探索LLMs用于ICD编码 —— 第1部分
Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html
使用LLMs构建自动化临床编码系统
```Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html
临床编码并不是常见的用语,但它在大多数国家影响着与医疗系统互动的每个人。临床编码涉及将患者健康记录中的医疗信息,如诊断和程序,转换和映射为标准化的数字或字母数字代码。这些代码对于计费、医疗分析和确保患者接受适当治疗至关重要。
``` This HTML snippet contains the translated text in simplified Chinese.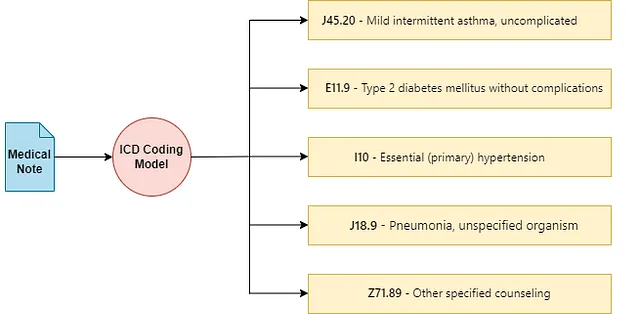
Sure, here's the translation of the provided text into simplified Chinese while keeping the HTML structure: ```html
临床编码通常由具有医学专业知识的人类编码员执行。 这些编码员使用特定的代码导航复杂且常层次化的编码术语,用于广泛范围的诊断和程序。 因此,编码员必须对所使用的编码术语有深入的了解和经验。 但是,手动编码文件可能会很慢,容易出错,并且受到对大量人类专业知识的要求的限制。
``` You can copy and paste this HTML structure into your project or document.Sure, here's the translated text in simplified Chinese, formatted in HTML: ```html
深度学习在自动化临床编码方面可以发挥重要作用。通过自动提取和翻译复杂的医疗信息为编码,深度学习系统可以作为人与系统互动中的有价值工具。它们能够通过快速处理大量数据来支持编码员,潜在地提高速度和准确性。这有助于简化行政运营、减少账单错误,并提升患者护理结果。
``` This HTML snippet contains the translated text in simplified Chinese while maintaining the structure for web display.Here's the translated text in simplified Chinese: 在本部分中,我描述了什么是ICD编码,表征了自动编码系统必须克服的各种挑战。我还分析了大型语言模型(LLMs)如何有效地用于克服这些问题,并通过实施一篇最近的论文中利用LLMs有效地进行ICD编码的算法来加以说明。
Sure, here's the translation: ``` 目录: ```
- Sure, here's the translation in simplified Chinese, keeping the HTML structure:
```html
什么是ICD编码?
``` - Sure, here is the text translated into simplified Chinese while keeping the HTML structure intact: ```html 什么是自动ICD编码中的挑战? ``` This HTML snippet will display the text "什么是自动ICD编码中的挑战?" on the webpage.
- Sure, here's the translation:
```html
LLMs 如何帮助自动 ICD 编码?
``` - Sure, here's the translated text in simplified Chinese, while keeping the HTML structure:
```html
探索论文“使用现成的大型语言模型进行自动临床编码”
``` - Sure, here's the translated text:
```html
在论文中描述的技术实现
``` - 结论
- References 参考资料
Sure, here's the translation of "What is ICD Coding?" in simplified Chinese while keeping the HTML structure intact: ```html
什么是ICD编码?
```Sure, here's the translation in simplified Chinese, maintaining the HTML structure: ```html
国际疾病分类(ICD)编码是由世界卫生组织开发和维护的临床术语系统[1]。它被用于大多数国家对患者记录的所有诊断、症状和程序进行分类和编码。
```医疗记录,记录了患者的诊断和医疗程序,对于ICD编码至关重要。ICD术语具有层次结构,类似树形结构,能够有效地组织大量信息,约有75,000个可用于各种医疗状况和诊断的可分配代码。准确编码这些文档至关重要;准确的编码确保适当的计费,并影响医疗保健分析的质量,直接影响患者护理结果、报销和医疗保健效率。
Sure, here's the translated text in simplified Chinese:
```html
自动ICD编码中的挑战是什么?
```
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html
ICD编码面临多重挑战,自动化系统必须克服这些挑战才能发挥有效作用。
```在ICD编码中的标签多样性:
在 HTML 结构中保持,将以下英文文本翻译为简体中文: 一个重要的挑战是标签的广泛输出空间。ICD 编码众多,每个编码在细微细节上可能不同 — 例如,影响右手与左手的情况将具有不同的编码。此外,存在一长尾罕见编码,它们在医疗记录中很少出现,这使得深度学习模型难以学习和准确预测这些编码,因为示例稀缺。
适应新的ICD代码:
Sure, here's the translated text: 用于训练的传统数据集,如 MIMIC-III [2],虽然全面,但通常将 ICD 编码的范围限制在训练语料库中包含的范围内。这种限制意味着将ICD编码视为从医疗记录到ICD编码的多标签分类问题的深度学习模型在模型训练后难以处理引入ICD系统的新编码。这使得重新训练成为必要且可能具有挑战性的任务。
提取和情境化信息:
Sure, here's the translated text in simplified Chinese: ```html
另一个重大挑战是从医疗笔记中准确提取和上下文化信息。ICD编码基本上是一个信息检索问题,不仅需要识别医疗记录中的诊断,还需要捕获所有必要的补充信息,以便正确地将这些诊断映射到其相应的ICD编码。因此,对于自动化系统来说,从医疗记录中提取各种医疗诊断并适当地将它们上下文化是至关重要的,以确保准确映射到ICD编码。
```
Sure, here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html
这里的“情境化”是什么意思?在处理医疗记录时,情境化诊断意味着将其与所有相关细节联系起来,比如受影响的身体部位和病情症状,以充分描述诊断情况。通常,这个任务被称为关系提取。
``` Would you like any modifications or additions?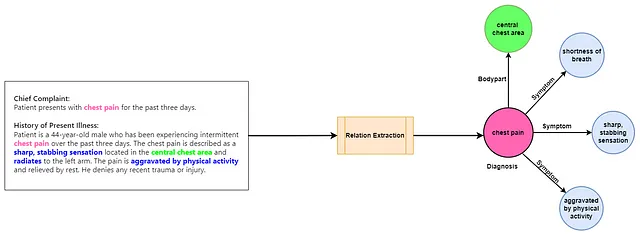
Sure, here's the translated text in simplified Chinese: ```html
LLM(大型语言模型)如何帮助自动ICD编码?
```在解决自动ICD编码的挑战时,大型语言模型(LLMs)处于有利位置,特别是由于它们对新标签的适应性以及它们处理复杂信息提取任务的能力。然而,这里的重点不是争论LLMs是否是自动ICD编码的最佳解决方案,或者这些只有LLMs才能解决的问题。相反,通过确定自动ICD编码系统必须克服的一些主要挑战,我分析了如何最好地利用LLMs的能力来解决这些挑战。
适应新的和罕见的ICD代码:
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure intact: ```html
LLMs展示出强大的零-shot和少-shot学习能力,使它们能够仅凭提示中提供的最少示例和说明就能适应新任务。检索增强生成(RAG)是另一种范式,它使LLMs能够访问更多上下文信息,从而无需微调即可适应新任务。这对于仅通过少量描述或用法示例即可将LLMs适应到新的和/或罕见的ICD编码特别有用,这些编码在训练数据集中可能不经常出现。
```Sure, here's the translation in simplified Chinese: ```html 上下文化信息: ```
Sure, here's the translated text in simplified Chinese: ```html
据发现,LLMs 在临床领域的零-shot 关系抽取方面非常有效 [3] [4]。零-shot 关系抽取允许LLMs在文本中识别和分类关系,而无需事先对这些关系进行特定训练。这有助于更好地将诊断情况与医学编码进行上下文化,从而获得更精确的ICD编码。
```在探讨《利用现成大型语言模型进行自动临床编码》这篇论文。
Sure, here's the translation: ```html
在探索最近将LLMs应用于ICD编码的作品时,我偶然发现了一篇非常有趣的论文,该论文利用LLMs进行ICD编码而没有任何特定的微调。作者提出了一种方法,他们称之为LLM引导的树搜索[5]。
```Sure, here it is:
```html
它是如何工作的?
```
```html
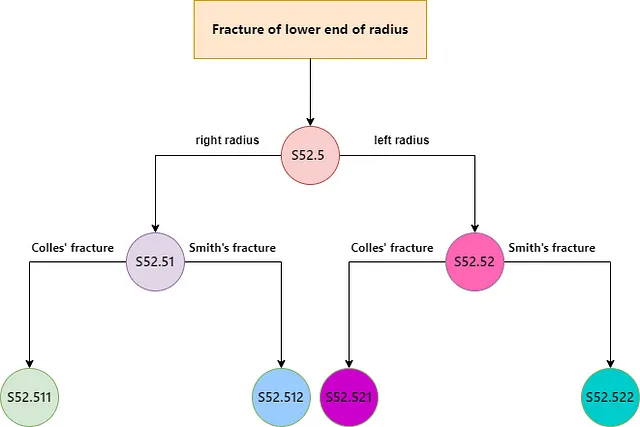
ICD术语是一种分层的、类似树形的结构。每个ICD代码都存在于这种分层结构中,其中父代码涵盖更一般的情况,而子代码详细描述特定疾病。遍历ICD树会导致更具体和细粒度的诊断代码。
```Sure, here's the translated text in simplified Chinese, maintaining the HTML structure: ```html 在LLM引导的树搜索中,搜索从根开始,并使用LLM选择要探索的分支,以迭代方式继续,直到所有路径都耗尽。实际上,通过在树的任何给定级别上提供所有代码的描述以及医疗记录,作为提示提供给LLM,并要求其识别医疗记录的相关代码来实现该过程。然后进一步遍历和探索LLM在每个实例中选择的代码。该方法确定了最相关的ICD代码,随后被分配为临床记录的预测标签。 ```
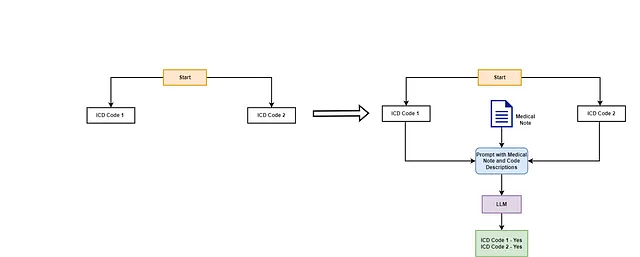
```html
让我们用一个例子来澄清这个问题。想象一棵树,有两个根节点:ICD代码1和ICD代码2。每个节点都有一个纯文本描述来描述代码。在初始阶段,LLM被提供了医疗记录以及代码描述,并被要求确定与医疗记录相关的代码。
```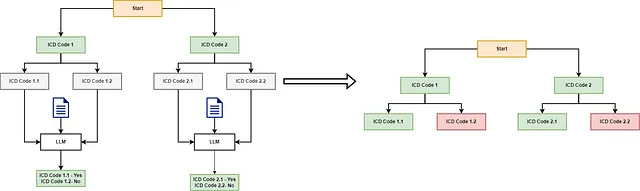
```html 在这种情况下,LLM确定ICD代码1和ICD代码2都与医疗记录相关。然后算法检查每个代码的子节点。每个父代码都有两个表示更具体ICD代码的子节点。从ICD代码1开始,LLM使用ICD代码1.1和ICD代码1.2的描述以及医疗记录来确定相关代码。LLM得出结论,ICD代码1.1是相关的,而ICD代码1.2不是。由于ICD代码1.1没有进一步的子节点,算法将检查它是否是可分配的代码,并将其分配给文档。接下来,算法评估ICD代码2的子节点。再次调用LLM,它确定只有ICD代码2.1是相关的。这是一个简化的例子;在现实中,ICD树是庞大且深入的,这意味着算法将继续遍历每个相关节点的子节点,直到到达树的末端或耗尽有效的遍历。 ```
To translate "Highlights" to simplified Chinese while keeping the HTML structure intact, you can use the following: ```html 要点 ``` This HTML snippet ensures that the text "Highlights" is translated to "要点" in simplified Chinese, while specifying the language code for Chinese (zh-CN) for proper language rendering and accessibility.
- Sure, here's the translated text in simplified Chinese:
```html
该方法不需要对LLM进行任何微调;它利用LLM对医疗记录进行上下文理解的能力,并根据提供的描述动态识别相关的ICD编码。
``` - 此外,本文表明,当在提示中提供相关信息时,LLMs能够有效地适应大的输出空间,在宏平均指标方面胜过PLM-ICD [6],尤其是在罕见代码方面。
- Sure, here's the translated text in simplified Chinese, while keeping the HTML structure intact:
```html
这种技术还优于直接要求LLM根据其参数化知识预测医疗记录的ICD代码的基准线。这突显了将LLMs与工具或外部知识集成以解决临床编码任务的潜力。
```
Certainly! Here's the translation of "Drawbacks" to simplified Chinese while keeping the HTML structure: ```html 缺点 ```
- 以下是 HTML 结构的翻译:算法在树的每个级别调用 LLM。 这导致在遍历树时 LLM 调用次数很高,并且由于 ICD 树的广泛性,这导致处理单个文档的延迟和成本很高。
- 在论文中作者还指出,为了正确预测相关代码,LLM 必须在所有层次上正确识别其父节点。即使在一个层次上出现错误,LLM 也无法达到最终相关代码。
- Sure, here's the translation in simplified Chinese, while keeping the HTML structure intact:
```html
作者由于限制无法使用像MIMIC-III这样的数据集来评估他们的方法,这些限制禁止将数据传输到外部服务,如OpenAI的GPT端点。相反,他们使用CodiEsp数据集的测试集[7,8]来评估该方法,该数据集包括250份医学笔记。这个数据集的规模较小,表明该方法在更大的临床数据集上的有效性尚未确定。
```
Sure, here is the translated text in simplified Chinese: ```html 实现文中描述的技术 ```
Sure, here's the translated text in simplified Chinese: ```html 所有与本文相关的代码和资源都可以在此链接中找到,并且在我的原始博客相关存储库中提供了一个镜像。我想强调,我的重新实现并不完全与论文相同,并且在细微之处有所不同,我已在原始存储库中记录下来。我尝试复制了原始论文中用于调用GPT-3.5和Llama-70B的提示,以此为基础。为了将数据集从西班牙语翻译成英语,我创建了自己的提示,因为论文中未提供详细信息。 ```
Sure, here's the translated text in simplified Chinese: ```html
让我们实施这项技术,以更好地理解其运作原理。 如前所述,该论文使用CodiEsp测试集进行评估。 该数据集包括西班牙医学笔记及其ICD代码。 尽管数据集包括英文翻译版本,但作者指出他们使用GPT-3.5将西班牙医学笔记翻译成英文,声称这比使用预先翻译版本有了一定的性能提升。 我们复制了此功能,并将笔记翻译成英文。
```def construct_translation_prompt(medical_note):
"""
Construct a prompt template for translating spanish medical notes to english.
Args:
medical_note (str): The medical case note.
Returns:
str: A structured template ready to be used as input for a language model.
"""
translation_prompt = """You are an expert Spanish-to-English translator. You are provided with a clinical note written in Spanish.
You must translate the note into English. You must ensure that you properly translate the medical and technical terms from Spanish to English without any mistakes.
Spanish Medical Note:
{medical_note}"""
return translation_prompt.format(medical_note = medical_note)
```html 现在我们已经准备好评估语料库,让我们来实现树搜索算法的核心逻辑。我们在 get_icd_codes 中定义功能,接受要处理的医疗笔记、模型名称和温度设置。模型名称必须是“gpt-3.5-turbo-0613”表示GPT-3.5,或“meta-llama/Llama-2–70b-chat-hf”表示Llama-2 70B Chat。这个规范确定了树搜索算法在处理过程中将调用的LLM。 ```
评估 GPT-4 可以使用相同的代码库,只需提供相应的模型名称即可,但我们选择跳过此步骤,因为它相当耗时。
def get_icd_codes(medical_note, model_name="gpt-3.5-turbo-0613", temperature=0.0):
"""
Identifies relevant ICD-10 codes for a given medical note by querying a language model.
This function implements the tree-search algorithm for ICD coding described in https://openreview.net/forum?id=mqnR8rGWkn.
Args:
medical_note (str): The medical note for which ICD-10 codes are to be identified.
model_name (str): The identifier for the language model used in the API (default is 'gpt-3.5-turbo-0613').
Returns:
list of str: A list of confirmed ICD-10 codes that are relevant to the medical note.
"""
assigned_codes = []
candidate_codes = [x.name for x in CHAPTER_LIST]
parent_codes = []
prompt_count = 0
while prompt_count < 50:
code_descriptions = {}
for x in candidate_codes:
description, code = get_name_and_description(x, model_name)
code_descriptions[description] = code
prompt = build_zero_shot_prompt(medical_note, list(code_descriptions.keys()), model_name=model_name)
lm_response = get_response(prompt, model_name, temperature=temperature, max_tokens=500)
predicted_codes = parse_outputs(lm_response, code_descriptions, model_name=model_name)
for code in predicted_codes:
if cm.is_leaf(code["code"]):
assigned_codes.append(code["code"])
else:
parent_codes.append(code)
if len(parent_codes) > 0:
parent_code = parent_codes.pop(0)
candidate_codes = cm.get_children(parent_code["code"])
else:
break
prompt_count += 1
return assigned_codes
Sure, here's the translated text in simplified Chinese: 类似于论文,我们使用了simple_icd_10_cm库,该库提供对ICD-10树的访问。这使我们能够遍历树,访问每个代码的描述,并识别有效的代码。首先,我们获取树的第一级节点。
import simple_icd_10_cm as cm
def get_name_and_description(code, model_name):
"""
Retrieve the name and description of an ICD-10 code.
Args:
code (str): The ICD-10 code.
Returns:
tuple: A tuple containing the formatted description and the name of the code.
"""
full_data = cm.get_full_data(code).split("\n")
return format_code_descriptions(full_data[3], model_name), full_data[1]
在循环内,我们获取与每个节点对应的描述。现在,我们需要根据医疗记录和代码描述构建LLM的提示。我们根据论文中提供的细节为GPT-3.5和Llama-2创建提示。
prompt_template_dict = {"gpt-3.5-turbo-0613" : """[Case note]:
{note}
[Example]:
<example prompt>
Gastro-esophageal reflux disease
Enteropotosis
<response>
Gastro-esophageal reflux disease: Yes, Patient was prescribed omeprazole.
Enteropotosis: No.
[Task]:
Consider each of the following ICD-10 code descriptions and evaluate if there are any related mentions in the case note.
Follow the format in the example precisely.
{code_descriptions}""",
"meta-llama/Llama-2-70b-chat-hf": """[Case note]:
{note}
[Example]:
<code descriptions>
* Gastro-esophageal reflux disease
* Enteroptosis
* Acute Nasopharyngitis [Common Cold]
</code descriptions>
<response>
* Gastro-esophageal reflux disease: Yes, Patient was prescribed omeprazole.
* Enteroptosis: No.
* Acute Nasopharyngitis [Common Cold]: No.
</response>
[Task]:
Follow the format in the example response exactly, including the entire description before your (Yes|No) judgement, followed by a newline.
Consider each of the following ICD-10 code descriptions and evaluate if there are any related mentions in the Case note.
{code_descriptions}"""
}
Sure, here's the translated text in simplified Chinese while maintaining the HTML structure: ```html
我们现在基于医疗记录和代码描述构建提示。在提示和编码方面的一个优势是,我们可以使用相同的OpenAI库与GPT-3.5和Llama 2进行交互,前提是Llama-2是使用deepinfra部署的,deepinfra也支持将请求发送到LLM的openai格式。
```def construct_prompt_template(case_note, code_descriptions, model_name):
"""
Construct a prompt template for evaluating ICD-10 code descriptions against a given case note.
Args:
case_note (str): The medical case note.
code_descriptions (str): The ICD-10 code descriptions formatted as a single string.
Returns:
str: A structured template ready to be used as input for a language model.
"""
template = prompt_template_dict[model_name]
return template.format(note=case_note, code_descriptions=code_descriptions)
def build_zero_shot_prompt(input_note, descriptions, model_name, system_prompt=""):
"""
Build a zero-shot classification prompt with system and user roles for a language model.
Args:
input_note (str): The input note or query.
descriptions (list of str): List of ICD-10 code descriptions.
system_prompt (str): Optional initial system prompt or instruction.
Returns:
list of dict: A structured list of dictionaries defining the role and content of each message.
"""
if model_name == "meta-llama/Llama-2-70b-chat-hf":
code_descriptions = "\n".join(["* " + x for x in descriptions])
else:
code_descriptions = "\n".join(descriptions)
input_prompt = construct_prompt_template(input_note, code_descriptions, model_name)
return [{"role": "system", "content": system_prompt}, {"role": "user", "content": input_prompt}]
在构建好提示后,我们现在调用LLM来获取响应:
def get_response(messages, model_name, temperature=0.0, max_tokens=500):
"""
Obtain responses from a specified model via the chat-completions API.
Args:
messages (list of dict): List of messages structured for API input.
model_name (str): Identifier for the model to query.
temperature (float): Controls randomness of response, where 0 is deterministic.
max_tokens (int): Limit on the number of tokens in the response.
Returns:
str: The content of the response message from the model.
"""
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
```html
好的,我们已经获得了输出!从响应中,我们现在解析每个代码描述,以识别LLM认为对进一步遍历相关的节点,以及LLM拒绝的节点。我们将输出响应分成新行,并分割每个响应,以识别LLM对每个代码描述的预测。
```def remove_noisy_prefix(text):
# Removing numbers or letters followed by a dot and optional space at the beginning of the string
cleaned_text = text.replace("* ", "").strip()
cleaned_text = re.sub(r"^\s*\w+\.\s*", "", cleaned_text)
return cleaned_text.strip()
def parse_outputs(output, code_description_map, model_name):
"""
Parse model outputs to confirm ICD-10 codes based on a given description map.
Args:
output (str): The model output containing confirmations.
code_description_map (dict): Mapping of descriptions to ICD-10 codes.
Returns:
list of dict: A list of confirmed codes and their descriptions.
"""
confirmed_codes = []
split_outputs = [x for x in output.split("\n") if x]
for item in split_outputs:
try:
code_description, confirmation = item.split(":", 1)
if model_name == "meta-llama/Llama-2-70b-chat-hf":
code_description = remove_noisy_prefix(code_description)
if confirmation.lower().strip().startswith("yes"):
try:
code = code_description_map[code_description]
confirmed_codes.append({"code": code, "description": code_description})
except Exception as e:
print(str(e) + " Here")
continue
except:
continue
return confirmed_codes
Sure, here is the translated text in simplified Chinese: 现在让我们看一下循环的剩余部分。到目前为止,我们已经构建了提示,从LLM获取了响应,并解析了输出以识别LLM认为相关的代码。
while prompt_count < 50:
code_descriptions = {}
for x in candidate_codes:
description, code = get_name_and_description(x, model_name)
code_descriptions[description] = code
prompt = build_zero_shot_prompt(medical_note, list(code_descriptions.keys()), model_name=model_name)
lm_response = get_response(prompt, model_name, temperature=temperature, max_tokens=500)
predicted_codes = parse_outputs(lm_response, code_descriptions, model_name=model_name)
for code in predicted_codes:
if cm.is_leaf(code["code"]):
assigned_codes.append(code["code"])
else:
parent_codes.append(code)
if len(parent_codes) > 0:
parent_code = parent_codes.pop(0)
candidate_codes = cm.get_children(parent_code["code"])
else:
break
prompt_count += 1
现在我们通过预测的代码进行迭代,并检查每个代码是否是“叶子”代码,这基本上确保该代码是有效且可分配的ICD代码。如果预测的代码有效,我们将其视为LLM对该医疗记录的预测。如果不是,则将其添加到我们的父代码中,并获取子节点以进一步遍历ICD树。如果没有更多的父代码可以进一步遍历,则我们跳出循环。
在理论上,每个医疗笔记的LLM调用次数可以任意高,如果算法遍历了许多节点,则会导致延迟增加。作者们规定每个医疗笔记最多只能有50个提示/LLM调用,以终止处理,这也是我们在实现中采用的限制。
结果
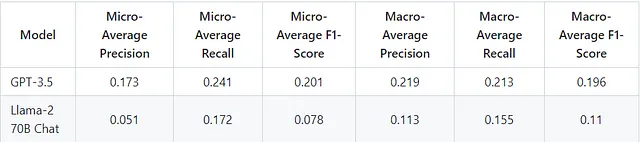
我们现在可以使用GPT-3.5和Llama-2作为LLMs来评估树搜索算法的结果。我们将根据微平均和宏平均的精确度、召回率和F1得分来评估算法的性能。
```html
虽然实现的结果大致与论文中报告的分数相符,但也存在一些值得注意的差异。
```- Sure, here's the translated text in simplified Chinese, keeping the HTML structure:
```html
在这个实现中,GPT-3.5的微平均指标略高于报告的数据,而宏平均指标则略低于报告的值。
``` - Sure, here's your text translated into simplified Chinese while keeping the HTML structure:
```html
同样,Llama-70B的微平均指标要么与报告的数字相匹配,要么略高于报告的数字,但宏平均指标低于报告的数值。
```
Sure, here's the translated text in simplified Chinese, maintaining the HTML structure: ```html
如前所述,这个实现在一些细微的方式上与论文不同,所有这些都会影响最终的性能。请参考链接的存储库,了解这个实现与原始论文的区别的更详细讨论。
```结论
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html
理解并实施这种方法在很多方面对我来说都非常有见地。它使我能够更加细致地了解临床编码案例中大型语言模型(LLMs)的优势和劣势。具体而言,明显地表明,为LLMs提供有关编码的相关信息的动态访问可以帮助提高它们的性能。
```以下是保留HTML结构的文本,将以下英文文本翻译为简体中文: ```html
探索利用LLMs作为临床编码代理是否能进一步提高性能将会很有趣。考虑到生物医学和临床文本的外部知识源的丰富性,以论文或知识图的形式存在,LLM代理可能被用于分析医疗文件的工作流程,达到更精细的粒度。如果需要,它们还可以调用工具,使它们能够即时参考外部知识,以得出最终编码。
``` Hope this helps! Let me know if you need anything else.限制
在本文中,尽管我试图分析LLMs如何在ICD编码方面提供帮助,但总体上也有一些需要考虑的实际限制:
- ```html
LLMs 部署需要大量的计算资源。这导致需要强大的 GPU 考虑,否则应用可能会遭受高延迟的影响,这可能会限制它们的采用。
``` - 此外,医疗数据处理通常需要严格的数据安全和隐私保障。在线法律文件管理服务可能并不一定符合医疗数据处理所需的安全和隐私标准。
致谢
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
对本文的主要作者Joseph,对于澄清我对该方法评估的疑问,表示由衷的感谢!
```参考资料:
You can use the following HTML structure to display the translated text in simplified Chinese: ```html 世界卫生组织疾病分类 ``` This HTML code will create a hyperlink with the text "世界卫生组织疾病分类" that links to the WHO page on disease classification.
Sure, here is the translated text in simplified Chinese, while keeping the HTML structure intact: ```html [2] Johnson, A. E., Pollard, T. J., Shen, L., Lehman, L. W. H., Feng, M., Ghassemi, M., … & Mark, R. G. (2016). MIMIC-III,一个免费可访问的重症监护数据库 Sci. Data,3(1),1。 ```
Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html [3] Agrawal, M., Hegselmann, S., Lang, H., Kim, Y., & Sontag, D. (2022). Large language models are few-shot clinical information extractors. arXiv preprint arXiv:2205.12689. ``` And the corresponding Chinese translation: ```html [3] Agrawal, M., Hegselmann, S., Lang, H., Kim, Y., & Sontag, D. (2022). 大型语言模型是少样本临床信息提取器。arXiv 预印本 arXiv:2205.12689. ```
Sure, here's the translation: ```html
[4] 周,H.,李,M.,肖,Y.,杨,H.,& 张,R.(2023年)。临床关系提取的LLM指令示例自适应提示(LEAP)框架。 medRxiv:健康科学的预印服务器,2023年12月15日,23300059。https://doi.org/10.1101/2023.12.15.23300059
```[5] Boyle, J. S., Kascenas, A., Lok, P., Liakata, M., & O’Neil, A. Q. (2023年10月). 使用现成的大型语言模型进行自动临床编码. 在NeurIPS 2023的深度生成模型健康研讨会上.
Sure, here's the translated text in simplified Chinese, while maintaining the HTML structure: ```html [6] 黄,C.W.,蔡,S.C.,& 陈,Y.N. (2022). PLM-ICD:使用预训练语言模型进行自动ICD编码。arXiv预印本arXiv:2207.05289。 ```
Sure, here's the HTML structure with the text translated into simplified Chinese: ```html
[7] Miranda-Escalada, A., Gonzalez-Agirre, A., Armengol-Estapé, J., & Krallinger, M. (2020). 临床自动编码概述:CLEF eHealth 2020年CodiEsp赛道非英文临床案例的注释、指南和解决方案。CLEF(工作笔记),2020年。
```Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html
[8] Miranda-Escalada, A., Gonzalez-Agirre, A., & Krallinger, M. (2020). CodiEsp corpus: gold standard Spanish clinical cases coded in ICD10 (CIE10) — eHealth CLEF2020 (1.4) [Data set]. Zenodo. (CC BY 4.0)
```