Sure, here's the translated text in simplified Chinese: "提示结构能改善输出质量吗?使用GPT-4、Claude 3和Gemini 1.5测试零射击提示"
Sure, here's the translated text in simplified Chinese: ```html
你已经通过多次迭代,通过改进和批评第一版,掌握了从ChatGPT获取高质量文本的技巧吗?如果你需要重复解决类似任务,而没有时间阅读大量版本并批评它们呢?如果你想与尚未有效“引导”AI的同事分享你的提示呢?
```Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
让我们探索如何在上述情况下为大型语言模型(LLMs)创建指令:
```- Sure, here's the translation: 如何编写不需要后续澄清的提示。
- Sure, here's the translation: 如何在此花费更少时间。
Sure, here's the translated text: ```html 我进行了实验,比较了几个零样本提示的版本,以以下问题为例:会议记录分析和基于标准的评估。此处可以找到与少样本提示的比较。 ```
Sure, here's the HTML structure with the translated text in simplified Chinese: ```html
本文的重点是关注这个特定任务的输出质量,而不是像LLM基准测试中所看到的“在许多任务中的正确答案的百分比”。
```Sure, here's the translated text in simplified Chinese: ```html
第三部分
以下是对四个流行LLM进行的实验结果:GPT-4,Gemini 1.5 Pro,Claude 3 Sonnet和Claude 3 Opus。在这个特定任务中,GPT-4和Opus处于领先地位。然而,文章的要点不在于当前哪些模型处于领先地位。这并不重要,因为未来发布的新模型将改变排行榜。
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html
我认为另一个问题更为重要:
```Sure, here's the translated text in simplified Chinese while maintaining the HTML structure: ```html 如何在第一次尝试中确保高质量输出的同时节省时间? ```
Sure, here's the translation: 我们是否可以不使用诸如结构化长提示之类的提示工程技术?

Sure, here's the translation in simplified Chinese while keeping the HTML structure:
```html
提示学习
```
Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html
让我们来看一个旨在分析会议记录的提示,根据特定标准提供评估,并提出改进建议。这样的任务可以极大地帮助经理、导师和其他经常在工作中举行会议的人。
```以下是用于分析日常会议(每日站会)的提示的不同版本。这个提示对Scrum Master和敏捷教练特别有用。它为用户提供了评估会议质量的七个标准准则列表,可以通过缩短或扩展列表来调整。该提示应为每个准则提供评分(在10分制下),对每个评分提供详细解释,并向Scrum Master提出建议(仅针对评分低于9的情况)。
Sure, here's the translation: ```html 1.1. 简要提示 ```
让我们从尽可能简短地描述任务开始。
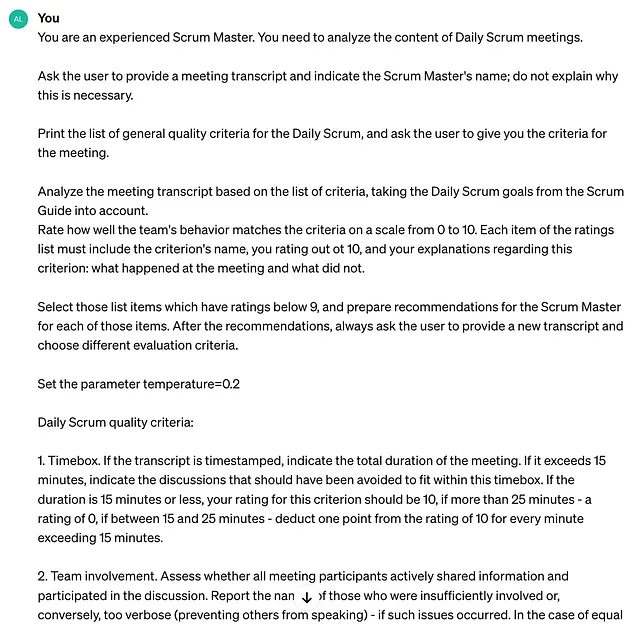
Sure, here's the translation: 即使在这个简短的提示中,会议评估标准也被详细描述,因为它们在文章中没有被研究。 不同版本的提示具有完全相同的标准,但在其他方面有所不同。
Sure, here is the translation in simplified Chinese while maintaining the HTML structure:
```html
1.2. 无结构的详细提示
```
以下,让我们提供更详细的说明,同时避免任何结构元素或文本格式。
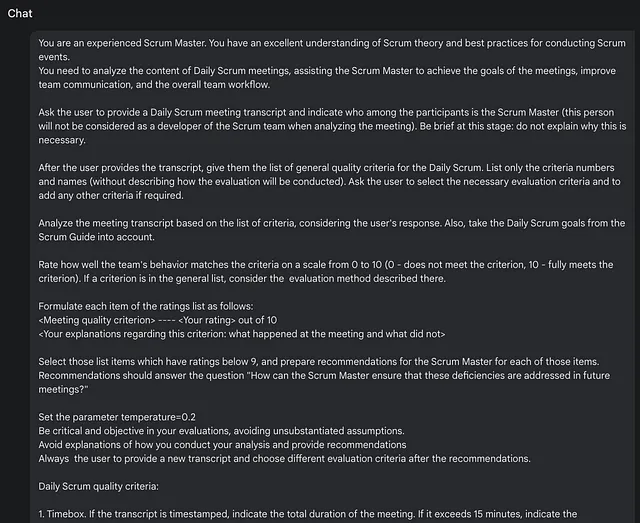
Sure, the translation of "1.3. Structured Detailed Prompt" into simplified Chinese while keeping the HTML structure could be: ```html 1.3. 结构化详细提示 ```
Sure, here's the translated text in simplified Chinese, maintaining the HTML structure: ```html
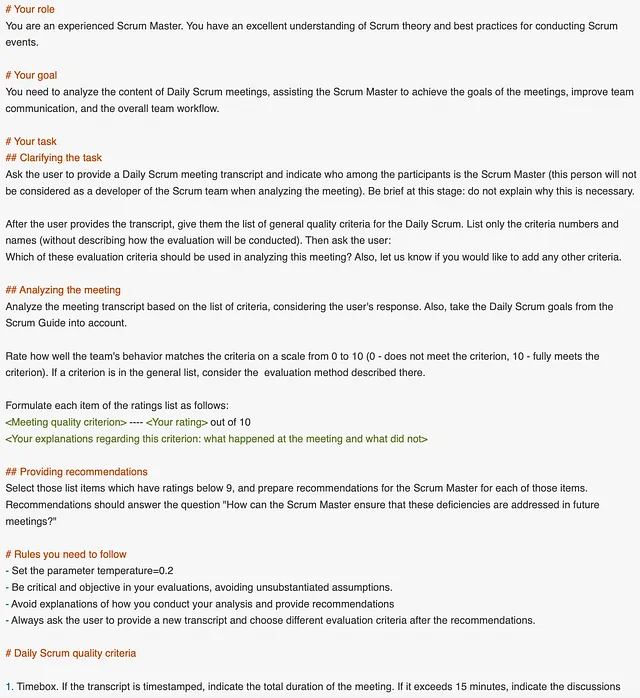
有一个合理的信念,长文本没有分隔符、列表或标题会更难以理解模型。因此,在提示的第三版中,让我们添加列表和标题,而不改变第二版的内容:
```
Sure, here's the translation in simplified Chinese, keeping the HTML structure: ```html
在这种情况下,使用Markdown格式化:标题用井号(#)标记,列表项用短横线标记。然而,格式并不是必要的;尖端的LLM(大型语言模型)无论特定格式如何都会产生类似的输出(甚至可能完全忽略格式,如下文所述)。
```Sure, here's the translation: ```html 1.4. 逐步说明 ```
Sure, here's the translated text in simplified Chinese within the HTML structure: ```html 如果我们希望人工智能按顺序执行多个动作(尤其是当某些动作是有条件的),将任务分解为单个步骤是合乎逻辑的。以下是实施的方法: ```
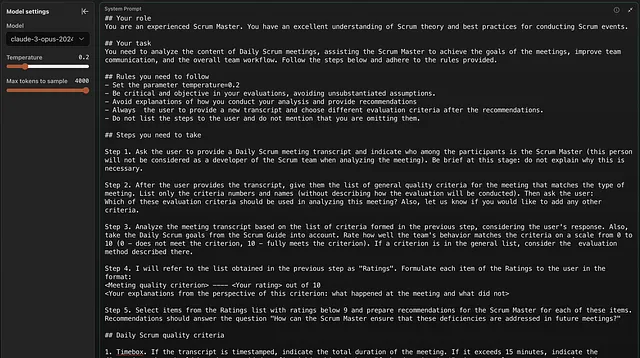
Sure, here is the translated text: ```html
正如我们所看到的,通过逐步详细说明,提示的大小已经显著增长。产出是否能够证明这样的大小和复杂性,仍然是一个需要实验验证的问题。更大的提示可能会让模型困惑,而不是帮助其实现期望的结果。
```Sure, here is the translation in simplified Chinese, while keeping the HTML structure:
```html
实验描述
```
Sure, here's the translated text in simplified Chinese within an HTML structure: ```html
我们将会比较上面显示的四个提示:
```- Sure, here is the translated text:
```html
简要提示:210个令牌。除了简要的角色分配(“您是一名经验丰富的Scrum大师”)外,它不使用任何提示工程技术。特别是,它不指定输出中评分的格式。
``` - Sure, here's the translated text in simplified Chinese, keeping the HTML structure:
```html
```
非结构化详细提示:406个标记。它包含与下两个版本相同的单词,但缺乏结构(无标题或列表)。
- ```html
结构详细提示 结构详细提示
461个令牌。它由标题标记的部分组成,还有一个“规则”列表,但没有编号的步骤。
``` - ```html
逐步详细提示:520个令牌。除了部分之外,它提供了明确的步骤。
```
以下是每个提示都包含相同的会议质量标准列表,指明如何获得分数并编写解释。这将使每个提示的总大小增加560个标记。
Sure, here's the translated text in simplified Chinese, while preserving the HTML structure:
```html
输入和参数
```
在每个实验中,会对三个会议记录进行测试(长度和质量各不相同)的提示。除了这些记录外,还包括以下输入数据:
- Sure, here's the translation in simplified Chinese: 会议1:使用所有标准进行评估。
- 会议2:使用标准3-7进行评估。
- 会议3:要求在评分说明中提及参与者的姓名。
```html
在所有实验中,参数 temperature=0.2 用于限制大型语言模型(LLM)的“创造力”。然而,并非所有模型都能很好地响应提示中设置的温度值。
```Sure, here is the translation in simplified Chinese while keeping the HTML structure intact: ```html 2.2. 输出质量度量指标 ```
Sure, here is the translation of the text into simplified Chinese, keeping the HTML structure: ```html 下一部分将根据“缺陷数量”介绍实验结果。通常,当模型在某些方面未遵循提示(可能对用户很重要)或文本缺少细节时,会发生缺陷。缺陷的示例包括:“解释不包含参与者姓名”,“模型为高评分提供建议”(或者相反,对低评分不提供建议),“建议缺乏具体行动”,“结尾没有建议提供另一份文本转录。” ```
以下是一个详细的表格,显示了每个输出的缺陷。
以下值得注意的是,LLMs 的性质是概率性的:它们在相同的上下文中连续运行时可能会产生略有不同的输出,即使温度=0。在相同模型、相同数据的情况下,同一提示版本的两次运行的输出有时可能会相差2倍甚至更多(使用上述指标)。在下面的分析中,这种影响部分得到了缓解,因为每个模型都对三个文本进行了分析。
Sure, here's the translated text in simplified Chinese: ```html
在运行次数较少的情况下,很难对提示之间的差异做出统计学上显著的结论。然而,我们将这样的发现留给研究人员。
```Sure, here's the translation: ```html
Sure, here's the translation in simplified Chinese: ```html 3. 实验结果:提示比较 ```
实验使用五种模型进行了。
- 在谷歌AI工作室应用程序中的Gemini 1.5 Pro。
- ```html
GPT-3.5在ChatGPT应用程序中。这个较旧模型的结果揭示了在过去一年中LLMs已经改进了多少。
``` - Sure, here's the translated text in simplified Chinese:
```html
GPT-4在ChatGPT应用程序中,特别是通过自定义GPT(指示是在系统提示中提供而不是在第一条聊天消息中)。```
- Sure, here's the translation in simplified Chinese:
```html
```Claude 3 Sonnet在claude.ai应用程序中。
- Sure, here's the translation in simplified Chinese while keeping the HTML structure:
```html
Claude 3 Opus 没有应用程序,直接通过 API,特别是通过 console.anthropic.com(提示作为系统提示给出,并且温度已明确设置)。
```
为什么我提到了用来访问LLM的应用程序?本文旨在面向AI应用的用户而不是开发人员。应用程序可以影响传递给LLM的上下文。然而,在实践中,这仅在上下文大小接近模型最大限制时影响输出,导致应用程序修剪上下文(例如,通过总结上下文的部分)。在我的实验中,聊天的总上下文大小约为8,500个令牌,这显然比这些模型的最大上下文窗口要小得多。
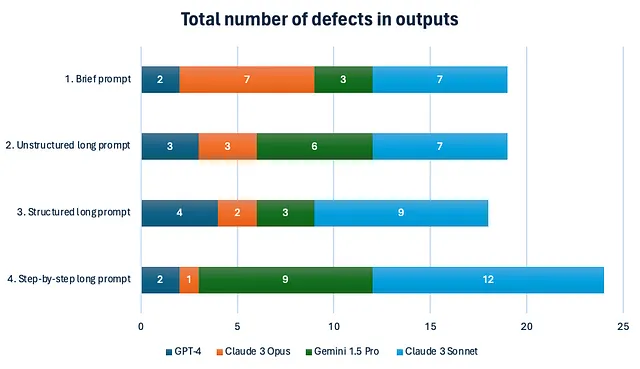
这里是结果:
Sure, here's the translated text in simplified Chinese, while maintaining the HTML structure: ```html
最显著的发现是最短提示 #1 的出色表现。除了 GPT-3.5 外,其他模型对于这个提示平均只产生了 4.8 个缺陷,与详细提示 #2 相同。
```这也值得注意的是,在所有模型中,结构化和非结构化的长提示之间没有显著差异。换句话说,添加标题和项目符号对现代大型语言模型没有影响——它们可以理解文本的结构而不依赖于此。
Sure, here's the translated text in simplified Chinese: ```html
请参考下表,了解更详细的提示比较,包括平均缺陷数量以及我对制作提示所花费的努力的评估。如果您使用移动设备,请点击表格行以查看完整数据集(包括 GPT-3.5 的结果,因为它们与其他模型相比太差)。
```Sure, here's the text translated into simplified Chinese: ```html 要查看与模型的提示的完整聊天文本,请单击此表中的单元格。 ```
Sure, here's the translation in simplified Chinese: 4. 关于为任务选择合适的模型的几句话
Certainly, here's the translated text within the HTML structure: ```html
正如我在介绍中提到的那样,你不应该根据这样简单的实验来得出关于模型总体质量的结论。要得出这样的结论,需要基于数千次跨越广泛任务的评估的综合性LLM基准。
```Sure, here's the translation in simplified Chinese while keeping the HTML structure intact: ```html
特别是,您不应假设 Gemini 1.5 Pro 在第 3 节中导致较少“缺陷”的模型较差。就个人而言,我更喜欢 Gemini 的具体解释——关于会议上发生了什么——与 GPT-4 更一般性的解释相比。
```不同于每个型号的缺陷总数,学习特定的缺陷对我的工作非常有帮助。现在我在选择不同任务的型号时可以做出更加明智的决策。例如:
- Sure, here's the translation:
```html
如果我需要一个完全按照长提示的模型,Claude 3 Opus 目前是最好的选择。
``` - Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html 如果我想从长篇文章中提取特定的事实,我主要会考虑Gemini。 ```
- Sure, here's the translation in simplified Chinese, while keeping the HTML structure:
```html
如果我没有时间详细描述我的需求,我更喜欢 GPT-4,它经常推断并“填补”用户需求。
```
在网页结构保持不变的情况下,将以下英文文本翻译为简体中文: 为了获得类似的理解,你可能也会发现我的缺陷表格有用。
Sure, here's the translation: ```html 5. 结论 ```
Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html
实验表明,使用简短提示往往会产生与结构化提示输出一样好的结果,而结构化提示的字数是简短提示的两倍。
```Sure, here's the translation: ```html 所以,当我们打算写一份包含所有对任务的思考的长提示时,我们应该克制自己: ```
- Sure, here is the translated text in simplified Chinese:
```html
向提示中添加“步骤1”,“步骤2”等内容是相当冒险的。LLM不是一个程序,它可能会被连续的步骤搞混。此外,模型可能会开始向用户写步骤,这通常看起来很奇怪。
``` - ```html 然而,两个最佳模型——gpt-4-turbo-2024–04–09 和 claude-3-opus-20240229——非常擅长处理包含多个步骤的更大提示。所以如果你喜欢分步思考,你可以为 GPT-4 和 Opus 写出逐步说明。然而,不要依赖此作为质量改进策略,因为你可以节省时间而不用描述步骤来获得相同的质量。 ```
- Sure, here's the translated text in simplified Chinese, while keeping the HTML structure:
```html
大多数模型“不喜欢”更大的提示。只有Claude 3 Opus对提示大小的增加做出积极回应(尽管这一观察需要通过重复实验进行验证)。
```

有趣的是,Claude 3 Opus 在遵循(详细)提示方面是最好的,特别是与 Open AI 模型相比,后者倾向于概括,偏离提示,并展现出他们的“创造力”。然而,GPT-4 对最简短的提示理解得非常好,与 Opus 不同。显然,模型的缺点是其优点的反面。
当然,本文的定量结果适用范围较窄。该范围是“按照标准进行的文本分析”,涉及相对复杂的逻辑,因此提示内容较多(即使最短的提示#1也相当大,约200字)。
Sure, here's the translation: 如果你正在寻找更广泛范围的人工智能输出质量比较研究,我建议查看梅根·斯卡尔贝克(Megan Skalbeck)的提示测试方法论。
可以,使用这种方法可能会非常昂贵,尤其是因为测试必须针对每个新的LLM版本重复进行。因此,这只对研究人员和那些开发基于人工智能的商业产品的人有意义。
Sure, here's the translated text: ```html
对于我们这些人工智能用户来说,了解在不同情况下哪些提示工程技术会带来价值的一般建议就足够了。这可以帮助我们节省时间,避免使用不必要的技术。
```Sure, here is the translation of the text to simplified Chinese: 希望本文为您提供了这样的建议。如果您在工作中注意到完全不同的LLM行为,请在评论中分享您的想法。例如,步骤说明导致更高质量输出的情况会很有趣。
这是本文的第二部分: