用 LLamaIndex 和 Gemini 构建高级搜索引擎
Sure, here's the translation:
```html
介绍
```
Sure, here's the translation of the English text into simplified Chinese while keeping the HTML structure: ```html
Retriever是RAG(检索增强生成)管道中最重要的部分。在本文中,您将使用LlamaIndex实现结合关键字和向量搜索检索器的自定义检索器。Chat with Multiple Documents using Gemini LLM是我们将构建此RAG管道的项目用例。要开始项目,我们将首先了解一些关键组件,如服务和存储上下文,以构建这样的应用程序。
``` This text is enclosed in `` tags to maintain HTML structure.
学习目标
- 将英文文本翻译成简体中文并保留HTML结构: ```html 获得对RAG管道的洞察,理解Retriever和Generator组件在上下文中生成响应的角色。 ```
- 学习如何集成关键词和向量搜索技术,开发自定义检索器,提高在RAG应用中的搜索准确性。
- 在使用LlamaIndex进行数据摄入、为LLMs提供上下文,并加深与自定义数据的连接方面获得熟练技能。
- 了解通过混合搜索机制在LLM响应中缓解幻觉的定制检索器的重要性。
- 探索高级检索器实现,如重新排序和HyDE,以增强在RAG中的文档相关性。
- 学习在LlamaIndex中集成Gemini LLM和嵌入以进行响应生成和数据存储,提高RAG功能。
- 在定制检索器配置中培养决策能力,包括选择AND和OR操作以优化搜索结果。
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html 什么是LlamaIndex? ```
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html
大型语言模型领域正在迅速扩展,每天都有显著改进。
随着越来越多的模型以快速的速度发布,对这些模型进行自定义数据集成的需求也在不断增长。
这种整合为企业、企业和最终用户提供了更多灵活性和更深入地连接到他们的数据的机会。
``````html
LlamaIndex,最初被称为GPT-index,是专为您的LLM应用程序设计的数据框架。
随着像ChatGPT这样的构建自定义数据驱动聊天机器人的流行度不断上升,LlamaIndex等框架变得越来越有价值。
在其核心,LlamaIndex提供了各种数据连接器,以促进数据摄入。
在本文中,我们将探讨如何将我们的数据作为上下文传递给LLM,这个概念就是我们所说的检索增强生成,简称RAG。
Sure, here's the translation: ```html
什么是RAG?
```在检索增强生成中,简称为RAG,有两个主要组成部分:检索器和生成器。
- Sure, here's the HTML structure with the translated text:
```html
```
Retriever可以是向量数据库,其作用是检索与用户查询相关的文档,并将其作为上下文传递给提示。
- Sure, here's the translated text in simplified Chinese, keeping the HTML structure:
```html
生成器模型是一个大型语言模型,其工作是将检索到的文档与提示一起使用,从上下文中生成有意义的响应。
```
这样,通过自动几次提示的上下文学习,RAG是最佳解决方案。
Sure, here's the translation in simplified Chinese, while keeping the HTML structure:
```html
收回者的重要性
```
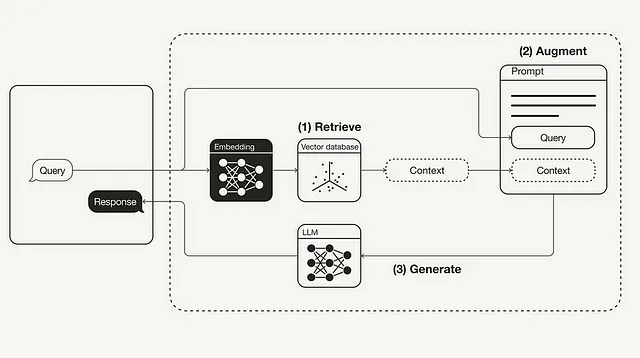
Sure, here is the text translated into simplified Chinese within an HTML structure: ```html
让我们了解在 RAG 管道中的 Retriever 组件的重要性。
```To keep the HTML structure intact while translating the text to simplified Chinese: ```html
开发自定义检索器时,确定最适合我们需求的检索器类型至关重要。为了我们的目的,我们将实现一个混合搜索,集成关键词搜索和向量搜索。
``` In simplified Chinese, the translation of the text "To develop a custom retriever, it’s crucial to determine the type of retriever that best suits our needs. For our purposes, we will implement a Hybrid Search that integrates both Keyword Search and Vector Search." is: ```html开发自定义检索器时,确定最适合我们需求的检索器类型至关重要。为了我们的目的,我们将实现一个混合搜索,集成关键词搜索和向量搜索。
``` This HTML snippet contains the translated text within a paragraph (``) tag, maintaining the structure specified.
在向量搜索中,根据相似性或语义搜索确定与用户查询相关的文档,而关键词搜索则根据术语出现的频率找到文档。使用 LlamaIndex 可以通过两种方式实现此集成。在构建混合搜索的自定义检索器时,一个重要的决定是选择使用 AND 还是 OR 操作:
- Sure, here's the translated text in simplified Chinese, maintaining the HTML structure: ```html AND 操作:此方法检索包含所有指定术语的文档,使其更为严格,但确保高相关性。您可以将其视为关键词搜索和向量搜索结果之间的交集。 ```
- Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html OR 运算:此方法检索包含任何指定术语的文档,扩大结果的广度但可能降低相关性。您可以将其视为关键字搜索和向量搜索结果之间的联合。 ``` Would you like any further assistance with this?
使用LLamaIndex构建自定义检索器
Sure, here is the translated text in simplified Chinese: 让我们现在使用LlamaIndex构建客户检索器。要构建此工具,我们需要遵循一些步骤。
Step1: 安装
Sure, here's the HTML structure with the text translated into simplified Chinese: ```html
要在Google Colab或Jupyter Notebook上开始代码实现,需要安装所需的库,主要包括LlamaIndex用于构建自定义检索器,Gemini用于嵌入模型和LLM推理,以及PyPDF用于数据连接器。
```!pip install llama-index
!pip install llama-index-multi-modal-llms-gemini
!pip install llama-index-embeddings-gemini
Sure, here is the text translated to simplified Chinese while keeping the HTML structure: ```html Step2: 设置Google API密钥 ```
在这个项目中,我们将利用Google Gemini作为大型语言模型来生成响应,并将其作为嵌入模型,使用LlamaIndex将数据转换并存储在vector-db或内存存储中。
Sure, here is the simplified Chinese translation of "Get your API key here", keeping the HTML structure intact: ```html 获取您的 API 密钥 ```
from getpass import getpass
GOOGLE_API_KEY = getpass("Enter your Google API:")
Step3: 载入数据并创建文档节点
Sure, here is the translated text in simplified Chinese, keeping the HTML structure: ```html
在 LlamaIndex 中,数据加载是通过 SimpleDirectoryLoader 完成的。首先,您需要创建一个文件夹,并将任何格式的数据上传到这个数据文件夹中。在我们的示例中,我将上传一个 PDF 文件到数据文件夹。一旦文档被加载,它会被解析成节点,以将文档分割成更小的部分。一个节点是 LlamaIndex 框架中定义的数据模式。
```Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html
最新版本的LlamaIndex已更新其代码结构,现在包括节点解析器、嵌入模型和设置中的LLM定义。
```from llama_index.core import SimpleDirectoryReader
from llama_index.core import Settings
documents = SimpleDirectoryReader('data').load_data()
nodes = Settings.node_parser.get_nodes_from_documents(documents)
Step4: 设置嵌入模型和大型语言模型
Sure, here is the translated text: ```html 双子座支持各种模型,包括gemini-pro,gemini-1.0-pro,gemini-1.5,vision模型等。在这种情况下,我们将使用默认模型并提供Google API密钥。对于双子座中的嵌入模型,我们目前正在使用嵌入-001。请确保添加有效的API密钥。 ```
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.gemini import Gemini
Settings.embed_model = GeminiEmbedding(
model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.llm = Gemini(api_key=GOOGLE_API_KEY)
Step5: 定义存储上下文并存储数据
Sure, here is the translated text in simplified Chinese within an HTML structure: ```html
一旦数据被解析为节点,LlamaIndex提供了存储上下文,提供默认文档存储以存储数据的向量嵌入。这个存储上下文将数据保留在内存中,允许稍后对其进行索引。
```from llama_index.core import StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
Sure, here is the translation: 创建索引- 关键字和索引
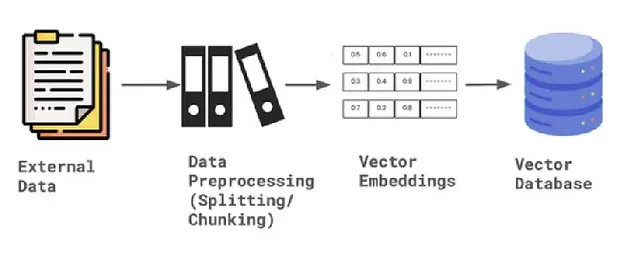
为了构建自定义检索器以执行混合搜索,我们需要创建两个索引。第一个是能够执行向量搜索的向量索引,第二个是能够执行关键字搜索的关键字索引。为了创建索引,我们需要存储上下文和节点文档,以及嵌入模型和LLM的默认设置。
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)
Step6: 构建自定义检索器
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
要使用LlamaIndex构建混合搜索的自定义检索器,我们首先需要定义模式,具体来说是通过适当配置节点来实现。对于检索器,需要同时使用矢量索引检索器和关键词检索器。这样可以使我们执行混合搜索,将两种技术整合在一起以最小化幻觉。此外,我们还必须指定模式 - 是AND还是OR - 这取决于我们希望如何组合结果。
``` Let me know if you need anything else!以下是HTML结构,将以下英文文本翻译成简体中文: 一旦节点被配置好,我们使用向量和关键词检索器查询每个节点ID的束。根据所选模式,然后我们定义并完成自定义检索器。
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScore
from llama_index.core.retrievers import (
BaseRetriever,
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from typing import List
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND") -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
raise ValueError("Invalid mode.")
self._mode = mode
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in keyword_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
retrieve_ids = vector_ids.union(keyword_ids)
retrieve_nodes = [combined_dict[r_id] for r_id in retrieve_ids]
return retrieve_nodes
Step7: 定义检索器
```html 现在定义了自定义的检索器类,我们需要实例化检索器并合成查询引擎。响应合成器用于根据用户查询和给定的文本块生成LLM的响应。响应合成器的输出是一个响应对象,其中一个参数是自定义的检索器。 ```
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# custom retriever => combine vector and keyword retriever
custom_retriever = CustomRetriever(vector_retriever, keyword_retriever)
# define response synthesizer
response_synthesizer = get_response_synthesizer()
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)
Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html
步骤8:运行自定义检索器查询引擎
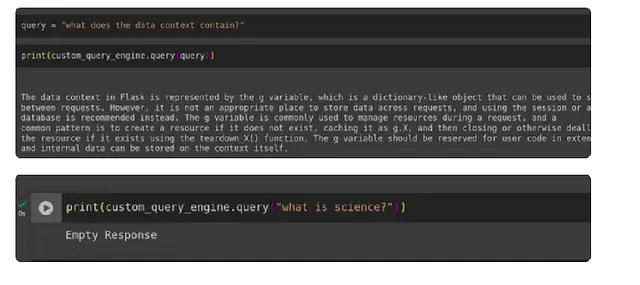
``````html 最后,我们开发了定制的检索器,显著减少了幻觉。为了测试其有效性,我们运行了用户查询,包括一个来自上下文内部的提示和另一个来自上下文外部的提示,然后评估生成的响应。 ```
query = "what does the data context contain?"
print(custom_query_engine.query(query))
print(custom_query_engine.query("what is science?")
结论
```html
我们已成功实现了一种自定义检索器,通过结合向量检索器和关键词检索器,使用LlamaIndex,并得到Gemini LLM和嵌入的支持,实现了混合搜索。这种方法在典型的RAG管道中有效地减少了LLM的幻觉。
```重点提示
- Sure, here's the translation:
```html
开发一个定制的检索器,将向量检索器和关键词检索器整合在一起,提高RAG相关文档的搜索能力和准确性。
``` - Sure, here is the translated text in simplified Chinese while keeping the HTML structure:
```html
使用LlamaIndex设置实现Gemini嵌入和LLM,该设置在最新版本中被替换,先前是使用Service Context 完成的,现在已被弃用。
``` - 在构建定制检索器时,一个关键的决定是是否使用AND或OR操作,根据特定需求平衡关键字和向量搜索结果的交集和并集。
- Sure, here's the translated text in simplified Chinese, while keeping the HTML structure:
```html
自定义检索器设置通过在RAG管道中使用混合搜索机制,显著减少了大型语言模型响应中的幻觉。
```
Sure, here is the translation: 关于我
Sure, here's the translated text in simplified Chinese within an HTML structure: ```html
这是我的Linkedin资料,如果你想联系我,请添加我为好友。
希望你喜欢我的文章。如果你喜欢,也请分享给你的朋友,并关注我。
如果你有任何想法可以改进我的文章写作,请随时评论。
你也可以在这里阅读我之前发表的所有文章:https://aivichar.com/
```