixed-effects库(也许是它虚构的),但它并没有访问这些库的权限。
```html
接下来,我要求比较最后两个模型,使用ANOVA,这采用似然比检验,并决定是否值得在此模型中包含随机斜率,还是随机截距就足够了。结果发现这不可行,因为statsmodels库不支持混合模型的似然比检验(如果我说错了,请纠正我)。相反,它使用AIC值和组内相关系数来推理为何一个模型优于另一个模型。这就是AIC在R和Python之间的差异有意义的地方。R中含有随机斜率和截距的模型的AIC为604,而Python中该模型的AIC为602。仅含随机截距的模型的AIC为601。现在,在R中,这4个单位的差异使得得出有随机斜率的模型更差的结论变得容易,并且应该选择随机截距的模型。然而,在Python中,AIC的1个差异不足以得出这样的结论。简约原则仍然会建议在AIC值在2个单位以内时使用更简单的模型,但这也可以争论。当我要求它比较两个模型的ICC值时,它在尝试重新计算时竟然搞糊涂了。然而,当我提醒ChatGPT-4o它之前已经计算过这些值时,它能够提取并比较它们。根据现有的信息,它建议不包括模型中的随机斜率。然而,当我争辩说这将假设三个样带的斜率是相同的时,它接受了这一点,并表示如果这个假设不合理,那么也许更好地包括它。我喜欢“客观”的统计学可以如此!:-) 它表示不必担心MedSand既是固定效应又是随机斜率,并澄清只有在每个样带只有一个MedSand值的情况下,这种情况才会有问题。
```最后,我要求它使用随机斜率创建模型的QQ图,就像我和我的学生一样,来思考模型假设的有效性。首先,它使用原始残差,结果看起来非常奇怪。在提示下,它将残差标准化,通过除以它们的标准偏差。结果的QQ图看起来更好,因为点沿对角线排列,但可以看到中间部分错位了。来自R的原始QQ图看起来非常不同,表明了与正态分布的偏差。区别在于R使用条件残差来创建QQ图,这包括固定效应和随机效应。不幸的是,Python中的MixedLM似乎没有生成条件预测的方式,同时包含固定效应和随机效应,因此无法获得条件残差。这是一个大问题,因为我们无法制作适当的QQ图,也无法正确对ChatGPT-4o/Python中的线性混合模型进行诊断。我们所能做的最好的事情是创建和运行它们,然后在R中重新编码它们以验证,这听起来不是一个可行的工作流程。在那一点上,我们最好还是在R中完成所有工作。
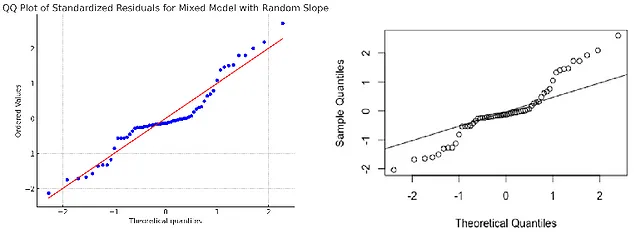
```html
当我上传我学生在 R 中创建的诊断 QQ-图时,ChatGPT-4o 能够检测到分布尾部的正态性偏差,但它也强调了我诚实地不太能看到的中心偏差——这些可能只是幻觉。它的结论是分布“不是完全正态分布”,但这是一个非常弱的陈述,因为没有什么是完全的。我在那个图上看到一个非常大的正态性偏差,但这就是统计学成为艺术的地方!
``````html
最后,我让它绘制我们的响应变量 L.acuta 的分布。它正确地制作了一个直方图(与学生在 R 中使用的不同的区间),并能够检测到数据高度右偏和非正态的性质,以及这如何可能对之前的线性回归构成问题。它还建议了一些解决方案,如变换和广义线性混合模型(GLMMs)。它正确地指出,我们需要对在本次会议中创建的模型持谨慎态度,尽管我会用更强烈的措辞来表达 — 它们都是没有价值的,这对学生们来说是有用的。不幸的是,statsmodels 库在 Python 中唯一可以运行的 GLMM 是一些贝叶斯实现及 scikit-mixed-effects 库,但这些目前都无法在 ChatGPT-4o 上使用。
```因此,总的来说,我发现今天ChatGPT-4o虽然可以通过Python适应并运行线性混合效应模型,但与在R中运行相同模型相比存在一些真实的限制。虽然它可以提供(大部分)正确的摘要统计,但由于无法生成条件预测,它无法提供正确的95%置信区间和区间。此外,它无法本地提供AIC值或在模型之间进行似然比测试。最后,它无法基于条件残差生成正确的诊断图是一个真正的难题,因为你无法诊断模型,即使你可以建立它们。再次强调,这些并不是ChatGPT-4o的真正限制,而是Python架构中基础库的限制,随着时间的推移可能会得到修正。此外,很容易被ChatGPT-4o创建的图表所误导,特别是在关于95%置信区间如何创建的方面。基于这一点,我目前不建议使用ChatGPT-4o/Python来创建、运行、诊断和使用线性混合模型。