为开发者设计的ChatGPT提示工程化
在生成式人工智能领域,提示工程在有效利用大型语言模型(LLM)的能力方面发挥了关键作用。由deeplearning.ai提供的课程为不同类型的LLMs和其最佳利用原则提供了深入的指导。在这里,我总结了这个短期课程的见解!
大型语言模型的类型
- 基础LLMs:这些模型能够根据提供的文本 proficiently 预测下一个单词,从而实现句子完成等任务。例如,当提示“法国的首都是什么?”时,一个基础LLM可能生成类似的回答:“法国最大的城市是什么?法国的人口是多少?”等。
- 指令调整的LLM:这类LLM经过训练,遵循特定的指令,因此备受欢迎。与基本LLM不同,它们能够提供直接回答查询的响应。自ChatGPT推出以来,这些模型实际上是越来越受欢迎的。例如,当被问及关于法国首都的同一个问题时,一个经过指令调整的LLM会回答“法国的首都是巴黎。”这些模型使用以下方法进行训练:
- 具有良好尝试遵循这些建议的说明。
- 有时候,进一步的改进也是通过像加强学习使用人类反馈(RLHF)这样的技术实现的,从而增强模型准确地遵循指导的能力。
有效提示工程原则
1. 清晰明确的指示
清晰的指示对于引导LLMs产生期望的反应至关重要。然而,清晰并不总是等同于简洁;往往需要详细的说明才能充分传达任务。有几种策略可以帮助制定清晰的提示:
- 策略1:分隔符:使用分隔符来标记输入的不同部分,防止提示注入并确保遵守原始指令。
- 策略2:结构化输出:请求结构化输出,如HTML或JSON格式,以便更方便地处理和解释模型的响应。
- 策略三:假设检查:在请求输出之前,验证任务完成所需的条件是否满足。
- 策略4:少样本提示:提供任务完成的成功示例,以有效指导模型的响应风格。


2. 给模型时间思考
允许LMM足够的时间进行处理和推理,然后再给出最终答案对减少错误至关重要。促进深思熟虑参与的策略包括:
- 策略1:规定步骤:将复杂任务分解成顺序步骤,引导模型通过有结构的问题解决过程。
- 策略2:自我反思:鼓励模型在评估提供的解决方案正确性之前,先制定自己的解决方案,促进对任务的更深入理解。例如,对于这个问题:

学生的解决方案实际上是不正确的。正确的解决方案是$360x + $100,000。为了解决这个问题,我们可以要求模型遵循以下指令:
- 首先,找出自己的解决方案,包括最终总数。
- 然后比较您的解决方案和学生的解决方案,并评估学生的解决方案是否正确。
- 不要在自己没有亲自做过题目之前就决定学生的解决方案是否正确。
在提示开发中的其他考虑因素
迭代过程
类似于训练机器学习模型的迭代过程,提示开发也遵循着一个循环模式,包括:创意生成→实现→实验→错误分析→改进。
温度控制
温度是调节LLM输出中探索和创造力水平的关键参数。较低的温度产生精确、事实性的回应,而较高的温度则鼓励更多样化和富有想象力的输出。此外,温度还可以影响回应的详细程度,较低的温度偏向简洁,而较高的温度促进详细阐述。
解决模型局限性:幻觉
有时LLM会发表听起来似乎合理但实际上不是真实的陈述,这被称为幻觉。预防幻觉的一些策略包括:
- 用相关信息或已有的数据“搭接”您的提示,为AI提供额外的上下文和您真正感兴趣的数据点。
- 实验温度:较低的温度意味着更不容易产生幻觉。
- 请LLM不要说谎!
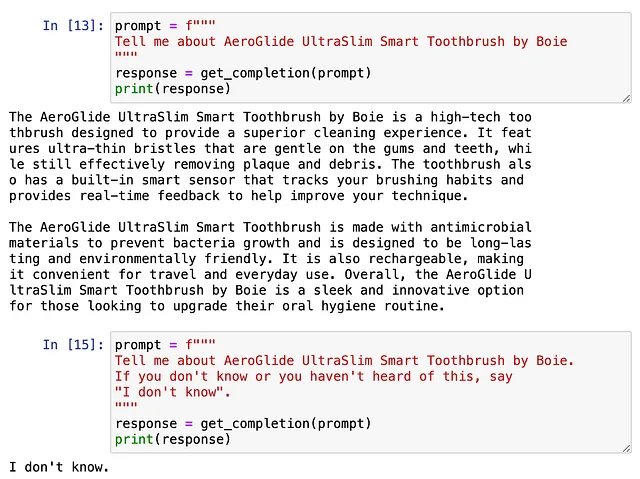
利用语言任务来进行各种应用
文本摘要
文本摘要对于压缩冗长文本(如产品评论)至简洁、信息丰富的摘要至关重要。通过在提示中明确摘要的重点,用户可以有效地调整输出以满足其特定需求。例如,利用客户评论为公司不同部门提供特定反馈。
实体提取
在可能忽略重要细节的情况下,实体提取对于识别和孤立文本中的特定实体或信息非常有益。
推断与转换
任务,如文本分析和主题建模,可以通过零-shot 学习来实现,使 LLMs 能够从非结构化文本数据中推断见解。此外,LLMs 在机器翻译、格式转换和风格适应等转换性任务中表现出色,展示了它们在各种语言处理领域的多功能性。
展开文本
通过使用短文促使LLMs生成更长、个性化的回应对内容生成和定制至关重要。通过提供关于LLM身份和预期任务的背景信息,用户可以有效地引导生成定制的回应。
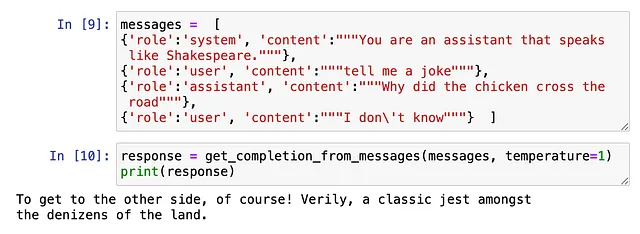
构建一个聊天机器人
使用LLM非常容易构建聊天机器人。在这里,我们不是将单个消息传递给LLM,而是使用一系列消息。对于每条消息,都有一个角色与之对应。对于单个消息,这个角色是“用户”。可用的不同角色类型有:
- 系统:为整体指导。例如:“您是一位AI助手,旨在做……”
- 用户:助手用户的提示。
- 助理:助理的先前回复。
我们需要向LLM提供过去对话的完整上下文,以便得到想要的回应。
总之,掌握及时工程的艺术让开发者能够充分利用大型语言模型在不同应用中的潜力,促进自然语言处理任务中更高效和定制的交互。通过遵循明确的原则并利用创新策略,开发者可以优化LLM的性能和效用,推动人工智能驱动的沟通和问题解决方面的进展。







