利用ChatGPT和LangChain的代理和工具创建(主要是)自主的人力资源助手
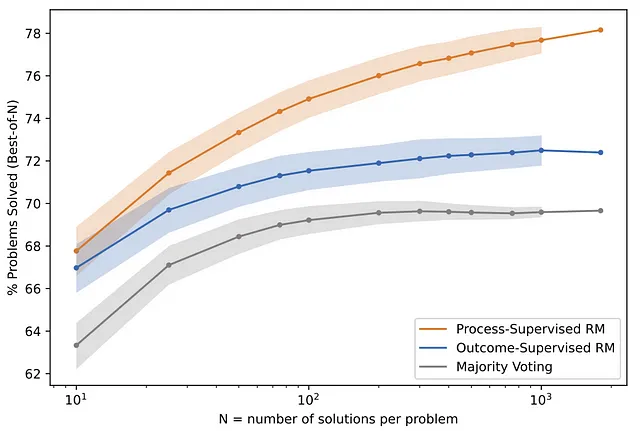
OpenAI 最近发布了一篇论文,比较了两种旨在提高大型语言模型 (LLM) 可靠性的训练方法:通过“过程监督”进行模型训练和通过“结果监督”进行模型训练。
基本上,一种模型会因正确的“思维过程”或生成答案所需的中间推理步骤而获得奖励;另一种模型则因正确的“结果”或最终结果而获得奖励。
这两种模型在数学问题数据集上进行测试。研究发现,受过过程监督训练的模型,即因正确“思考过程”而获得奖励的模型,明显优于因正确“结果”而获得奖励的模型。
另一份谷歌的论文表明,在心理连想提示的支持下,LLM在推理和决策任务中表现更出色。也就是说,如果它大声地解释其思考过程来得出答案,而不是立即输出答案,它会更有效。
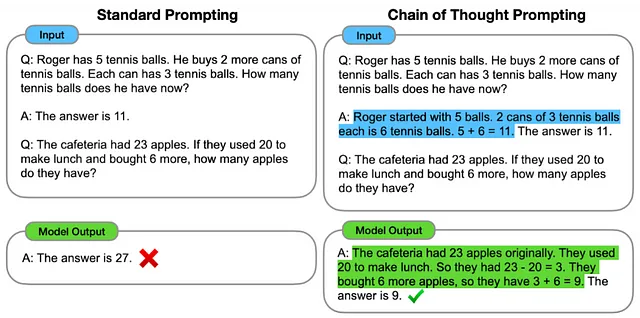
这两篇论文表明,通过利用思维链过程进行决策,这些模型不仅增强了它们的问题解决能力,还降低了幻觉的发生率,即产生不正确或荒谬信息的情况。
一个能够利用这种新兴能力的组件是 LangChain 的代理模块。LangChain 是一个开发框架,用于在 LLMs 周围构建应用程序。
LangChain代理人的工作方式是通过创建多步骤行动计划来分解复杂任务,确定中间步骤并逐步独立地处理每个步骤以得出最终答案。
它通过一个类似于OpenAI和Google论文中描述的思考/行动/行动输入/观察循环,遵循ReAct格式。这个循环结合了思考链路推理和行动,并借鉴了上述Google论文。
LangChain中的另一个重要模块是工具。它基于MRKL论文-该论文认为,尽管LLM是令人印象深刻的技术,但它们具有固有的局限性-它们受其训练数据的限制,并且缺乏访问当前信息或专有数据-例如公司的客户列表。为了解决这个问题,它提出了一个叫MRKL系统的概念。
该系统由一组可扩展的模块(称为专家)和一个路由器(通常是LLM本身)组成,将自然语言(NL)查询路由到最能响应查询的模块。例如,关于天气预报的查询将由LLM路由到天气API,数学查询将路由到数学专家(计算器,numpy函数等)。工具是这些专家的LangChain抽象。
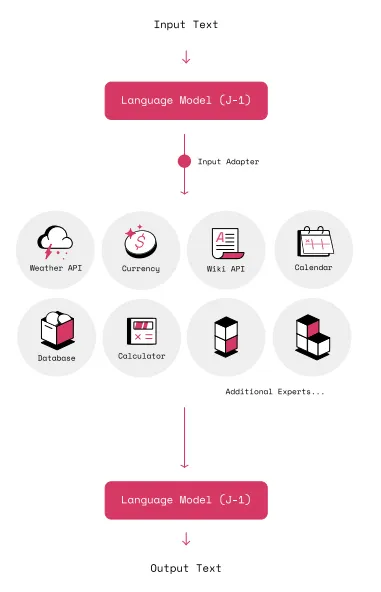
此 HR 聊天机器人是尝试原型化一个利用这些概念及其实现的 LLM 强化企业应用程序。该聊天机器人是使用 LangChain 代理和工具模块构建的,其由 ChatGPT 模型或 gpt-3.5-turbo 强化。我们已经为其提供了 3 个工具,即时间记录政策、员工数据和计算器。
让我们看看它在行动中。开始吧!
HR聊天机器人演示
当前登录聊天界面的用户姓名是亚历山大·韦尔达德。他正在向聊天机器人提问有关时间记录的问题。
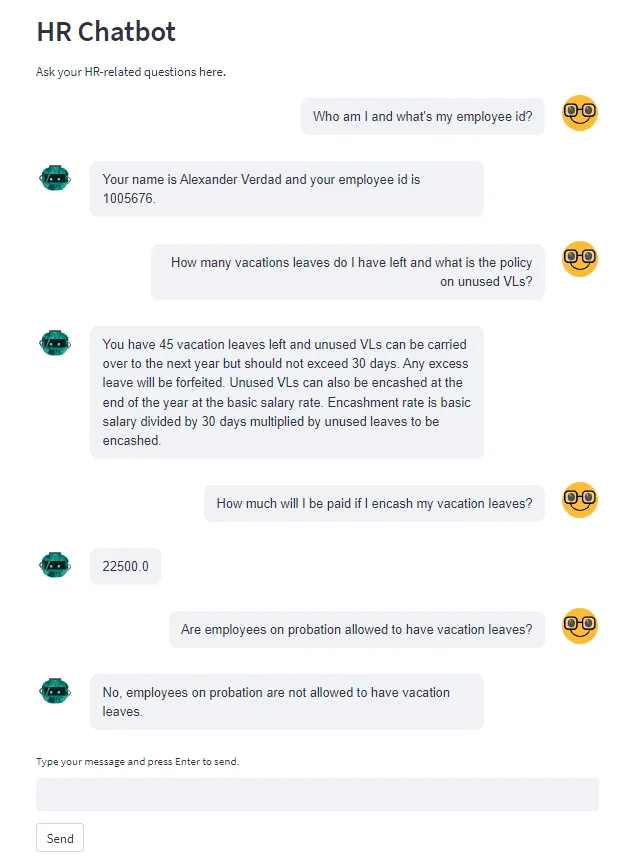
这可能是一次平凡的交流,但是,有趣的是背后正在发生什么!
让我们分解每个问题-答案对,并检查LLM是如何找出答案的。
亚历山大正在询问关于一般时间管理政策:
以下是LLM使用“计时政策”工具来计算用户问题的答案。
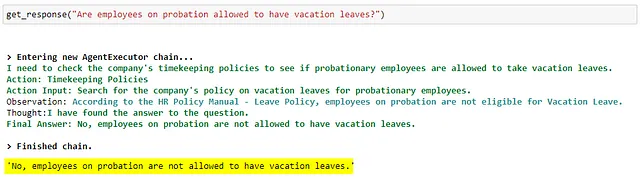
请注意,所有到达最终答案(思考、行动、行动输入、观察)的中间步骤都是由LLM自主生成的。
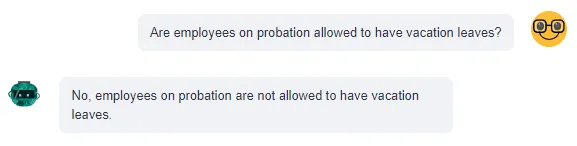
亚历山大问他还剩下多少年假和如果他在年底之前没有使用它会发生什么。
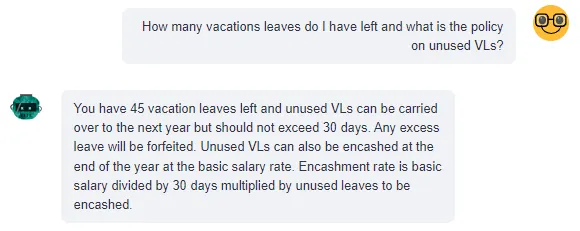
这个查询需要来自两个来源的信息:员工数据(亚历山大剩下多少个休假天数)和考勤政策(未使用的休假天数在年底会发生什么)。
以下是使用这两个工具进行的 LLM:
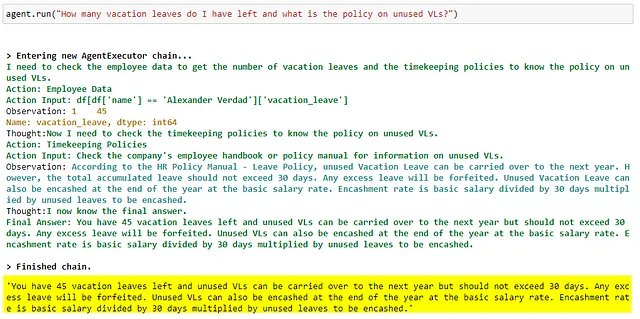
由于亚历山大现在知道未使用的VLs可以兑换成现金,他问聊天机器人如果他把所有未使用的VLs兑换成现金,他会得到多少钱。

根据政策,未使用的休假天数可以按员工的日薪转换为现金(使用公式:月基本工资除以30天,再乘以未使用的休假天数)。
员工的基本工资(15,000菲律宾比索),除以30天,为500菲律宾比索。乘以亚历山大未使用的VL(45)——他应该获得22,500菲律宾比索的工资。
以下是LLM使用其拥有的三种工具(计时政策、员工数据、计算器)来计算用户查询的答案。
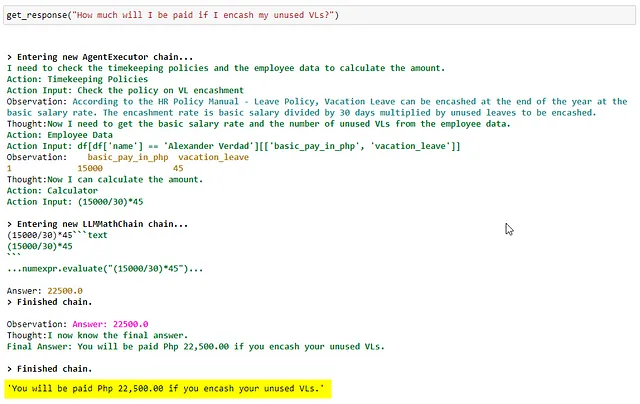
这是一个LLM使用思维链解决相当复杂任务的最佳示范。非常酷!
用户输入不需要完美无误——它可能会错过标点符号,少一个单词,或者未被正确地大写或语法上有错误。LLM拥有从不完美但可理解的句子结构中“推断”用户意图的能力。
引擎盖下面
由于LLM承担了所有繁重的工作,因此生成的源代码相对较短-大约50行(Python)代码。对于此聊天机器人的代码实现,一个很好的比喻是将一个接受了充分介绍的专业人员置于一个房间,并为其提供时间记录政策的副本,访问SAP HR(以检查员工数据),计算器,然后让其自行处理。
提示
提示信息充当了LLM的“护栏”,使其专注并按我们所需的方式执行。它由我们希望LLM扮演的“角色”(人力资源助理)、它应该使用的工具以及输出格式组成。
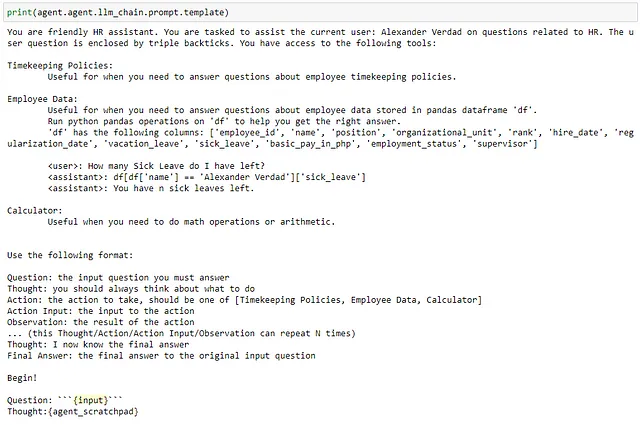
每个工具都有描述,以帮助LLM决定在什么特定情况下使用该工具最佳。我们还为使用工具的说明提供了一些少量提示。一般来说,长一些,更详细的提示比短的提示更好。我们只需要确保不会超过我们使用的模型的标记限制。
每当用户在聊天机器人界面上点击“发送”按钮时,此提示会与用户输入一起传递给 LLM。
将用户输入用定界符(如反引号)包裹,并让LLM知道它,有助于防止提示注入。
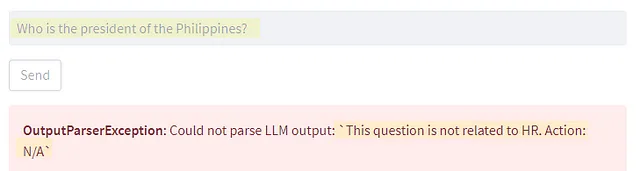
代理商和工具
LLM代理程序与其应该使用的工具列表一起初始化。代理程序可以通过对每个工具运行方法的利用来使用工具。每个工具的实现在以下各节中详细说明。
from langchain.agents import Tool, initialize_agent
# create variables for f strings embedded in the prompts
user = 'Alexander Verdad' # set user
df_columns = df.columns.to_list() # print column names of df
# prep the (tk policy) vectordb retriever, the python_repl(with df access) and langchain calculator as tools for the agent
tools = [
Tool(
name = "Timekeeping Policies",
func=timekeeping_policy.run,
description="""
Useful for when you need to answer questions about employee timekeeping policies.
"""
),
Tool(
name = "Employee Data",
func=python.run,
description = f"""
Useful for when you need to answer questions about employee data stored in pandas dataframe 'df'.
Run python pandas operations on 'df' to help you get the right answer.
'df' has the following columns: {df_columns}
<user>: How many Sick Leave do I have left?
<assistant>: df[df['name'] == '{user}']['sick_leave']
<assistant>: You have n sick leaves left.
"""
),
Tool(
name = "Calculator",
func=calculator.run,
description = f"""
Useful when you need to do math operations or arithmetic.
"""
)
]
# initializae zero shot agent
agent = initialize_agent(tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
agent_kwargs=agent_kwargs
)根据登陆的用户和加载的数据框,提示中的用户和数据框列名会发生改变。
时间管理政策工具
以下是由聊天机器人参考的计时政策文件摘录。这是一个由ChatGPT生成的17页文件,被分成20个每个含400个令牌的部分以避免令牌限制。它使用OpenAI的文本嵌入ada-002模型进行向量化,并存储在Pinecone向量数据库中的索引中。

如何工作:
当用户提交了查询(“未使用的 VL 的政策是什么”)后,查询文本将使用嵌入模型矢量化(转换为数字)。这些数字表示将在向量数据库中查询并与数据库中存储的其他数字表示进行比较(表示时间记录政策文件中的文本值)。该过程称为余弦相似性搜索,它寻找与查询的数字表示最相似的数字表示。
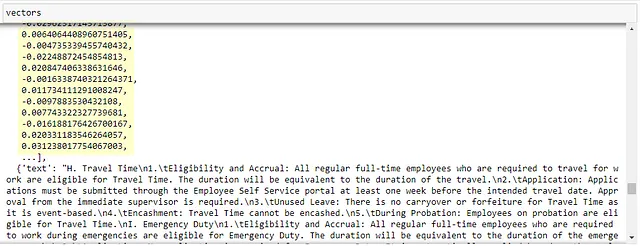
数据库中最相似数字表示的相应文本值将作为输出返回。文本输出随后由LLM用作上下文信息,以会话方式回答用户查询。(‘VL可以延续到下一年,但不得超过30天。’)这被称为上下文学习。您可以阅读我的先前帖子,在其中我还写了一个关于向量化和嵌入的面向普通人的简介部分(希望)。
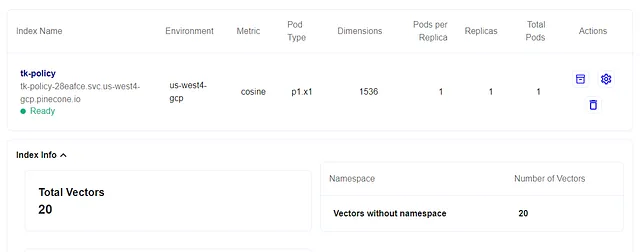
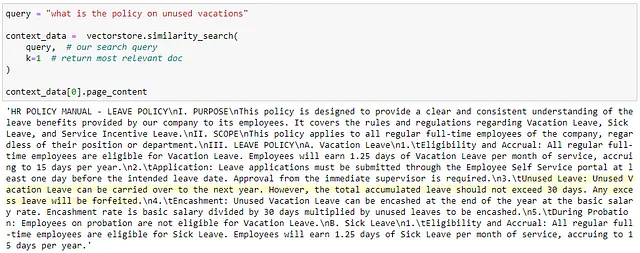
以下是针对 Pinecone 索引执行余弦相似度搜索查询的样本输出。此步骤/查询不使用 LLM。相反,输出的“上下文数据”将被提交给 LLM 作为上下文信息以回答用户的查询:
令牌限制是指每个请求模型可以处理的令牌数量。令牌是文本的一个单位。1个令牌相当于约4个字符。包括在令牌限制计数中的是用户的查询/输入和模型的响应或输出。

ChatGPT/gpt-3.5-turbo的Token限制为4097。GPT-4有8k和32k Token限制的2个版本。
"时间管理政策" 工具的实施:
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.chat_models import AzureChatOpenAI
from langchain.chains import RetrievalQA
# initialize pinecone client and connect to pinecone index
pinecone.init(
api_key="<your pine cone api key>",
environment="<your pinecone environment>"
)
index_name = 'tk-policy'
index = pinecone.Index(index_name) # connect to pinecone index
# initialize embeddings object; for use with user query/input
embed = OpenAIEmbeddings(
deployment="<your deployment name>",
model="text-embedding-ada-002", # the embeddings model from openai
openai_api_key='<your azure openai api key>',
openai_api_base="<your openai api base>",
openai_api_type="azure",
)
# initialize langchain vectorstore(pinecone) object
text_field = 'text' # key of dict that stores the text metadata in the index
vectorstore = Pinecone(
index, embed.embed_query, text_field
)
# initialize LLM object
llm = AzureChatOpenAI(
deployment_name="<your deployment name>",
model_name="gpt-35-turbo",
openai_api_key='<your azure openai api key>',
openai_api_version = '2023-03-15-preview',
openai_api_base="<your openai api base>",
openai_api_type='azure'
)
# initialize vectorstore retriever object
timekeeping_policy = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
)我在使用Azure OpenAI部署LLM和嵌入模型,但也应该与platform.openai.com的OpenAI同行一起使用。
员工数据工具
数据帧(dataframe)是 Python 对象,它包含表格数据(类似于带有行与列的电子表格)。我们将数据帧(df)提供给 LLM,使用 Python 语法允许它对数据帧进行操作。
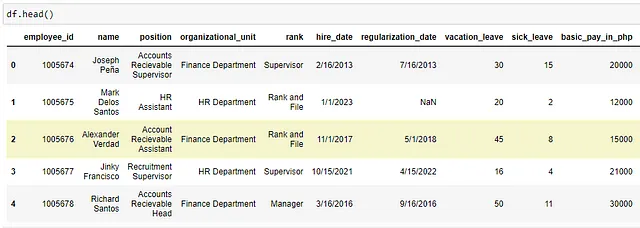
例如,这个Python代码:
df[df['name'] == 'Alexander Verdad']['sick_leave'] df[df['name'] == 'Alexander Verdad']['病假']
在数据框中过滤出列“name”值等于“Alexander Verdad”的行。过滤行后,输出该行列名为“sick_leave”的值——即“8”天病假。
简而言之,用户的自然语言查询(“我还剩多少病假”)被LLM转换为Python语法,以便从数据帧中提取回答查询所需的信息。以下是示例:

“用户”是一个占位符,根据当前登录聊天机器人的人不同而改变。例如,如果用户是“Richard Santos”,LLM将为相同的自然语言查询返回不同的Python操作,并且将返回不同的输出(11天病假)。
df[df['name'] == 'Richard Santos']['sick_leave'] df[df['name'] == 'Richard Santos'][‘病假’]
LLM 使用 Python 操纵 dataframe,使用 Python REPL - 一个交互式 Python shell,可以立即运行并输出代码结果。我们使用 LangChain 提供的包装器,以便工具可以访问 dataframe。
对于这个原型,我正在使用SAP人力资源(SAP HR)测试系统作为数据源,并通过定期运行的数据管道将员工数据作为csv文件落地到Azure数据湖(ADLS2),然后由聊天机器人加载为数据框架。想法是,LLM引用的员工数据必须经常保持与源系统的更改同步。
Python REPL 工具可以执行可修改数据框中值的操作(例如通过恶意行为者注入提示),因此最好让 LLM 访问中间数据存储(csv 文件),而不是直接访问源系统(SAP HR)。
LLM 在使用时与英语兼容性最佳。我发现如果数据框列名尽可能具体描述,它会更加有效。当使用SAP的默认字段名时,它会遇到困难。例如,SAP的就业状态字段名被称为“员工组”,员工等级被称为“员工子组”,以此类推。
将SAP字段名称转换为描述性列名称是数据流水线的一部分。我正在使用Synapse Pipelines / Azure Data Factory。您可以在此处查看有关Azure数据流水线的文章。
这不是一个必需的步骤,直接从您的本地机器加载csv文件到数据框架中同样有效。
“员工资料”工具实施:
import pandas as pd
from azure.storage.filedatalake import DataLakeServiceClient
from io import StringIO
from langchain.tools.python.tool import PythonAstREPLTool
# create emloyee data tool
client = DataLakeServiceClient(
account_url="https://synapsedl50415.dfs.core.windows.net",
credential="<your azure storage account access keys>"
) # authenticate to azure datalake
# azure data lake boilerplate to load from the file system
file = client.get_file_system_client("synapsefs50415") \
.get_file_client("employee_data/employee_data.csv") \ # the data pipeline output (csv file)
.download_file() \
.readall() \
.decode('utf-8')
csv_file = StringIO(file)
df = pd.read_csv(csv_file) # load employee_data.csv as dataframe
python = PythonAstREPLTool(locals={"df": df}) # set access of python_repl tool to the dataframe计算器工具
ChatGPT 在数学方面声名狼藉。它甚至在最简单的算术推理(例如,解决数学问题)方面也很吃力。 GPT-4 已经进步了,但仍然表现远低于我们对 AI 的期望。已经有许多努力来补充这种局限,例如 Wolfram Alpha 插件为 ChatGPT 提供帮助。
我们聊天机器人中使用的计算器工具也是这类补充之一。这是LangChain使用NumPy中的numexpr包实现的数学工具。
LLM 应该在遇到与数学/算术相关的任务时使用此工具,而不是独立进行计算。
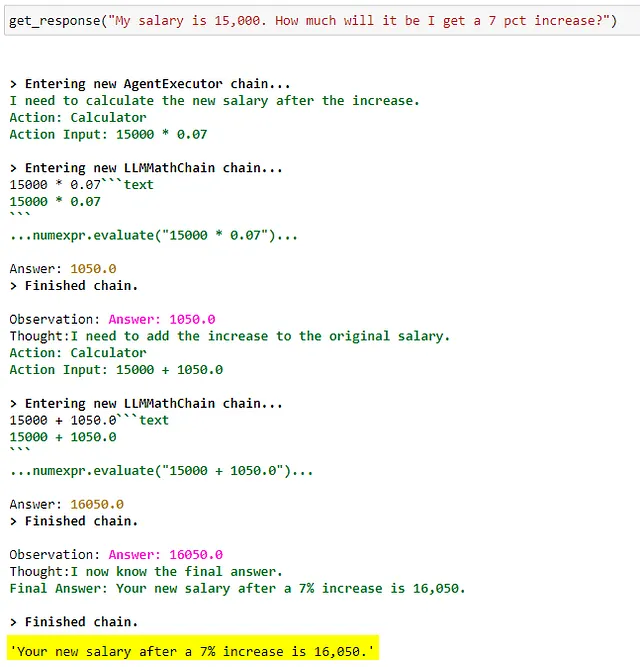
计算器工具的实现:
from langchain import LLMMathChain
# create calculator tool
calculator = LLMMathChain.from_llm(llm=llm, verbose=True)现在我所拥有的就是这些。我仍在积极测试这个原型,并会在新的见解/观察方面编辑此帖子。随时回来看看。
感谢阅读!