Sure, here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html 理解和实施Medprompt ``` In this HTML snippet: - `` specifies that the text inside is in simplified Chinese. - `理解和实施Medprompt` is the translation of "Understanding and Implementing Medprompt". - `` closes the `` element.
Sure, the translation of "Digging into the details behind the prompting framework" into simplified Chinese while keeping HTML structure would be: ```html 深入探讨提示框架背后的细节 ``` This HTML structure preserves the text content while allowing it to be displayed or processed in a web environment.
Certainly! Here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html
在我的第一篇博客文章中,我探讨了提示及其在大型语言模型(LLMs)背景下的重要性。提示对于从LLMs获取高质量输出至关重要,因为它指导模型的响应,并确保其与手头任务相关。在此基础上,解决使用LLMs的用例时通常会出现两个关键问题:仅通过提示能推动性能到何种程度?何时应果断决定,调整模型可能比仅使用提示更有效?
``` This HTML snippet contains the translated text in simplified Chinese.在进行关于利用提示的设计决策时,需要考虑几个因素。像少样本提示和思维链 (CoT) [2] 提示这样的技术可以帮助提升大多数任务中语言模型的性能。检索增强生成 (RAG) 流水线可以进一步增强语言模型的性能,它适应新领域而无需微调,并在减少幻觉的同时提供对生成输出的控制能力。总体而言,我们拥有一套工具可以在不显式进行微调的情况下推动语言模型性能的进步。
在保持HTML结构的前提下,将以下英文文本翻译为简体中文: 细调带来了一系列挑战和复杂性,涉及到标记数据的需求和语言模型训练以及部署的成本。在某些情况下,细调还可能增加语言模型出现幻觉的可能性[3]。综合考虑这些因素,我们可以看到,通过提示来优化语言模型在特定任务中的性能,是一种非常有价值的方法,而不是立即采用细调。
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure intact: ```html
那么,我们该如何处理这个问题呢?在本文中,我们探讨了Medprompt [1],这是微软引入的一种复杂的提示策略。Medprompt 将少样本提示、CoT 提示和 RAG 原则结合起来,以在医疗领域增强 GPT-4 的性能,而无需进行任何领域特定的微调。
``` This HTML snippet translates the provided English text into simplified Chinese, preserving the structure for web display.To translate "Table of Contents:" into simplified Chinese while keeping the HTML structure, you can use the following:
```html
目录:
```
In this HTML snippet:
- `` represents a top-level heading, typically used for the title or heading.
- "目录:" is the translation of "Table of Contents:" in simplified Chinese.
So, the entire line in HTML would look like this:
```html
目录:
```
This structure ensures that the translated text is properly formatted as a heading in an HTML document.
目录:
``` This structure ensures that the translated text is properly formatted as a heading in an HTML document.- Sure, here's how you could structure the HTML to display "MedPrompt Explained" in simplified Chinese:
```html
MedPrompt Explained MedPrompt Explained
``` In this HTML structure: - `lang="zh-CN"` specifies the language as simplified Chinese. - `` tag sets the title of the document to "MedPrompt Explained". - `<h1>` tag creates a heading with the text "MedPrompt Explained".</h1> - Sure, the translation of "Components of MedPrompt" into simplified Chinese while keeping the HTML structure could look like this: ```html MedPrompt 的组成部分 ``` In this example: - `` tags are used to maintain the inline structure. - "MedPrompt 的组成部分" is the simplified Chinese translation of "Components of MedPrompt".
- To translate "Implementing MedPrompt" into simplified Chinese while keeping the HTML structure intact, you can use the following: ```html 实施 MedPrompt ``` This HTML snippet ensures that the text "实施 MedPrompt" is displayed correctly in a web context, maintaining the structure of the HTML document.
- 在保持HTML结构的情况下,将英文文本 "Evaluating Performance" 翻译成简体中文为 "评估表现"。
- Conclusion in simplified Chinese is "结论".
- Sure, here is "References" translated into simplified Chinese while keeping the HTML structure: ```html 参考文献 ```
Sure, the translation of "MedPrompt Explained" into simplified Chinese while keeping the HTML structure would look like this: ```html MedPrompt 说明 ``` In this HTML snippet, `` is used to wrap the translated text "MedPrompt 说明", which means "MedPrompt Explanation" in English.
Sure, here's the simplified Chinese translation of the provided text while keeping the HTML structure intact: ```html LLMs在各个领域展示了令人印象深刻的能力,特别是在医疗保健领域。去年,谷歌推出了MedPaLM [4] 和 MedPaLM-2 [5],这些LLM不仅在医疗多项选择题答题数据集中表现出色,而且在开放式医学问题回答中表现出色甚至超过临床医生。这些模型通过指导微调和使用由临床医生撰写的“链式思维”模板,专门为医疗保健领域量身定制,显著提升了它们的性能。 ``` This translation maintains the structure of the original text while converting it into simplified Chinese.
在这个背景下,来自微软的论文《通用基础模型是否能胜过特定用途调整?以医学为例》[1] 提出了一个引人深思的问题:
Sure, here is the text translated into simplified Chinese while keeping the HTML structure intact: ```html
如何在不依赖领域特定的微调或专家制定的资源的情况下,提高像GPT-4这样的通用模型在特定领域的性能?
``` This HTML snippet contains the translated text in simplified Chinese.To translate the given English text into simplified Chinese while keeping the HTML structure, you can use the following: ```html 作为这项研究的一部分,本文介绍了Medprompt,一种创新的提示策略,不仅提高了模型的性能,还超过了诸如MedPaLM-2之类的专业模型。 ``` This HTML structure ensures that the translation is maintained properly and can be integrated into a webpage seamlessly.
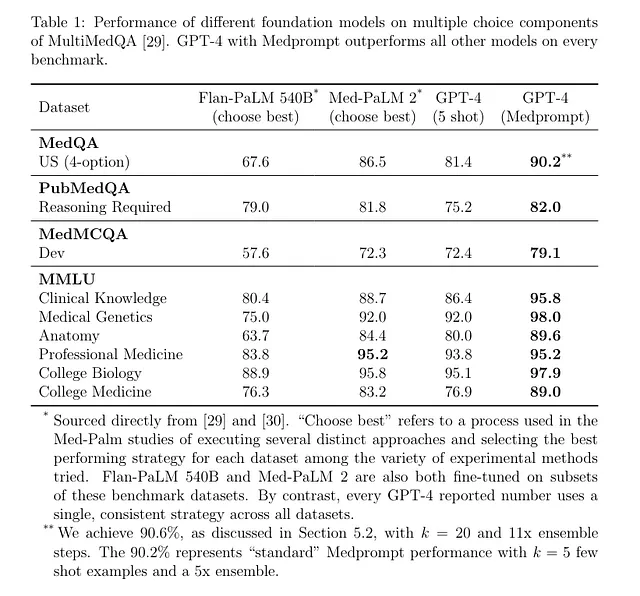
在保持HTML结构的情况下,将以下英文文本翻译为简体中文: "GPT-4 with Medprompt outperforms Med-PaLM 2 across all medical MCQA benchmarks without any domain-specific fine-tuning. Let’s explore the components in Medprompt." 翻译后的文本如下: "GPT-4与Medprompt在所有医学MCQA基准测试中表现优于Med-PaLM 2,且无需进行任何领域特定的微调。让我们来探索Medprompt中的组成部分。"
Sure, the translation of "Components of Medprompt" into simplified Chinese while keeping the HTML structure intact would be: ```html 组成部分:Medprompt ```
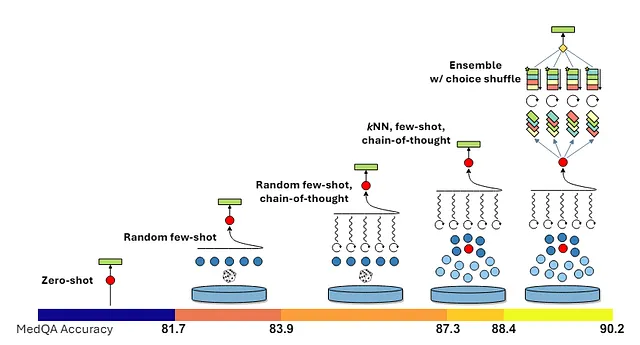
在保留HTML结构的情况下,将以下英文文本翻译为简体中文: Medprompt 结合了少样本提示、CoT提示和RAG的原则。具体来说,该流程包括三个组件:
To translate "Dynamic Few-shot Selection" into simplified Chinese while keeping HTML structure, you can use the following: ```html 动态少样本选择 ``` This HTML snippet retains the structure and translates the text as requested.
在保留HTML结构的情况下,将以下英文文本翻译成简体中文: Few-shot prompting refers to utilizing example input-output pairs as context for prompting the LLM. If these few-shot samples are static, the downside is that they may not be the most relevant examples for the new input. Dynamic Few-shot Selection, the first component in Medprompt, helps overcome this by selecting the few-shot examples based on each new task input. This method involves training a K-Nearest Neighbors (K-NN) algorithm on the training set, which then retrieves the most similar training set examples to the test input based on cosine similarity in an embedding space. This strategy efficiently utilizes the existing training dataset to retrieve relevant few-shot examples for prompting the LLM. 少样本提示是指利用示例输入输出对作为LLM提示的上下文。如果这些少样本示例是静态的,缺点是它们可能不是新输入最相关的示例。Medprompt中的第一组件动态少样本选择通过根据每个新任务输入选择少样本示例来克服这一问题。这种方法涉及在训练集上训练K最近邻(K-NN)算法,然后根据嵌入空间中的余弦相似度检索出与测试输入最相似的训练集示例。这种策略有效利用现有训练数据集来检索LLM提示所需的相关少样本示例。
Sure, the translation of "Self-Generated CoT" to simplified Chinese while keeping HTML structure could look like this: ```html 自动生成的CoT ``` This preserves the structure and translates the text accordingly.
Sure, here is the HTML structure with the translated text in simplified Chinese: ```html
正如文献[1]所述,CoT传统上依赖于手工制作的少样本示例,其中包括详细的推理步骤,例如MedPaLM-2中医疗专业人员编写的提示。Medprompt引入了自动生成的CoT作为第二模块,其中语言模型用于生成其推理过程的详细逐步解释,最终得出最终答案选择。通过为每个训练数据点自动生成CoT推理步骤,可以避免手工制作示例的需要。为确保仅保留具有推理步骤的正确预测,并过滤掉错误响应,GPT-4生成的答案将与实际情况进行交叉验证。
``` Translated Text (Simplified Chinese): ```plaintext 正如文献[1]所述,CoT传统上依赖于手工制作的少样本示例,其中包括详细的推理步骤,例如MedPaLM-2中医疗专业人员编写的提示。Medprompt引入了自动生成的CoT作为第二模块,其中语言模型用于生成其推理过程的详细逐步解释,最终得出最终答案选择。通过为每个训练数据点自动生成CoT推理步骤,可以避免手工制作示例的需要。为确保仅保留具有推理步骤的正确预测,并过滤掉错误响应,GPT-4生成的答案将与实际情况进行交叉验证。 ``` This HTML snippet includes the translated text in simplified Chinese, maintaining the structure requested.Sure, here's the translation of "Choice Shuffling Ensemble" into simplified Chinese while keeping the HTML structure: ```html 选择混合组合 ``` In this HTML snippet, `选择混合组合` represents "Choice Shuffling Ensemble" translated into simplified Chinese.
Certainly! Here is the translated text in simplified Chinese, maintaining the HTML structure: ```html
Choice Shuffling Ensemble 技术是Medprompt引入的第三种技术。它旨在对抗可能影响模型决策过程的固有偏见,特别是在多选设置中的位置偏见。答案选择的顺序被随机打乱,这个过程重复k次,以创建k个相同问题的变体,每个变体的答案选择都被打乱。在推断过程中,使用每个变体生成一个答案,然后对所有变体执行多数投票,以选择最终预测的选项。
``` This HTML snippet contains the translated text in simplified Chinese as requested.Sure, here's the text translated into simplified Chinese while maintaining the HTML structure: ```html
在预处理和推断阶段中,这些组件如何被使用?
``` This HTML snippet translates to: "How are these components used in the preprocessing and inference stage?"在Medprompt中,现在让我们来看一下预处理和推理阶段。
Sure, the translation of "Preprocessing Stage" into simplified Chinese while keeping HTML structure intact would be: ```html
预处理阶段
``` In this HTML snippet, `` tags are used to denote a paragraph, enclosing the translated text "预处理阶段".
```html
在预处理流程中,我们首先从训练数据集中获取每个问题,并在提示中加入详细的指导说明,以引导生成答案及其相关推理步骤。语言模型被提示生成答案和推理步骤。获取生成的响应后,我们通过将预测的答案与该问题的真实答案进行比较来验证其准确性。
```
Sure, here's the translation in simplified Chinese while keeping the HTML structure intact: ```html 如果预测不正确,我们将从相关问题数据库中排除此实例。如果预测正确,我们将通过嵌入式文本模型嵌入问题。然后,我们将问题、问题嵌入、答案和思维链(CoT)推理存储在缓冲区中。一旦所有问题都被处理完毕,我们利用嵌入来训练一个KNN模型。这个训练好的KNN模型作为我们RAG流水线中的检索器,使我们能够基于嵌入空间中的余弦相似度高效地查询和检索前k个相似数据点。 ``` This HTML structure ensures that the translated text remains formatted and readable for technical contexts.
Sure, the translation of "Inference Pipeline" into simplified Chinese while keeping the HTML structure intact would be: ```html 推理管道 ```
Sure, here's the translation of your text into simplified Chinese while keeping the HTML structure: ```html 在推理阶段,我们首先使用文本嵌入模型对测试集中的每个问题进行嵌入。然后,我们利用KNN模型识别出前k个最相似的问题。对于每个检索到的数据点,我们可以访问自动生成的思维链(CoT)推理和预测的答案。我们将这些元素 — 问题、CoT推理和答案 — 格式化为我们最终提示的少样本示例。 ``` This translation preserves the meaning and structure of the original English text.

我们现在通过对每个测试题的答案选择顺序进行洗牌来执行选择混合集成,从而创建同一问题的多个变体。然后,LLM被提示使用这些变体以及相应的少样本示例来生成推理步骤和每个变体的答案。最后,我们对所有变体的预测进行多数投票,并选择最终的预测结果。
Sure, here is the translation of "Implementing Medprompt" into simplified Chinese, while keeping HTML structure: ```html 实施 Medprompt ```
在保留HTML结构的情况下,将以下英文文本翻译为简体中文: 这个实现相关的代码可以在这个 GitHub 仓库链接中找到。
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 我们使用MedQA [6]数据集来实施和评估Medprompt。我们首先定义了用于解析jsonl文件的辅助函数。 ``` This translation maintains the structure for incorporating into an HTML document, with the Chinese text wrapped in `` tags to indicate the language.
def write_jsonl_file(file_path, dict_list):
"""
Write a list of dictionaries to a JSON Lines file.
Args:
- file_path (str): The path to the file where the data will be written.
- dict_list (list): A list of dictionaries to write to the file.
"""
with open(file_path, 'w') as file:
for dictionary in dict_list:
json_line = json.dumps(dictionary)
file.write(json_line + '\n')
def read_jsonl_file(file_path):
"""
Parses a JSONL (JSON Lines) file and returns a list of dictionaries.
Args:
file_path (str): The path to the JSONL file to be read.
Returns:
list of dict: A list where each element is a dictionary representing
a JSON object from the file.
"""
jsonl_lines = []
with open(file_path, 'r', encoding="utf-8") as file:
for line in file:
json_object = json.loads(line)
jsonl_lines.append(json_object)
return jsonl_lines
Sure, here is the translation of "Implementing Self-Generated CoT" in simplified Chinese while keeping the HTML structure: ```html 实施自动生成的CoT ``` This translates the phrase directly into simplified Chinese characters, suitable for use in an HTML document.
Sure, here's the translated text in simplified Chinese while keeping the HTML structure intact: ```html
对于我们的实现,我们利用来自MedQA的训练集。我们实现了零射击CoT提示,并处理所有的训练问题。我们在实现中使用GPT-4o。对于每个问题,我们生成CoT和相应的答案。我们定义了一个基于Medprompt论文中提供的模板的提示。
``` This HTML snippet contains the translated text in simplified Chinese, structured as a paragraph (``).
system_prompt = """You are an expert medical professional. You are provided with a medical question with multiple answer choices.
Your goal is to think through the question carefully and explain your reasoning step by step before selecting the final answer.
Respond only with the reasoning steps and answer as specified below.
Below is the format for each question and answer:
Input:
## Question: {{question}}
{{answer_choices}}
Output:
## Answer
(model generated chain of thought explanation)
Therefore, the answer is [final model answer (e.g. A,B,C,D)]"""
def build_few_shot_prompt(system_prompt, question, examples, include_cot=True):
"""
Builds the zero-shot prompt.
Args:
system_prompt (str): Task Instruction for the LLM
content (dict): The content for which to create a query, formatted as
required by `create_query`.
Returns:
list of dict: A list of messages, including a system message defining
the task and a user message with the input question.
"""
messages = [{"role": "system", "content": system_prompt}]
for elem in examples:
messages.append({"role": "user", "content": create_query(elem)})
if include_cot:
messages.append({"role": "assistant", "content": format_answer(elem["cot"], elem["answer_idx"])})
else:
answer_string = f"""## Answer\nTherefore, the answer is {elem["answer_idx"]}"""
messages.append({"role": "assistant", "content": answer_string})
messages.append({"role": "user", "content": create_query(question)})
return messages
def get_response(messages, model_name, temperature = 0.0, max_tokens = 10):
"""
Obtains the responses/answers of the model through the chat-completions API.
Args:
messages (list of dict): The built messages provided to the API.
model_name (str): Name of the model to access through the API
temperature (float): A value between 0 and 1 that controls the randomness of the output.
A temperature value of 0 ideally makes the model pick the most likely token, making the outputs deterministic.
max_tokens (int): Maximum number of tokens that the model should generate
Returns:
str: The response message content from the model.
"""
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
在 HTML 结构中,我们还定义了用于解析语言模型响应中推理和最终答案选项的辅助函数。
def matches_ans_option(s):
"""
Checks if the string starts with the specific pattern 'Therefore, the answer is [A-Z]'.
Args:
s (str): The string to be checked.
Returns:
bool: True if the string matches the pattern, False otherwise.
"""
return bool(re.match(r'^Therefore, the answer is [A-Z]', s))
def extract_ans_option(s):
"""
Extracts the answer option (a single capital letter) from the start of the string.
Args:
s (str): The string containing the answer pattern.
Returns:
str or None: The captured answer option if the pattern is found, otherwise None.
"""
match = re.search(r'^Therefore, the answer is ([A-Z])', s)
if match:
return match.group(1) # Returns the captured alphabet
return None
def matches_answer_start(s):
"""
Checks if the string starts with the markdown header '## Answer'.
Args:
s (str): The string to be checked.
Returns:
bool: True if the string starts with '## Answer', False otherwise.
"""
return s.startswith("## Answer")
def validate_response(s):
"""
Validates a multi-line string response that it starts with '## Answer' and ends with the answer pattern.
Args:
s (str): The multi-line string response to be validated.
Returns:
bool: True if the response is valid, False otherwise.
"""
file_content = s.split("\n")
return matches_ans_option(file_content[-1]) and matches_answer_start(s)
def parse_answer(response):
"""
Parses a response that starts with '## Answer', extracting the reasoning and the answer choice.
Args:
response (str): The multi-line string response containing the answer and reasoning.
Returns:
tuple: A tuple containing the extracted CoT reasoning and the answer choice.
"""
split_response = response.split("\n")
assert split_response[0] == "## Answer"
cot_reasoning = "\n".join(split_response[1:-1]).strip()
ans_choice = extract_ans_option(split_response[-1])
return cot_reasoning, ans_choice
Sure, here is the translation of your English text into simplified Chinese while keeping the HTML structure: ```html
我们现在处理MedQA训练集中的问题。我们获取所有问题的CoT响应和答案,并将它们存储到一个文件夹中。
``` In this translation: - "我们现在处理MedQA训练集中的问题。" corresponds to "We now process the questions in the training set of MedQA." - "我们获取所有问题的CoT响应和答案,并将它们存储到一个文件夹中。" corresponds to "We obtain CoT responses and answers for all questions and store them to a folder." This HTML snippet will display the translated text in simplified Chinese.train_data = read_jsonl_file("data/phrases_no_exclude_train.jsonl")
cot_responses = []
# os.mkdir("cot_responses")
existing_files = os.listdir("cot_responses/")
for idx, item in enumerate(tqdm(train_data)):
if str(idx) + ".txt" in existing_files:
continue
prompt = build_zero_shot_prompt(system_prompt, item)
try:
response = get_response(prompt, model_name="gpt-4o", max_tokens=500)
cot_responses.append(response)
with open(os.path.join("cot_responses", str(idx) + ".txt"), "w", encoding="utf-8") as f:
f.write(response)
except Exception as e :
print(str(e))
cot_responses.append("")
请保持HTML结构,将以下英文文本翻译为简体中文: 我们现在遍历所有生成的回答,检查它们是否有效,并且是否符合在提示中定义的预测格式。我们会丢弃不符合所需格式的回答。之后,我们会将每个问题的预测答案与真实答案进行对比,只保留预测答案与真实答案匹配的问题。
questions_dict = []
ctr = 0
for idx, question in enumerate(tqdm(train_data)):
file = open(os.path.join("cot_responses/", str(idx) + ".txt"), encoding="utf-8").read()
if not validate_response(file):
continue
cot, pred_ans = parse_answer(file)
dict_elem = {}
dict_elem["idx"] = idx
dict_elem["question"] = question["question"]
dict_elem["answer"] = question["answer"]
dict_elem["options"] = question["options"]
dict_elem["cot"] = cot
dict_elem["pred_ans"] = pred_ans
questions_dict.append(dict_elem)
filtered_questions_dict = []
for item in tqdm(questions_dict):
pred_ans = item["options"][item["pred_ans"]]
if pred_ans == item["answer"]:
filtered_questions_dict.append(item)
Here is the translation while keeping the HTML structure: ```html 实现 KNN 模型 ```
To translate the given English text to simplified Chinese and maintain the HTML structure, you can use the following: ```html 在处理了训练集并获取了所有这些问题的CoT响应后,我们现在使用OpenAI的text-embedding-ada-002嵌入所有问题。 ``` This HTML snippet preserves the structure while providing the translated text in simplified Chinese.
def get_embedding(text, model="text-embedding-ada-002"):
return client.embeddings.create(input = [text], model=model).data[0].embedding
for item in tqdm(filtered_questions_dict):
item["embedding"] = get_embedding(item["question"])
inv_options_map = {v:k for k,v in item["options"].items()}
item["answer_idx"] = inv_options_map[item["answer"]]
我们现在使用这些问题嵌入来训练一个KNN模型。在推理时,这个模型充当检索器,帮助我们从训练集中检索与测试集中的问题最相似的数据点。
import numpy as np
from sklearn.neighbors import NearestNeighbors
embeddings = np.array([d["embedding"] for d in filtered_questions_dict])
indices = list(range(len(filtered_questions_dict)))
knn = NearestNeighbors(n_neighbors=5, algorithm='auto', metric='cosine').fit(embeddings)
Sure, here's the text translated to simplified Chinese while keeping the HTML structure: ```html 实施动态少样本和选择洗牌集成逻辑 ``` This HTML structure ensures the translated text maintains its integrity when integrated into a webpage or document.
Sure, here's the translated text in simplified Chinese, keeping the HTML structure intact: ```html 现在我们可以进行推理了。我们从MedQA测试集中抽取500个问题用于评估。对于每个问题,我们使用KNN模块从训练集中检索出5个最相似的问题,以及它们各自的CoT推理步骤和预测答案。我们利用这些示例构建一个少样本提示。 ``` This translation maintains the technical details and structure of the original English text while being presented in simplified Chinese.
在每个问题中,我们还会对选项的顺序进行5次随机排列,以创建不同的变体。然后,我们利用构建的少样本提示来获取每个具有随机排列选项的变体的预测答案。
def shuffle_option_labels(answer_options):
"""
Shuffles the options of the question.
Parameters:
answer_options (dict): A dictionary with the options.
Returns:
dict: A new dictionary with the shuffled options.
"""
options = list(answer_options.values())
random.shuffle(options)
labels = [chr(i) for i in range(ord('A'), ord('A') + len(options))]
shuffled_options_dict = {label: option for label, option in zip(labels, options)}
return shuffled_options_dict
test_samples = read_jsonl_file("final_processed_test_set_responses_medprompt.jsonl")
for question in tqdm(test_samples, colour ="green"):
question_variants = []
prompt_variants = []
cot_responses = []
question_embedding = get_embedding(question["question"])
distances, top_k_indices = knn.kneighbors([question_embedding], n_neighbors=5)
top_k_dicts = [filtered_questions_dict[i] for i in top_k_indices[0]]
question["outputs"] = []
for idx in range(5):
question_copy = question.copy()
shuffled_options = shuffle_option_labels(question["options"])
inv_map = {v:k for k,v in shuffled_options.items()}
question_copy["options"] = shuffled_options
question_copy["answer_idx"] = inv_map[question_copy["answer"]]
question_variants.append(question_copy)
prompt = build_few_shot_prompt(system_prompt, question_copy, top_k_dicts)
prompt_variants.append(prompt)
for prompt in tqdm(prompt_variants):
response = get_response(prompt, model_name="gpt-4o", max_tokens=500)
cot_responses.append(response)
for question_sample, answer in zip(question_variants, cot_responses):
if validate_response(answer):
cot, pred_ans = parse_answer(answer)
else:
cot = ""
pred_ans = ""
question["outputs"].append({"question": question_sample["question"], "options": question_sample["options"], "cot": cot, "pred_ans": question_sample["options"].get(pred_ans, "")})
Sure, here's the HTML structure with the translated text in simplified Chinese: ```html
我们现在评估Medprompt在测试集上的结果。对于每个问题,我们通过集成逻辑生成了五个预测。我们取每个问题的众数(即最频繁出现的预测)作为最终预测并评估性能。在这里可能存在两种边缘情况:
``` This HTML snippet preserves the structure while displaying the translated text in simplified Chinese.- Sure, here's the translation of the text into simplified Chinese while keeping the HTML structure: ```html 两个不同的答案选项各预测两次,没有明确的赢家。 ``` In this HTML snippet, the Chinese text is preserved within the `` tag to indicate the language for translation purposes.
- To translate the English text "There is an error with the response generated, meaning that we don’t have a predicted answer option." into simplified Chinese while maintaining HTML structure, you can use the following:
```html
响应生成时出现错误,这意味着我们没有预测的答案选项。
``` This HTML snippet preserves the structure and simply replaces the English text with its corresponding Chinese translation.
Sure, here is the translated text in simplified Chinese while keeping the HTML structure: ```html 对于这两种边缘情况,我们认为LLM的答案是错误的。 ``` This HTML structure preserves the original text and adds the Chinese translation within it.
def find_mode_string_list(string_list):
"""
Finds the most frequently occurring strings.
Parameters:
string_list (list of str): A list of strings.
Returns:
list of str or None: A list containing the most frequent string(s) from the input list.
Returns None if the input list is empty.
"""
if not string_list:
return None
string_counts = Counter(string_list)
max_freq = max(string_counts.values())
mode_strings = [string for string, count in string_counts.items() if count == max_freq]
return mode_strings
ctr = 0
for item in test_samples:
pred_ans = [x["pred_ans"] for x in item["outputs"]]
freq_ans = find_mode_string_list(pred_ans)
if len(freq_ans) > 1:
final_prediction = ""
else:
final_prediction = freq_ans[0]
if final_prediction == item["answer"]:
ctr +=1
print(ctr / len(test_samples))
评估表现
Sure, here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html 我们在MedQA测试子集上使用GPT-4o评估Medprompt的准确性表现。此外,我们还对零提示、随机少样本提示以及随机少样本与CoT提示的性能进行了基准测试。 ``` This translates the original English text into Chinese, maintaining the HTML structure for easy integration into a web page or document.
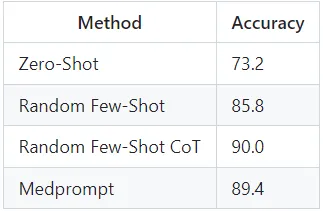
在保持HTML结构的情况下,将以下英文文本翻译为简体中文: 我们观察到Medprompt和Random Few-Shot CoT提示方法表现优于零和少样本提示基线。然而令人惊讶的是,我们注意到Random Few-Shot CoT的表现优于我们的Medprompt。这可能有几个原因:
- Sure, here's the simplified Chinese translation of the text:
```html
The original Medprompt paper benchmarked the performance of GPT-4. We observe that GPT-4o outperforms GPT-4T and GPT-4 on various text benchmarks significantly (https://openai.com/index/hello-gpt-4o/), indicating that Medprompt could have a lesser effect on a stronger model like GPT-4o.
``` In Simplified Chinese: ```html原始的Medprompt论文评估了GPT-4的性能。我们观察到,GPT-4o在各种文本基准测试中显著优于GPT-4T和GPT-4(https://openai.com/index/hello-gpt-4o/),表明Medprompt可能对像GPT-4o这样更强的模型影响较小。
``` - 请注意,以下是将给定的英文文本翻译为简体中文后的HTML结构代码:
```html
我们将评估限制在从MedQA中抽样的500个问题上。Medprompt论文评估了其他医学多项选择问题(MCQA)数据集和MedQA的完整版本。在数据集的完整版本上评估GPT-4o可以更好地了解总体表现。
``` 这段HTML代码包含了翻译后的简体中文文本,同时保留了原有的HTML结构。
Sure, the translation of "Conclusion" into simplified Chinese while keeping HTML structure intact would be: ```html 结论 ``` This HTML snippet ensures that "结论" is displayed in simplified Chinese characters, maintaining proper structure for web content.
Sure, here is the simplified Chinese translation of the text you provided, formatted in an HTML structure: ```html
Medprompt 是一个有趣的框架,用于创建复杂的提示管道,特别适用于将通用语言模型适应特定领域而无需进行精细调整。它还突出了在不同使用案例中决定使用提示还是精细调整所涉及的考虑因素。探索推动提示技术以提升语言模型性能的极限是非常重要的,因为它提供了一种资源和成本效益高的精细调整替代方案。
``` This HTML structure maintains the content while providing the translation in simplified Chinese.Sure, the translation of "References:" to simplified Chinese while keeping the HTML structure intact would be: ```html 参考文献: ``` This HTML code ensures the text "参考文献:" (which means "References:" in English) is displayed correctly in a web page, maintaining both the translation and the appropriate language markup.
Sure, here's the HTML structure for the translated text in simplified Chinese: ```html
Nori, H., Lee, Y. T., Zhang, S., Carignan, D., Edgar, R., Fusi, N., … & Horvitz, E. (2023). Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452.
``` And the translated text in simplified Chinese is: ```htmlNori, H., Lee, Y. T., Zhang, S., Carignan, D., Edgar, R., Fusi, N., … & Horvitz, E. (2023)。广义基础模型能否在医学案例研究中击败特定目的的调整?arXiv 预印本 arXiv:2311.16452。
``` This HTML structure maintains the link to the original arXiv preprint and correctly formats the Chinese translation of the citation.Sure, here is the translated text in simplified Chinese while maintaining HTML structure: ```html [2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). 链式思维提示引发大型语言模型的推理能力. Advances in Neural Information Processing Systems, 35, 24824–24837. (链接) ```
Sure, here is the HTML structure with the translated text in simplified Chinese: ```html
[3] Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). Fine-Tuning LLMs on New Knowledge Encourages Hallucinations?. arXiv预印本 arXiv:2405.05904. (链接)
``` Translated text in Simplified Chinese: ```html[3] Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). 在新知识上微调LLM是否会鼓励产生幻觉?. arXiv预印本 arXiv:2405.05904. (链接)
``` This HTML structure preserves the citation format and includes the translated title in Simplified Chinese.To keep the HTML structure intact while translating the citation to simplified Chinese, you can use the following format: ```html
[4] Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., … & Natarajan, V. (2023). 大语言模型编码临床知识. Nature, 620(7972), 172–180. (https://www.nature.com/articles/s41586-023-06291-2)
``` This HTML snippet maintains the citation in English while the title and the translated part (大语言模型编码临床知识) are in simplified Chinese. The link to the article remains functional within the anchor tag.To translate the citation into simplified Chinese while keeping the HTML structure intact, you can use the following: ```html [5] Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., … & Natarajan, V. (2023). Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617. (https://arxiv.org/abs/2305.09617) ``` Here is the simplified Chinese translation of the citation: ```html [5] Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., … & Natarajan, V. (2023). 朝向大语言模型进行专家级医学问题回答。 arXiv 预印本 arXiv:2305.09617。 (https://arxiv.org/abs/2305.09617) ``` This HTML code preserves the structure and formatting while presenting the citation in simplified Chinese.
Sure, here's the HTML structure with the translated text in simplified Chinese: ```html
[6] 金大慷, 潘恩凯, 欧法托勒, 翁伟华, 方辉, Szolovits, P. (2021). 这位患者患有什么疾病?来自医学考试的大规模开放领域问答数据集. 应用科学, 11(14), 6421. (https://arxiv.org/abs/2009.13081) (原始数据集根据MIT许可发布)
``` In this HTML snippet: - `` denotes a paragraph tag, containing the translated citation and information. - The Chinese characters are simplified Chinese, suitable for readers who use that script.