Sure, here's the text "GPT 1 explained!" translated to simplified Chinese while keeping the HTML structure: ```html GPT 1 解析! ``` In this translation: - `` is used to wrap the text, assuming it's within a larger HTML context. - "GPT 1 解析!" is the simplified Chinese translation of "GPT 1 explained!".
这是OpenAI的论文《通过生成预训练提高语言理解》的摘要。尽管未标记的文本数据丰富,但标记数据的稀缺使得通过判别训练的模型在NLP任务上表现不佳。因此,论文建议在多样化的未标记文本语料库上进行语言模型的生成预训练,然后在每个特定任务上进行判别微调,以获得比针对每个任务特别设计的架构的判别训练模型显著更好的结果。
```html
大多数深度学习方法需要大量手动标记的数据才能有效地从原始文本中学习。在这些情况下,能够利用未标记数据中的语言信息的模型,为收集更多耗时且昂贵的注释数据提供了一种有价值的替代方案。然而,从未标记文本中利用超过单词级别的信息具有两个主要挑战。首先,目前尚不清楚哪种优化目标最有效地学习文本表示,并且没有有效的方法将这些学习到的表示转移到目标任务上。因此,本文建议采用半监督方法来处理语言理解任务,结合无监督预训练和监督微调,旨在学习一个通用表示,可以在很少适应的情况下转移到各种任务中。
``````html
首先,GPT 1 使用语言建模目标在未标记数据上学习神经网络模型的初始参数,并使用相应的监督目标将这些参数调整到目标任务中。所使用的模型架构是Transformer架构,该架构在Google的论文“注意力机制是一切你需要的”中首次提出。与循环网络等替代方案相比,Transformer为处理文本中的长期依赖关系提供了更结构化的记忆。
```Sure, here is the translation of your text into simplified Chinese while keeping the HTML structure intact: ```html 训练过程包括两个阶段。第一阶段是在大规模无标签文本语料库上学习高容量语言模型,随后是微调阶段,模型根据带标签数据适应于一个区分性任务。对于无监督预训练,使用标准语言建模目标来最大化以下似然性。 ``` This HTML text preserves the structure and formatting for use in web content or documents where maintaining HTML is necessary.
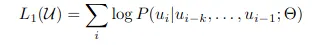
```html 在这里,k 是上下文窗口的大小,条件概率 P 是使用具有参数 Θ 的神经网络建模的,这些参数是使用随机梯度下降进行训练的。多层Transformer解码器用于语言模型,这是Transformer的一种变体。该模型对输入上下文标记应用多头自注意操作,然后是逐位置前馈层,以产生目标标记的输出分布。如果您对详细了解Transformer架构感兴趣,请查看我的解释: ```
Sure, here is the translation in simplified Chinese, while maintaining HTML structure: ```html 在无监督训练后,参数被调整以适应监督目标任务。标记数据的输入通过预训练模型传递,以获取最终的Transformer块激活 hl(m),然后将其馈送到带有参数 W(y) 的新增线性输出层以预测 y。 ``` This HTML snippet preserves the original structure while providing the translated text in simplified Chinese.
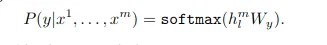
```html 某些任务如问答具有结构化输入,例如有序的句子对或文档、问题和答案的三元组。由于预训练模型是在连续文本序列上训练的,因此需要进行一些修改才能将其应用于这些任务。因此,采用了遍历式的方法,将结构化输入转换为预训练模型可以处理的有序序列。这些输入转换允许在各个任务之间避免对架构进行广泛修改,这是迁移学习的关键。 ```
以下是对BooksCorpus数据集进行训练的语言模型的描述:该数据集包含来自多种流派(包括冒险、奇幻和浪漫等)的超过7,000本独特且未发表的书籍。正如前文所述,该模型主要基于原始的Transformer结构,即一个仅有12层解码器的Transformer,具有掩码自注意力头。实验涉及四种类型的语言理解任务:自然语言推断、问答、语义相似度和文本分类。
```html
自然语言推理(NLI)的任务包括阅读一对句子,并判断它们之间的关系,可以是蕴涵、矛盾或中立关系。该方法在五个数据集中的四个上明显优于基准线,分别在MNLI上提高了最高达1.5%,在SciTail上提高了5%,在QNLI上提高了5.8%,在SNLI数据集上提高了0.6%。在问答和常识推理方面,它比以往的最佳结果显著提高 — 在Story Cloze上高达8.9%,在RACE数据集上整体提高了5.7%。在语义相似性和文本分类方面,也在各种数据集上获得了类似的结果。如果您对具体的基准感兴趣,我在文末附上了论文链接。
``` This HTML snippet retains the structure while displaying the translated text in simplified Chinese.Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html 为了理解为什么变压器的语言模型预训练是有效的,提出了一个假设:生成模型在预训练期间学习了许多任务,以提高其语言建模能力。变压器的结构化注意力记忆进一步有助于比LSTM更有效地进行迁移。启发式解决方案利用生成模型创建,以执行无监督微调的任务,结果表明这些启发式方法稳步改进,表明生成式预训练有助于学习各种任务相关功能。 ``` This translation maintains the original structure and meaning while adapting it to simplified Chinese.
Here is the translated text in simplified Chinese, keeping the HTML structure intact: ```html
总之,GPT 1 提供了一个框架,通过生成式预训练和单一模型的判别性微调,实现了强大的自然语言理解能力。通过在多样化语料库上进行长段连续文本的预训练,该模型获得了显著的知识和处理长期依赖的能力,这些能力随后成功地转移到解决判别性任务,例如问答、语义相似度评估和文本分类。
```References:
1. https://arxiv.org/pdf/2205.02302