你甚至应该相信双子座的百万标记上下文窗口吗?
想象一下,你被要求分析你公司的整个数据库 - 数百万客户互动,数年的财务数据和无数的产品评论 - 以提取有意义的见解。你转向人工智能寻求帮助。你把所有数据都塞进 Google Gemini 1.5,具有新的一百万标记上下文长度,并开始发出请求,似乎正在解决问题。但一个令人不安的问题仍然存在:你能相信人工智能准确处理和理解所有这些信息吗?当它处理如此庞大的数据量时,你对其分析有多有信心?你是否需要翻阅一百万个标记的数据来验证每一个答案?
传统人工智能测试,如众所周知的“大海捞针”测试,在真正评估人工智能在大量连贯信息中推理能力方面存在不足。这些测试通常涉及在一个同质的背景中隐藏不相关的信息(针)。问题在于,这使得焦点集中在信息检索和异常检测,而不是全面理解和综合。我们的目标不只是看它能不能在大海捞针中找到针,而是评估它是否能理解整个“大海捞针”。
使用真实世界的App Store信息数据集,我们系统地测试了逐渐增加的上下文长度下的Gemini 1.5闪光版本。我们要求它比较应用价格,回顾特定的隐私政策细节,并评估应用评级 - 这些任务需要信息检索和推理能力。对于我们的评估平台,我们使用了LangChain开发的LangSmith,证明在这个实验中是一个宝贵的工具。
结果简直令人惊叹!让我们深入了解。
设置实验
你可以跟着我们在这个Jupyter笔记本中的完整实验。
选择我们的数据集
我们需要3个数据集用于我们的实验:
- App数据集:我们使用了苹果应用商店数据集,这是一个关于1万个应用程序的真实世界信息集合。这个数据集为我们提供了丰富多样的信息进行分析。
- 黄金数据集: 我们随机选择了5个应用程序,用于制定我们的评估数据集问题和地面真实答案。这5个应用程序将需要在实验的每一步中包含在上下文中。
- 评估数据集:我们根据黄金数据集制作了一组三个问题和答案。这些是我们将要问双子座Flash的问题,我们将评估其答案与我们写的标准答案。
examples = [
{
"question": "Do the 'Sago Mini Superhero' and 'Disney Channel Watch Full Episodes Movies TV' apps require internet connection?",
"answer": "You can play Sago Mini Superhero without wi-fi or internet. Internet is required for Disney Channel Watch Full Episodes Movies TV"
},
{
"question": "Where can I find the privacy policy for the 'Disney Channel Watch Full Episodes Movies TV' app?",
"answer": "http://disneyprivacycenter.com/"
},
{
"question": "Which one costs less? The 'KQ MiniSynth' app or the 'Sago Mini Superhero' app?",
"answer": "The 'KQ MiniSynth' app costs $5.99, the 'Sago Mini Superhero' app costs $2.99. So 'Sago Mini Superhero' is cheaper"
}
]
利用Gemini 1.5 Flash
对于我们的AI模型,我们利用了谷歌的Gemini 1.5 Flash。该模型允许在其上下文窗口中最多有100万个标记,大约相当于70万个词!在撰写本文时,Gemini 1.5 Flash的成本约为每百万输入标记0.70美元,而且这还没有缓存。这与GPT-3.5或Claude Haiku的定价相当。
LangSmith: 我们的评估平台
为了管理我们的实验并评估结果,我们转向了LangChain的LangSmith。LangSmith为我们提供了一些适合这种实验的功能。
- 当我们将评估数据集上传到LangSmith时,我们可以在LangSmith控制台中进行版本控制、拆分甚至生成合成数据。
- 我们所有的实验结果和追踪数据都在LangSmith中针对每个数据集进行跟踪。仪表板允许我们可视化不同上下文长度的性能。
在运行我们的实验时,不是必须的,但使用LLM作为评判员进行自动评估是相当方便的。在我们的情况下,这意味着对于数据集中的每个问题:
- 双子座闪光试图回答这个问题
- 根据数据集中我们编写的地面真实答案,如果Flash的答案正确,我们将有GPT-4o得分。
这个功能是通过LangSmith自定义评估器实现的,这些评估器是简单的Python函数,用来返回评估的得分。
# We define the scoring schema for the LLM to respond in
# using Pydantic
class EvaluationSchema(BaseModel):
"""An evaluation schema for assessing the correctness of an answer"""
reasoning: str = Field(
description="Detailed reasoning for the evaluation score")
correct: bool = Field(
description="Whether the user's answer is correct or not")
# Our evaluation function
def qa_eval(root_run: Run, example: Example):
"""Evaluate the correctness of an answer to a given question"""
# The question from the dataset example
question = example.inputs["question"]
# Gemini's answer
flash_answer = root_run.outputs["output"]
# Ground truth answer from the dataset
correct_answer = example.outputs["answer"]
# Force GPT-4o to respond in the scoring schema
llm = ChatOpenAI(model="gpt-4o", temperature=0.4).with_structured_output(EvaluationSchema)
system_prompt = f"""You are a judge tasked with evaluating a user's answer to a given question.
You will be provided with the question, the correct answer, and the user's thought process and answer.
Question:
{question}
Correct Answer:
{correct_answer}
Your job is to assess the user's answer and provide:
1. Detailed reasoning for your evaluation, comparing the user's answer to the correct answer
2. A boolean judgment on whether the user's answer is correct or not
Be thorough in your reasoning and accurate in your judgment. Consider partial correctness and any nuances in the answers."""
# Invoke the model with all of the context
evaluation: EvaluationSchema = llm.invoke(
[SystemMessage(content=system_prompt),
HumanMessage(content=flash_answer)]
)
score = 1 if evaluation.correct else 0
return {
"score": score,
"key": "correctness",
"comment": evaluation.reasoning
}如果您不熟悉LangChain或Python,我们只是写一个函数(qa_eval),该函数从数据集中获取问题、Flash的答案和正确答案,并将它们全部放入一个提示中供GPT-4o使用。我们使用.with_structured_output来确保LLM以特定的模式回应,以便我们可以返回LangSmith期望的分数模式。
运行实验
我们逐渐增加上下文长度,直到完整的百万词汇容量,每次增加5万个词汇。要生成这些不同长度的上下文,我们编写了一个名为get_context的函数,将:
- 从我们的“黄金数据集”中开始,包括5个应用程序。
- 直到达到所需的令牌数量,添加额外的应用程序数据
- 在上下文中随机排列应用程序的顺序,以避免任何位置偏见。
目标功能
我们在我们的“目标函数”中使用这个get_context函数。目标函数描述了将用于生成需要评估的输出的函数。在我们的情况下,目标函数:
- 使用应用程序数据填充上下文窗口,直到我们在该步骤中测试的令牌数量。
- 将上下文放入Gemini Flash的提示中
- 用数据集中的问题查询Gemini Flash,并返回模型的响应。
这是我们目标函数的简化版本:
def predict(inputs: dict):
tokens = (max_context_limit / total_steps) * current_step
context = get_context(tokens)
system_prompt = f"""You are tasked with answering user questions based on the App Store data inside <APP STORE DATA>.
Use ONLY the information provided in the context. Be as accurate as possible."""
response = llm.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=inputs["question"])
])
return {"output": response.content}
我们将所有这些内容封装到一个自定义的Python类中,只是为了方便跟踪步骤并控制每个实验,然后我们就可以准备运行了!
result = evaluate(
self.predict, # Our predict function
data=client.list_examples(dataset_name=dataset_name), # Our evaluation dataset
evaluators=[qa_eval], # Our custom evaluator
experiment_prefix=f"{self.model}-{tokens}" # Prefixes the experiments in Langsmith for readability
)
结果
我们与 Gemini 1.5 闪光进行的实验结果简直是惊人的!无论是 50,000 个标记还是达到一百万个标记容量,Gemini 1.5 闪光在回答我们的测试问题时都达到了100%的准确率!
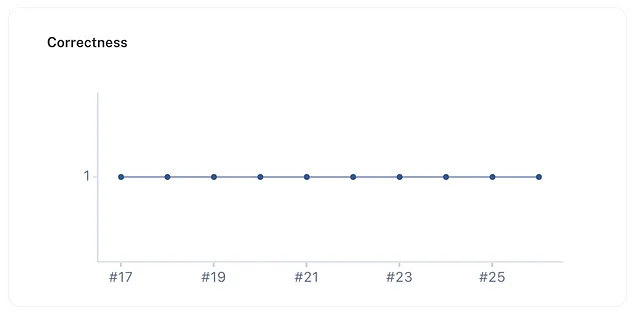
您可以在LangSmith这里查看完整的测试结果。
让我们来分解一下这意思:
- 🔬 完美准确性:无论我们给予 Gemini 1.5 Flash 50,000标记的上下文还是1,000,000标记,它始终正确回答我们的问题。这种一致性水平令人印象深刻,并表明该模型能够有效处理和利用来自极大上下文的信息。
- 🧠信息综合:我们的问题需要不仅仅是检索信息。它们涉及比较来自不同上下文部分的数据点。 Gemini 1.5 Flash的满分表明具有强大的能力,可以理解跨越广泛上下文的信息,而不仅仅是定位特定字符串。
放在适当的背景下,Gemini 1.5 Flash 在最大上下文长度时,可以在处理相当于一本400页书的查询时准确地回答问题。这是传统文档分析能力的显著飞跃。
然而,值得注意的是我们实验的一些限制:
- 问题复杂度:我们的问题虽然需要综合,但相对简单。我们故意避免了需要复杂数值推理或跨整个数据集识别趋势的问题。
- 有限问题集:我们为每个评估使用了一套小问题集。更大更多样化的问题集可能会更深入地揭示模型的能力。
尽管存在这些局限性,但结果仍然非常令人兴奋。它们表明,即使在处理海量背景信息时,Gemini 1.5 Flash 仍能以极低成本保持高准确性和信息综合能力。这为在各个领域的应用提供了令人兴奋的可能性,从商业分析到科学研究。
如果你喜欢这篇文章,可以访问智者博客获取更多类似内容!