构建一个无状态、符合OpenAI规范的聊天机器人:无缝集成人工智能的指南
介绍
现如今,人工智能(AI)的发展已成为寻求创建新项目的个人和企业的热门数字趋势。AI可以帮助您从零开始建立一个新项目,或者通过与所有最新的AI模型进行集成,将其融入现有项目中。
将人工智能整合到语言学习模型(LLMs)中相对较简单,这要归功于近年来大量发布的资源。
建议使用Python和Typescript语言,因为它们提供了一长串与人工智能和语言模型兼容的库和框架。
在这篇文章中,我将指导你如何成功创建一个由OpenAI提供支持的符合API标准的聊天机器人的过程。
需求:
您可能会想为什么现在应该创建一个聊天机器人。有很多理由,但我想在下面重点介绍一些主要原因:
1. 对常见问题的回答:在文档页面中寻找答案可能会很繁琐。即使页面底部有最常见的常见问题解答,也可能不够有帮助。而且,要找到正确的问题,您必须导航到正确的部分。有一个友善的助手来解答您的疑问是否更容易呢?
2. 摒弃一级支持:在企业环境中,客户经常会对应用程序遇到基本问题,每次都需要联系支持部门。对于客户和支持员工来说,对每个支持请求作出回应是浪费时间的。此外,一级支持可能对最新开发的功能不了解,导致解决时间更长。通过使用聊天机器人,我们可以模拟始终可用并具备适当知识来响应每个请求的一级支持。
3. 帮助支持雇主:真正的挑战之一是减少用户在应用程序中重复工作的量。这可以通过指示聊天机器人在用户的帮助过程中做出一些决策来实现。聊天机器人不仅可以帮助最终用户找到所需的信息,还可以协助他们进行应用程序中最常见的操作。一个由人工智能驱动的聊天机器人是一个非确定性的解决方案,因此我们需要在操作过程中要求用户确认聊天机器人所采取的行动,以应对错误的情况。
简而言之,您需要一个聊天机器人,用于以下几方面:
- 任务自动化- 持续的支持可用性- 成本和时间的降低
为什么现在你应该坚持使用OpenAI API标准?
目前,构建人工智能聊天机器人有许多方法。您可以通过在市场上选择许多SaaS选项之一来构建您的聊天机器人,例如亚马逊Lex、IBM Watson助手和Azure Bot服务。
那么,为什么您应该使用OpenAI API来构建您的聊天机器人呢?
迅速传播的OpenAI的受欢迎程度:2020年11月,OpenAI发布了ChatGPT后,该模型的使用迅速增加。因此,AI社区实现了许多兼容的库。
开放AI API功能:会话API允许您与经过训练的LLM进行对话,模拟助手和用户之间的聊天。
谈到对话式API,OpenAI主要决定功能的实现。因此,坚持这一标准意味着当有新功能引入时,你有可能成为第一个使用该功能的人,从而使你的聊天机器人比不使用OpenAI APIs的聊天机器人具有显著优势。
两个改变游戏规则的特性是函数调用和可流式响应。
功能调用:功能调用允许您在API请求中提供一个或多个函数签名,用于两个模型`gpt-3.5-turbo-1106`和gpt-4-1205-preview(本文时刻的最新模型)。
这些函数签名被分析并转换为LLM可理解的语法,使得模型能够理解用户的问题,并用具有正确参数的函数调用作出回应。
这个特性在你需要与外部API交互时特别有用,它使你能够创建一个聊天机器人,通过调用外部API或将自然语言转换为API调用来回答你的问题。
检查下面的例子:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
functions = [
{
"name": "get_users",
"description": "Get all users in a system or get user filtered by a given username",
"parameters": {
"type": "object",
"properties": {
"username": {
"type": "string",
"description": "The username provided, e.g. 'Leeroy Jenkins'",
},
},
},
}
]
messages = [{"role": "user", "content": "Does the user 'Jack' exist?"}]
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
functions=functions,
)
print(completion)
OpenAI API 的响应将是如下内容。
{
"id": "chatcmpl-8GVDlP8bnKlehiMLi3oRumLyfxJ8g",
"object": "chat.completion",
"created": 1698943953,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "get_users",
"arguments": "{\n \"username\": \"Jack\"\n}"
}
},
"finish_reason": "function_call"
}
],
"usage": {
"prompt_tokens": 76,
"completion_tokens": 15,
"total_tokens": 91
}
}
正如预期的那样,它会根据问题提供给我们正确的函数来调用。如果我们没有指定与函数固定匹配的问题,请求将是一个简单的聊天完成 API 请求,使用整个经过训练的LLM知识进行回应。
可流式播放模式
如果在聊天完成的POST请求响应数据中,流布尔参数为真,则使用服务器端事件以块的形式输出数据。这种模式非常有用(特别是对于长响应),因为我们可以提供更好的用户体验,给人一种问题的响应更快的印象。
再次检查以下示例!
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Respond with \"Supercalifragilisticexpialidocious\""}
],
stream=True
)
for chunk in completion:
print(chunk.choices[0].delta)
{
"role": "assistant",
"content": ""
}
{
"content": "Sup"
}
{
"content": "erc"
}
{
"content": "al"
}
{
"content": "if"
}
{
"content": "rag"
}
{
"content": "il"
}
{
"content": "istic"
}
{
"content": "exp"
}
{
"content": "ial"
}
{
"content": "id"
}
{
"content": "ocious"
}
{}
分析建筑
为了开始分析架构,我们必须首先确定我们想要实现的属性:
- OpenAI API 密钥匿名化:我们的聊天机器人逻辑必须隐藏来自客户的 OpenAI API 密钥。否则,任何客户都可以使用我们的 OpenAI API 密钥访问所有的 OpenAI 高级功能,而这显然不是我们想要的。
- 无神论业务逻辑:我们的聊天机器人应该独立于我们选择实施的后端环境。这意味着如果需要,我们应能轻松切换到另一个聊天机器人环境。
多租户逻辑:我们的聊天机器人必须实现多租户逻辑,允许多个客户与同一个聊天机器人实例进行交互,并(可能)访问不同的个人信息。
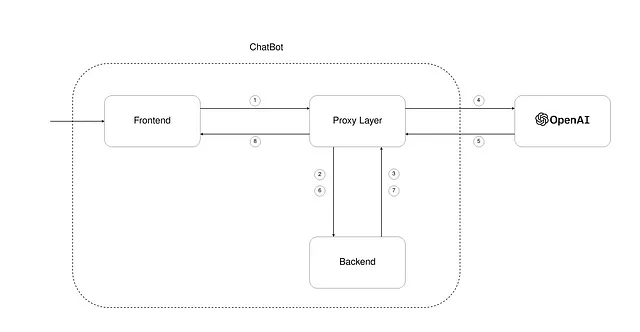
我们的聊天机器人结构由三个主要实体组成。依次为:
- 前端- 代理层 - 后端
沟通流程
在图1中,通信流程描述如下:
1) 用户通过发送消息向聊天机器人的前端部分发送请求。 2) 请求到达代理层,负责将消息转发给后端业务逻辑。 3) 后端将用户请求转换为与OpenAI API兼容的请求,并联系OpenAI以获取响应。 4) 接下来,给定提示和先前生成的上下文,我们准备提出一个OpenAI请求。 5) 从OpenAI生成响应后,它将被发送到我们的代理层,而无需直接联系后端。 6) 后端将收到来自OpenAI的请求并执行必要的解析。 7) 一旦响应被正确解析(并最终触发其他操作),响应将准备好发送回前端。 8) 响应现已准备好作为聊天机器人的回复返回给用户。
前端
这是我们聊天机器人的入口点。前端定义了我们聊天机器人的用户界面/用户体验,使用户能够与底层系统进行通信。与每个聊天机器人一样,通信是双向和同步的。
这意味着如果已经有一个请求被提交并且正在处理中,用户将无法发出另一个请求。有关前端设计和架构的更多信息将在接下来的文章中提供。
代理层
代理层对于保持我们的聊天机器人OpenAI API兼容是必不可少的。这是通过使用与OpenAI相同的请求和响应格式来实现的。但是我们怎么获得这些呢?我们所做的是查看OpenAI API参考,并重建了与OpenAI使用聊天对话API进行通信所需的模型和API。
我们在swagger.yaml文件中定义了所有这些API和相关模型,用于表示客户端和服务器之间的通信约定。使用这个swagger文件,我们可以通过使用一个代码生成库来生成客户端和服务器。以这种方式处理,如果OpenAI API更改其API版本,我们只需要修改我们的API,然后我们将保持兼容性。
这种代理架构的最大优势是,如果你找到一个与OpenAI聊天完成API接口的很酷的库,你将自动与聊天机器人兼容,因为它们将使用相同的API格式。作为一个实际的场景,想象一下你需要将你的聊天机器人与一个与OpenAI通信的前端库集成。显然,这个前端库(可以使用任何编程语言集成!)将期望使用它的API参考与OpenAI通信。
而不是使其与OpenAI进行通信,我们将我们的代理层放在通信堆栈的中间,使其与前端库进行交互。
后端
上下文聊天的实际实现将负责处理我们架构中的最后一个节点上的通信。它将负责向OpenAI询问给定用户问题的响应。需要提到的是,通过使用代码生成,我们可以快速实现我们想要的任何语言的后端。关于后端的更多内容将在接下来的文章中介绍。
结论
由于这个原因,我们最终建立了一个会使您简化与任何基于上下文的聊天机器人以及任何基于语言的库交互的聊天机器人。此外,您可以将逻辑从您的后端或前端实现中解耦。
这意味着您不必每次在后端或前端重新实现您的自定义逻辑,通过指定聊天机器人应该如何行为。如果这篇文章引起了您的兴趣,请保持更新,了解更多有关前端和后端技术细节的内容!