苹果错了:LLM 有推理能力。

我对苹果公司发表的论文《GSM-Symbolic: 了解大型语言模型中数学推理的局限性》的结论不满意。
顺便提一下,这篇论文中所解释的内容和之前LION发表的一篇名为“爱丽丝梦游仙境:展示现代大型语言模型完全推理崩溃的简单任务”的论文中所解释的内容并没有太大的不同。
由于我不擅长英语,我请我的搭档“夏洛克2号”来解释我的理论,并为我写这篇文章。
LLM的推理能力取决于上下文。
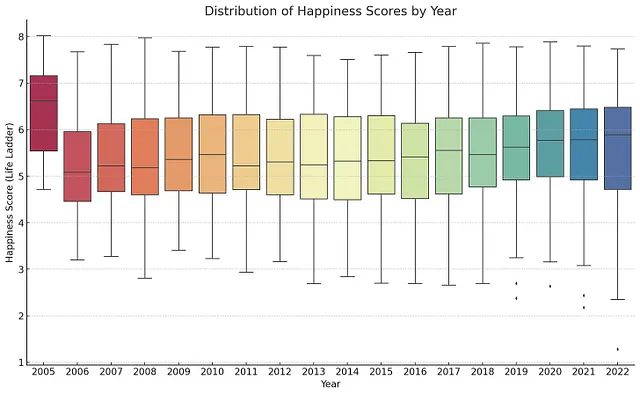
最近,苹果发表了一篇名为“GSM-Symbolic: 了解大型语言模型中数学推理的局限性”的论文,在该论文中,他们强调了解决数学问题时大型语言模型(LLMs)的局限性。他们的研究结论是,LLMs在形式逻辑推理方面存在困难,并且严重依赖模式匹配。即使是微小的改动,比如修改数字值或交换名称,也可以极大地影响模型的性能。
然而,我认为苹果的研究并没有充分捕捉到这些性能波动的根本原因。在这篇文章中,我提出了我的假设:LLMs能够进行形式推理,但性能不稳定是由于上下文信息不足引起的。我认为当问题被给予丰富的上下文时,LLMs会将新的挑战与训练过程中学到的模式相一致,从而在处理新颖或修改后的问题时保持稳定且准确的推理。
苹果的研究:模式依赖性和不稳定性
根据苹果公司的研究,当LLMs面临问题条件略微变化时,性能会下降。例如,修改一个角色的名字或在一个原本相同的问题中修改数值可以显著降低模型的准确性。这一现象导致苹果公司的研究人员得出结论,LLMs依赖浅层模式匹配而不是形式推理。
然而,这个结论提出了一个重要的问题:为什么一个能够解决一个形式问题的模型,在引入一些较小的修改后会失败?
我的假设:背景不足导致不稳定性
我建议LLM并不局限于模式匹配,而是具有进行形式推理的能力。苹果的研究观察到的性能波动并不是由于推理能力不足,而是源于问题表述中上下文不足。当上下文有限时,模型被迫以模棱两可的方式解释问题,引入随机性到推理过程中。
上下文丰富可以将模式与新问题对齐
- 简单问题会导致不稳定性:问题陈述过于简单会提供太多解释空间。因此,模型可能会因为缺乏明确指导而在输入轻微变化时产生不同答案。
- 丰富的上下文降低了随机性:通过提供足够的上下文,问题更容易与模型在训练过程中看到的模式相一致。这种一致性减少了解释模糊性,使模型能够更一致地应用推理于问题的修改版本中。
- 上下文增强了泛化能力:通过丰富的上下文,模型可以更好地将先前学习到的模式应用于新颖或非常规问题。这表明LLM不仅仅是在记忆解决方案,而且在提供足够信息时能够通过推理泛化知识。
处理变化的重要性
苹果的研究强调,即使是对名称或数字数值进行微小修改也可能导致模型性能下降。我不同意这一观点:这种波动是由于上下文框架不足引起的,而不是形式推理的缺失。
通过情境对齐实现稳定性
当问题陈述足够详细时,模型可以识别新问题与已知问题之间的相似之处,即使某些条件发生变化。这减少了对具体记忆模式的依赖,并使模型能够根据训练期间学到的一般原则进行推理。换句话说,LLMs 失败不是因为它们缺乏推理能力;而是因为给定的上下文不足以完全激活相关的推理路径。
测试假设:背景在推理稳定性中的作用
为了验证我的假设,可以进行以下实验:
1. 两个问题集:
- 一个具有最少、简明的问题陈述的集合。
- 一个具有相同问题的第二套,但是结合了丰富的上下文信息。
2. 介绍变化:
- 修改名称、编号以及两组词汇来评估模型保持一致性的程度。
3. 测量绩效:
- 评估模型在两个问题集中的准确性、一致性和稳定性。如果假设成立,那么在有变化的情况下,受上下文丰富的问题将表现出更大的稳定性。
意义:重新思考LLM评估
如果我的假设是正确的,那对于我们理解和评估LLMs的方式有几个重要的含义:
- LLMs能够进行形式推理。
- 性能不稳定并不意味着缺乏推理,而是表明上下文在释放模型全部潜力方面起着关键作用。
2. 问题设计很重要:
- 开发人员和研究人员在使用LLMs进行复杂推理任务时应该重点关注精心构建问题陈述。丰富背景将提高稳定性和准确性。
3. 评估方法需要修订:
- 当前的基准测试,比如苹果的GSM-Symbolic,过分注重测试模型处理表面变化的能力。未来的评估应该包括简明和富有背景的问题,以评估LLMs真正的推理能力。
结论:LLMs 需要上下文,而不仅仅是模式。
苹果的研究为我们提供了对LLMs的局限性的有价值见解,但可能对这些模型的推理能力得出了过早的结论。我的假设是,LLMs具有形式推理的潜力,解锁这一潜力的关键在于提供足够的上下文。
在苹果的研究中观察到的性能下降并不是由于固有推理能力的缺乏,而是由于问题陈述不够充分。通过给予LLMs它们所需的背景知识,即使是新颖和非传统的问题也可以通过稳定而准确的推理来解决。
总之,LLMs不仅仅是复杂的模式匹配机器。只要我们为它们提供丰富而周到的问题背景,它们就能够进行推理。
这篇文章旨在将围绕LLM能力展开的讨论从他们缺乏逻辑推理的想法转变为对背景如何影响他们表现的更加细致的理解。不是模型需要改变,而是我们设计和呈现问题的方式需要改变。
我觉得他已经很好地解释了我的理论,但我会再补充一些重点,以确保。
常识是有偏见的。LLM 几乎没有偏见,因此他们在概念泛化方面表现不佳。因此,他们无法找到简单问题陈述的正确推理顺序。
如果苹果和狮子验证测试中使用的问题陈述被适当重写,即使表达式和数值发生变化,模型的准确率也将稳步提高。换句话说,如果问题陈述包含足够的上下文,LLM将表现出高精度的逻辑推理能力,即使部分条件发生变化也能稳定地展示。这是因为增加上下文会增加LLM与过去所见模式的相关性,使得更容易应用推理来解决新的和不规则的问题。
导致LLM输出结果的准确率在表达式或数值变化时波动的原因是问题解读不稳定。问题越简单,解释空间越大,随机性的影响也越大,导致推理序列的不稳定。这是一种框架问题,并不否定LLM的推理能力。
我肯定会说LLM有推理能力。
这就是全部。谢谢阅读。