在 RAG 框架中解析 PDF 以进行图像检索
在我之前的文章中,我们探讨了将图像检索集成到检索增强生成(RAG)框架中如何通过添加视觉上下文来增强文本生成。现在,我们将进一步深入探讨如何通过解析PDF文档将其整合到RAG模型中,以实现有效的图像检索。
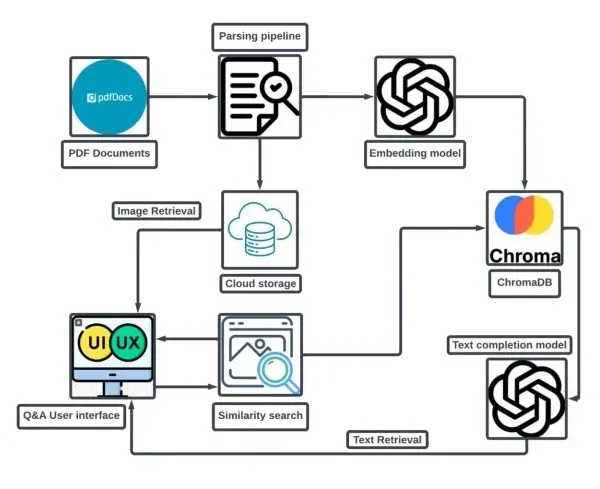
解析PDF以提取文字和图片会遇到一些挑战,尤其是当涉及将图片与对应的文字对齐时。本文概述了我们是如何应对这些挑战并开发出能够准确检索相关内容的解决方案的。
请务必阅读上一篇文章以了解更多信息...
请访问https://medium.com/@nvmukesh/image-retrieval-in-rag-framework-07c750695d9d。
对齐文本和图像:核心概念
为了能够有效地从PDF中检索图像,保持图像与其相对应的文本之间的关系至关重要。我们采用的方法是每页提取1-2幅图像,并将它们与在该页上找到的文本关联起来。
经过解析的文本和相关图片随后被存储为元数据在向量数据库中,使得在进行查询时可以快速且具有丰富上下文的检索。
PDF解析过程
对于这个解决方案,我们使用了pdfplumber,这是一个允许精确提取PDF文本和图像的Python库。以下是逐步过程:
- PDF分块处理:每个PDF文件被分解为页面。每个页面被视为一个独立的文档。这确保了文本和图像保持紧密对齐以便检索。
- 文本嵌入:一旦我们获得了每个页面的文本,就会使用OpenAI的ada-002模型对其进行嵌入。这些嵌入对于根据用户查询检索相关内容至关重要。
- 图像提取:页面上的图像会被提取并分别存储,可以是在本地存储或像Azure这样的基于云的解决方案上。这些图像通过元数据与其相应的文本嵌入相关联。
- 在ChromaDB中存储:文本嵌入以及包含图像URL的元数据被存储在ChromaDB中。这使我们不仅可以查询数据库中的文本,还可以查询相关图像,创建一个真正的多模态检索系统。
为什么要分块 PDF 文件?
在处理大型PDF文件时,将文档分解(或“分块”)为较小、可管理的部分是非常重要的,以确保嵌入模型能够高效处理它们。这样可以更好地对文档的特定部分进行上下文表示和检索,以便在查询过程中更有效地获取特定内容。
技术工作流程
让我们来分解工作流程:
- PDF被解析为单独的页面。
- 每页上的文本都是分块嵌入的,使用OpenAI的ada-002。
- 图片被提取并上传到本地或云存储。
- 图片位置(URL)与文本嵌入一起存储在ChromaDB中作为元数据。
- ChromaDB的查询返回相关文本和图像,以实现更引人入胜和上下文丰富的响应。
用于解析PDF并存储带有图像元数据的嵌入的代码
这段Python代码演示了解析PDF文件、提取文本和图像,并将结果数据存储在矢量数据库(ChromaDB)中,以在RAG框架内高效检索的过程。该方法集成了Azure Blob存储管理图像和OpenAI的嵌入表示文本。

1. PDF 解析和图像提取
我们使用pdfplumber和fitz库解析PDF文件,并从每一页提取图像,将图像存储在Azure Blob Storage中。同时提取文本,并将文本和相关的图像URL都存储为元数据。
import os
import uuid
import fitz # PyMuPDF for PDF manipulation
from azure.storage.blob import BlobServiceClient
from azure.core.exceptions import ResourceExistsError
def parse_pdf_from_blob(pdf_data, blob_name, folder_name, container_client):
data_dict = {}
pdf_document = fitz.open(stream=pdf_data, filetype="pdf")
file_name = os.path.splitext(os.path.basename(blob_name))[0]
for page_num in range(len(pdf_document)):
page = pdf_document[page_num]
text = page.get_text("text")
image_list = page.get_images(full=True)
image_paths = []
for img_index, img in enumerate(image_list, start=1):
base_image = pdf_document.extract_image(img[0])
image_data = base_image["image"]
image_ext = base_image["ext"]
image_name = f"{file_name}_page_{page_num + 1}_image_{img_index}.{image_ext}"
image_path = f"{folder_name}_ext_img/{image_name}"
blob_client = container_client.get_blob_client(image_path)
try:
blob_client.upload_blob(image_data, overwrite=True)
except ResourceExistsError:
print(f"Image {image_name} already exists.")
image_paths.append(image_path)
data_dict[f"{file_name}_Page_{page_num + 1}"] = {
'text': text,
'image_paths': '---'.join(image_paths),
'file_path': blob_name
}
pdf_document.close()
return data_dict
2. 将文本和图像元数据转换为文档
接下来,解析后的文本和图像元数据将被转换为文档对象,然后将被存储在ChromaDB中。
from langchain.docstore.document import Document
def text_to_docs(extracted_data):
doc_chunks = []
for page_name, page_data in extracted_data.items():
doc = Document(page_content=page_data["text"])
doc.metadata = {
"file_path": page_data["file_path"],
"page": page_name,
"image_paths": page_data["image_paths"]
}
doc_chunks.append(doc)
return doc_chunks
3. 在ChromaDB中存储嵌入embedding
最后,使用OpenAI的ada-002模型生成文本嵌入,并将文本与元数据存储在ChromaDB中。
from langchain.vectorstores.chroma import Chroma
from langchain_community.embeddings import AzureOpenAIEmbeddings
from openai import AzureOpenAI
def docs_to_index(docs, ai_key, api_version, ai_endpoint, ai_embedding_model, collection_name, persist_directory):
client = AzureOpenAI(api_key=ai_key, api_version=api_version, azure_endpoint=ai_endpoint, azure_deployment=ai_embedding_model)
embeddings = AzureOpenAIEmbeddings(client=client)
embeddings_index = Chroma(collection_name=collection_name, embedding_function=embeddings, persist_directory=persist_directory)
for doc in docs:
embeddings_index.add_texts(
texts=[doc.page_content],
metadatas=[doc.metadata],
ids=[str(uuid.uuid1())]
)
embeddings_index.persist()
print("Indexing completed.")
这段代码提供了解析PDF、提取文本和图像、并将它们保存到ChromaDB 中嵌入的核心功能。
检索文本和图片
一旦PDF被处理并存储在ChromaDB中,查询数据库将返回文本和图像,使我们能够生成丰富的、多模式的响应。这是构建智能内容检索系统的基础,可以通过利用文本和图像提供更准确的答案。
结论和接下来的步骤
感谢您的阅读!在下一篇文章中,我们将探讨如何查询这个解析的PDF内容和图像检索系统,并将响应集成到RAG框架中以增强生成。请继续关注!