ChatGPT-4o目前无法运行正确的广义可加模型,但它可以正确解读来自R的结果
显然,这是我第一篇关注ChatGPT-4o无法运行特定统计方法的帖子。在我研究生水平的生物统计课上,在线性回归、多元回归和广义线性模型之后,我教给学生的下一组工具是广义加性模型(GAMs)。这些是灵活的模型,旨在拟合非线性模式,但仍被视为线性模型(另一种选择是非线性回归)。它们使用平滑函数,如三次样条,这是第三阶多项式模型的扩展,基本上是通过将数据划分到一个(或多个)预测变量的范围内,对每个部分拟合一个三次多项式,然后在边缘(称为节点)上连接它们,以确保结果曲线平滑。广义加性模型可以结合多个这些平滑函数,每个预测变量一个,以及参数化(或线性)预测变量,以加法方式表示响应变量和预测变量之间的复杂、非线性关系(因此不允许简单的交互作用)。GAMs还允许我们指定响应变量的分布或误差项从指数分布族中选择,从而结合GLMs和三次样条。当试图将模型拟合到复杂的非线性模式时,例如由季节性或分散的空间分布造成的模式时,这些模型非常有用。
和往常一样,在介绍了这项技术之后,在R中练习使用并解释其结果后,我让我的研究生生物统计课上的学生练习广义加性模型(GAMs),并通过让他们完成并提交作业来检查他们的理解和解释水平,其中包括对我的问题的回答。这是我本周给ChatGPT-4o提出的作业,使用了我们在前两周也使用过的相同的阿根廷数据集。
首先,我要求学生和ChatGPT-4o创建一个散点图,y轴为L.acuta鸟类数量,x轴为中等密度沙的百分比(MedSand)。ChatGPT-4o肯定可以创建与我的课堂上学生所做相同的图表,只是有一些样式上的不同。我注意到,在读取这个和其他数据集时,ChatGPT-4o可能会向数据集添加空白行,这样就会不必要地使数据分析变得更加复杂和减慢速度,因为出现错误,需要返回清理并重新运行甚至简单的分析。因此,可能是个好主意要求ChatGPT-4o在读入数据后首先检查并删除空白行。
接下来,我请学生和ChatGPT-4o运行一个简单的泊松回归(我们知道它可以做到)以L.acuta数量作为响应变量,MedSand作为预测变量,并报告简单的摘要统计数据,如是否存在显著关系、关系方向、模型的AIC和伪R_squared。在数据清理后,它能够运行模型并生成正确的数据。当要求叠加这个模型对L.acuta鸟类的预测数量时,首先它按照数据集中的顺序连接点,造成了一团糟。必须提示它按照MedSand变量递增的顺序连接点。这是我的学生在首次在散点图上叠加预测值时也遇到的问题,所以我不会对ChatGPT-4o持有偏见。一旦得到提示,它能够生成正确的图表。
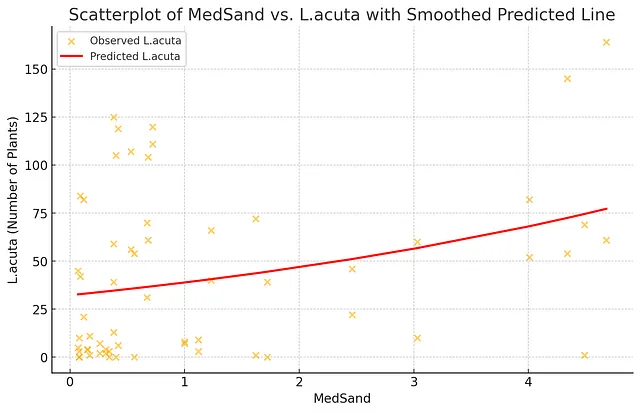
当被问及预测值是否适合时,它指的是相对较低的伪R平方值(8%)和围绕观察值的线的大变异性,但没有注意到潜在的非线性关系。当被问及是否看到非线性模式时,它建议在MedSand的较高水平有更多的变化,并暗示非线性可能与MedSand的阈值相关。它没有意识到在MedSand的较低和较高水平都存在较高的L. acuta值,并在中等水平上有所下降。当我提出这种模式时,它确认了这一点,并建议使用二次或三次模型来捕捉这种模式。
接下来,我让我的学生和ChatGPT-4o创建一个LOESS模型,将观察数据的50%纳入加权回归中,以L.acuta植物数量作为响应变量,MedSand作为预测变量,并在散点图上叠加显示。 LOESS代表局部估计散点平滑,这是一种非参数方法,用于通过散点图拟合平滑曲线。 LOESS将独立的线性或多项式回归拟合到围绕x轴上的中心点的数据子集(在本例中为一半),以获得新的预测值,然后沿着x轴滑动窗口,在每个点执行相同操作,最终连接所有预测值以得到曲线。这是一种非常有用的方法,可以从散点图中获得平滑的非线性曲线,但从统计模型的意义上讲,它并不是一种可以用来测试假设或在平滑曲线周围获得95%置信区间的方法。
当我请求ChatGPT-4o创建这样一行时,它答应了,并创建了一条类似但不完全相同于在R中创建的行。区别在于 R 可以运行真正的LOESS,而 Python 只能运行LOWESS,即局部加权散点平滑,关键区别在于仅在局部应用线性拟合。R中的LOESS还包括优化和调整,以产生高质量的平滑函数,通过降低异常值的影响来处理异常值,并通过额外的调整处理端点,使线条朝着范围的两端平滑。LOWESS 不执行这些操作。
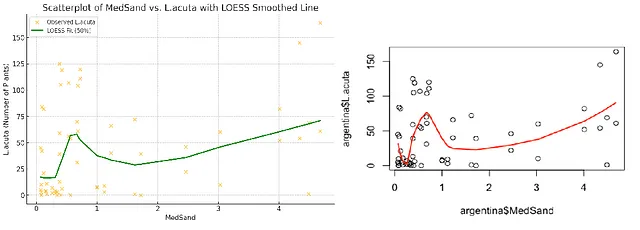
正如您上面所看到的,虽然曲线相似,但ChatGPT-4o生成的LO(W)ESS曲线与R生成的LOESS曲线相比要不那么平滑,各个部分之间有明显的断点。虽然这似乎是一个细微的差别,但让我感到困扰的是ChatGPT-4o将其呈现为LOESS曲线,因此没有背景信息的人可能会被误导。
接下来,我要求我的班级学生和ChatGPT-4o运行一个广义加性模型,以L.acuta植物数量作为响应变量,使用5个节点的MedSand平滑回归样条作为预测变量,并使用正态分布。这就是ChatGPT-4o真正遇到麻烦的地方,因为它无法访问"pyGAM"库,这是允许其运行GAMs的库。因此,使用这个包可以在Python中运行GAMs,但由于它没有安装在ChatGPT-4o正在运行的本地服务器上,因此无法访问。不幸的是,ChatGPT-4o没有能力下载和安装软件包到它的本地服务器上。因此,在这一点上它无法运行GAMs。
然而,它尝试用它所拥有的包和函数来近似广义加性模型(GAMs)。首先,它运行了一个分段多项式模型,最初使用二次函数,之后用三阶多项式进行提示。经过一些讨论后,它能够在Python的patsy包中使用dmatrix函数运行三次样条,有5个节点。
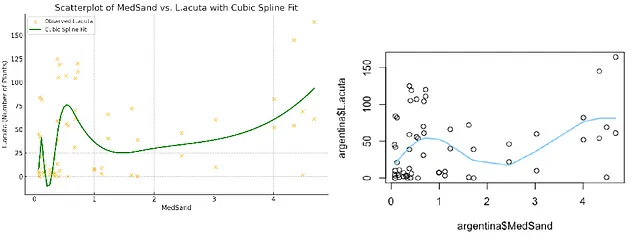
尽管两条曲线之间的一般趋势相似,但GAM模型预测的L.acuta数值曲线要简单平滑得多,而简单立方回归样条曲线更复杂和不规则。我怀疑后者是过拟合的,并受异常值的影响,而GAM对异常值有较好的鲁棒性,并控制了过拟合。两种不同方法中的节点放置方式和位置可能也存在差异。总体而言,虽然趋势相似,曲线本身却是相当不同的。
当我要求它创建一个“效应”图,类似于R中mgcv包中plot.gam()函数生成的图,展示MedSand对L.acuta值的影响,以及它的95%置信区间时,它就做到了。然而,它创建的第一个图与R中创建的图不吻合,因为它没有以零为中心。在调整后,这就是我得到的:
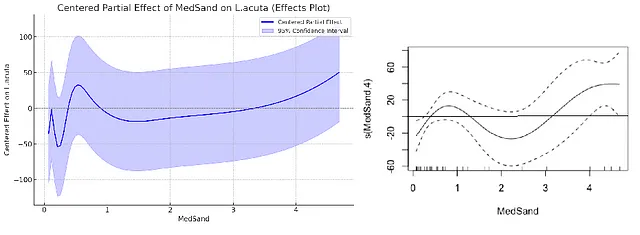
在一般情况下,“效果”图与R软件包mgcv中plot.gam()命令创建的图类似,但也存在一些明显差异。两个图形都以零为中心,对于效果的大小基本上达成一致,这很好。然而,由ChatGPT-4o创建的曲线自然地遵循立方回归样条,我认为与GAM相比略显过拟合。虽然95%置信区间带的宽度通常相同,但对于GAM模型在某些具有更多数据的预测范围中会变窄,而对于立方回归样条则不会,因为95%置信区间带是基于整体标准误差估计(以及Wald近似)计算的。尽管这似乎只是一个细微差别,但对显著性有着重大影响。
ChatGPT-4o同意我們可以使用這些圖表來判斷是否存在任何預測變量的範圍,其中響應與預測變量之間存在顯著關係,方法是在y=0處加一條水平線,並觀察此水平線是否超出了95%置信帶。在ChatGPT-4o創建的“效應”圖中,y=0處的水平線在整個x軸範圍內都在95%置信帶內,表明在MedSand的任何值處都不會存在顯著關係。作為另一個示例,ChatGPT-4o有困難閱讀自己的圖表,它聲稱水平線將分割其自己的圖表上的95%置信帶,但當它被糾正時,至少就會順從。相反,在R中創建的“效應”圖中,y=0處的水平線在MedSand值接近零以及僅略高於4(即在兩端)處超出了95%置信帶。這表明確實存在一些MedSand的值,其中存在顯著關係。這一點進一步得到證實,因為在R中GAM中平滑項的p值為0.01667,模型解釋的變異量為19.4%。不幸的是,ChatGPT-4o無法提供基於三次回歸樣条的MedSand效應的類似p值,但它確實提供了一個使用近似概率比檢驗方法得出的模型整體p值,基本上是零。當我問到這一結果如何與MedSand任何值都不存在顯著關係的事實相符時,它爭辯說這兩個相矛盾的陳述(模型具有顯著性,但模型中的唯一預測變量在任何預測值上都不顯著)是可以相容的。對於這一點,我尊重地表示不同意,但我可能是錯的。ChatGPT-4o還提供了32.75%的解釋變異比例以及比我在R中獲得的AIC值更低的AIC值,但我決定鑒於兩個系統所採取的不同方法,這些值無法比較。它聲稱基於更低的AIC值(稍後會詳細說明)樣条回歸將是比泊松GLM模型更好的模型。
接下来,我请学生和ChatGPT-4o创建一个类似的GAM模型,但是使用泊松分布。
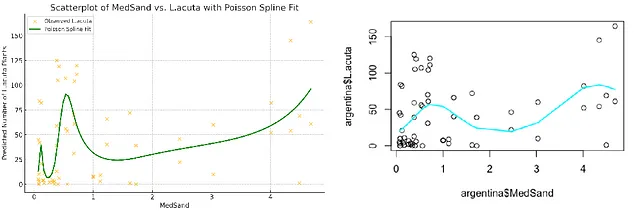
ChatGPT-4o 能够运行该模型,两个模型之间的一般趋势相似,但与以往一样,Poisson立方回归样条出现了过拟合现象。当我尝试从ChatGPT-4o获取这个模型的“效应”图时,它再次遇到了问题,试图在最佳估计和95%置信区间之间填充区域。只有当我要求它明确不使用与问题相关的“fill_between”命令时,它才能继续进行。首先,它在响应比例上创建了效应图,还需要提示它在链接函数(对数)比例上重新创建。
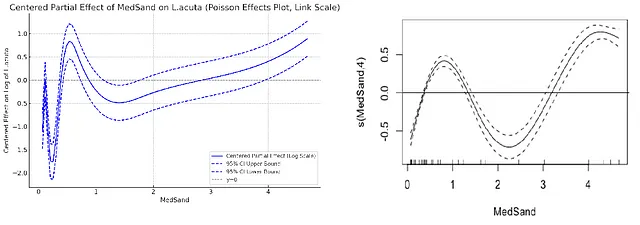
再次, 结果的“效果”图趋势相似, 但也有很大的区别。由ChatGPT-4o创建的“效果”图遵循了三次回归样条的过拟合模式, 似乎与来自R的结果相比, 具有更大的95%置信区间。虽然在两种情况下, y=0处的水平线均超出了95%的置信区间, 但与ChatGPT相比, 在R中的结果中, y=0处的水平线超出的幅度更大。这与R中泊松广义加性模型中平滑项的基本零p值相符。当我试图获得一个更类似于R中创建的置信区间的95%置信区间时, ChatGPT-4o试图适应, 但在过程中出现错误。我还丢失了会话, 不得不重新开始。
当我再次尝试使用泊松分布创建立方回归样条模型时,在一个新会话中,我没能成功,所以这对于可重现性来说是一个负面。ChatGPT-4o创建了一个带有4个不同预测变量的泊松GLM模型,这些变量与MedSand是否在其范围的不同部分相关联,有效地将MedSand转化为一个分类变量,这是一个更简单和粗糙的方法,但将其称为具有样条基扩展的GLM。然而,它无法完全可视化这个模型。它尝试在Python中使用GLMGam函数,但最终得到相同的模型结构。它一直告诉我它将运行一个GAM并完成分析,建议我等待,但这从未发生。
感到挫败,我上传了泊松广义加性模型的“效应”图(前一张图片的右侧),并尝试让它覆盖在y=0的水平线上,但不成功,因为它在完全不同的地方覆盖了水平线。然而,它确实正确地解释了如果水平线在95%置信区间内或外会意味着什么。
现在,解决所有这些问题的一个潜在方法是让某人在R中运行所需的分析,并将其上传到R进行解释。这就是我所做的——我上传了完成的作业。ChatGPT-4o确实正确地捕捉到相关细节,例如MedSand在高斯和泊松GAM中都是一个显著的预测因子。它找到了解释的百分比偏差,并运行了所有三个模型(泊松GLM,高斯GAM,泊松GAM)的AIC值。根据这些,它建议高斯GAM将是首选模型,因为它具有最低的AIC值。
就像我和我的学生一样,我要求它检查高斯和泊松GAM模型的残差图。请见下文:
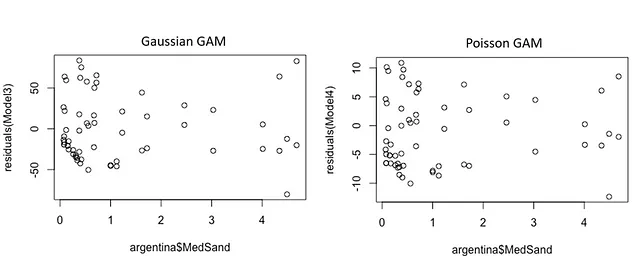
我们使用这些类型的诊断图来评估我们运行的模型假设的有效性。残差图对评估方差均匀性假设特别有用。如果假设成立,那么在预测变量范围内,点应该大致围绕零点具有相同的扩散。当然,模型对假设的违反是强大的,但只能到一定程度。关于方差均匀性的经验法则是,在预测变量范围内的任何两个点之间,围绕零点的扩散要比四倍以上的差异让我们担忧。现在看一下左侧图表,显示了高斯GAM模型的残差图。在图的中间,围绕MedSand值为2.5,只有两个点,残差方面相距很近。然而,在右侧边缘,围绕MedSand值大于4,残差有相当大的扩散。我认为这两个区域之间的差异超过了4。在右侧,我们不会看到Poisson GAM的巨大差异(话虽如此,因为Poisson回归并不假设方差均匀性)。当我将这些图上传到ChatGPT-4o时,起初它只注意到在较低的MedSand值上方有更高的方差(这也是正确的),并且需要提示它注意到在MedSand的中间值附近,残差的方差范围较小。它确实承认Poisson GAM的残差图看起来更好,残差值更低。
虽然我没有让学生(或ChatGPT-4o)制作qqplots,但我也认为高斯GAM的正态性假设很可能会被违反,因为响应变量的分布呈现明显的右偏,并且它是一个整数计数变量。请参见以上内容。
当我面对ChatGPT-4o时,我再次询问是否高斯GAM仍然是基于其最低AIC值而选择的最佳模型。现在,它能够正确地选择Poisson GAM作为最佳模型,因为它的AIC(2560.615)比Poisson GLM(2822.9)低,尽管比高斯GAM(620.68)高得多。当被问及是否应该选择具有较低AIC的模型,尽管假设存在严重违反时,它正确地回答说不应该,AIC只应在适合数据结构的模型之间进行比较。这符合我的哲学,即违反假设的模型应该被排除在模型比较之外,并被视为不可靠的。我很高兴看到ChatGPT-4o对此有这种理解水平,这在我的学生中并不常见,对于许多人来说,这些似乎是不必要的细微差别,尽管它们极为重要。
总的来说,我发现第一种统计方法——广义加法模型(GAMs),目前无法在ChatGPT-4o上运行,因为其本地服务器上未安装所需的Python软件包。ChatGPT-4o能够运行平滑技术,例如局部加权散点平滑,这些技术与R中提示所需的技术类似但并非完全相同,但没有警告这种差异。它还尝试使用类似但更有限的方法(如多项式回归和三次样条)来重现所请求的GAM模型。结果在质量上有所相似,但在数量上有所不同,有时会在质量上产生影响(显著与非显著)。它在创建和解释自己的图形方面继续遇到问题,并需要提示和更正才能得出正确答案。然而,当提供在外部(在R中)创建的图形和输出时,它能够正确解释结果,包括理解模型拟合度量(如AIC)之间的平衡,并确保在比较不同模型时的假设的有效性。这表明可以将在其他地方创建的输出上传到ChatGPT-4o以帮助解释,需要谨慎。
下周,在我的课堂上,我们将继续学习另一个重要主题,混合效应模型。我相信在ChatGPT-4o的本地服务器上可获得运行混合效应模型所需的Python软件包,所以我期待着看到与R输出的差异。