LLM系列#1:使用Azure迅速提升技能的捷径
无需繁杂的编码,保持HTML结构

欢迎,AI探险家!如果你曾经为了微调一个大型语言模型而苦苦挣扎,那么你并不孤单。这常常就像是试图教猫捡球一样理论上可能,但实际上呢?那又是另外一回事。😅 我们将从Azure开始,我将向你展示Azure不仅仅是个漂亮的名字和一个酷炫的logo。它是你在AI库存中从未知晓却又需要的秘密武器。我们将深入探究Azure的能力,展示它如何将常常似乎不可完成的微调大型语言模型的任务变得轻而易举。或者至少,可管理的一次远足🔆。所以请紧跟潮流,准备好快速掌握微调技巧!
我们先从基础开始,我知道你们很多人已经了解这些概念,但是复习一下永远不会太晚。
什么是LLMs?
在最简单的术语中,LLMs是一种生成式人工智能,它可以根据从大量数据集中获得的知识来识别、生成甚至预测文本。
多庞大?GPT-3是在570GB至45TB的数据之间训练的,而570GB大致相当于约3000亿个字!!!
大语言模型就像数据海绵一样,吸收并从数十亿数据点中学习。它使用一种被称为Transformer模型的神经网络架构来实现这一点。底层的Transformer是一组由编码器和具有自注意力能力的解码器组成的神经网络。您可以在这里了解更多关于基本Transformer架构的信息。
什么是微调?
微调是指对已经训练过的LLM进行调整,使用较为具体和更小的数据集来进行特定任务的定制化。LLM的预训练使其具有对语言的广泛理解,这意味着很大一部分的开发工作已经完成。就像在LLM已经拥有的广泛理解的基础上增加一层专业知识。通过这种自定义训练,模型可以在特定领域(例如聊天、翻译、摘要等)成为一个专家,以满足您的各种需求。
为什么要进行微调
精调是优化预训练模型(如GPT)的关键步骤,使其能够专注于特定任务。一个贴切的类比是将一辆通用型车辆转变为高性能赛车。
将预训练的GPT模型视为一辆标准工厂制造的汽车。这辆汽车被设计用于一般用途,在日常场景中表现良好,就像GPT模型在各种数据上进行训练一样。但是,如果您计划将这辆汽车参加一场方程式赛车比赛,那么它的表现就不会像专门为高速赛车进行“调校”的专用赛车那样出色。为了在同一竞技场上竞争,您的工厂制造的汽车需要经历重大改装。就像调校后的赛车在方程式赛车比赛中优于工厂制造的汽车一样,调校后的LLM在其专门领域中的表现优于一般LLM。
对于精调相关的各种“W”的最佳解释,我强烈推荐阅读Michiel De Koninck所写的这篇杰出文章。
让我们从Azure OpenAI开始,在您开始进行微调之前,您需要满足以下先决条件:
- 一个Azure订阅。如果您还没有一个,您可以在这里创建一个。
- 访问Azure OpenAI订阅
Azure开放AI环境
选择Azure OpenAI服务的原因不仅在于其拥有强大的语言模型,包括GPT-4、3.5 Turbo和Embeddings模型系列,还在于它通过REST API、Python SDK或基于Web的界面在Azure OpenAI Studio中提供的灵活访问方式。另一个主要原因是微软保证您的个人或组织数据不会被分享或用于LLM训练。
让我们熟悉一下环境。获取访问权限后,您的资源页面将会呈现如下方式:
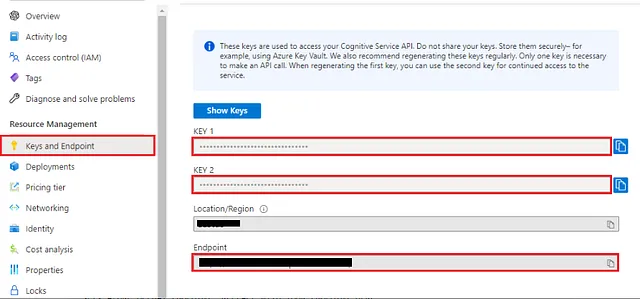
此页面提供多种选项,包括资源概述、资源访问控制和密钥与成本的详细信息。如果你计划通过 API 调用或微调你的模型,你将需要密钥和终端点详情。然而,由于本文主要关注最小化编码,我们的大部分工作将在 Azure OpenAI Studio 的 web 界面中进行,可以从下面显示的概述页面导航到该界面。
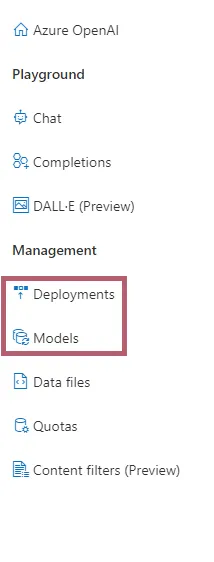
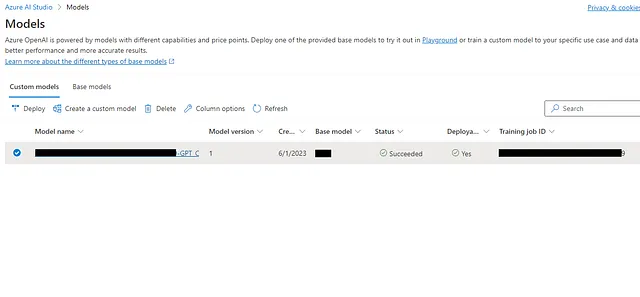
有多个标签,但我们主要关注“部署”和“模型”标签以进行微调。 "模型"标签包含可用的基础模型和我们用我们的数据和格式微调的自定义模型。“部署”标签显示您从“模型”标签中可用的列表中部署的模型,以及任何自定义部署(就像我们在下一步中要做的那样)。
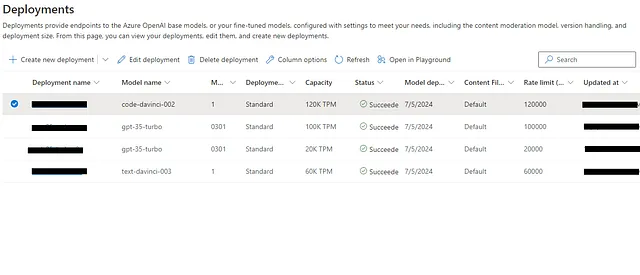
“部署”选项卡还提供了模型版本、令牌容量的概览,并提供创建新基础模型或自定义部署的选项。
创建数据集
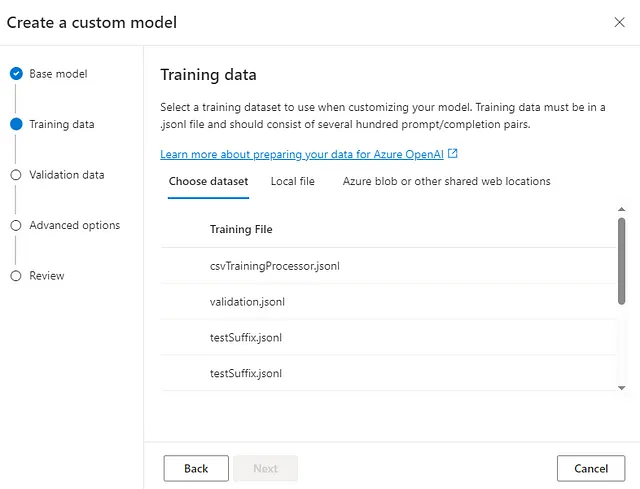
接下来的步骤涉及创建微调数据集。在OpenAI Studio中无法直接执行此任务,因为微调作业需要一个特殊格式的JSONL训练文件。虽然我不会在此添加数据清洗和质量检查的详细信息,但请始终确保清洗数据以创建高质量的示例,因为低质量的示例可能会对模型的性能产生负面影响。
在这里,我做的只是对Python中的数据集进行导入、清洗并转换为所需的格式,以便进行微调,如下所示。
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "What?"}, {"role": "assistant", "content": "."}]}
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "Who?"}, {"role": "assistant", "content": "?"}]}
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "How?"}, {"role": "assistant", "content": "."}]}
此格式包括三个角色:系统、用户和助手。
⮞ “System”角色作为主要提示,指导模型在对话中的行为。 ⮞ “User”角色代表用户可能提出的问题类型。 ⮞ “Assistant”角色反映了模型对用户查询应如何回应。
根据此格式,您需要创建两个文件training.jsonl和validation.jsonl。一个用于优化模型,另一个用于测试其性能。
df = pd.read_json("training.jsonl", orient='records', lines=True)
dfv = pd.read_json("validation.jsonl", orient='records', lines=True)
我们将把这些文件上传到工作室,剩下的工作将通过网络界面直接完成。只是一个建议,在对专有数据进行微调时,始终要确保数据质量和删除个人可识别信息(PII)数据,因为隐私成为一个关键考虑因素,模型可能会无意中记忆和再现敏感信息。
选择模型
在Azure Studio中,可供微调的模型包括GPT-3.5-Turbo(0613版本),巴贝奇-002和达芬奇-002。需要记住的一件事是,GPT-3.5-Turbo(0613)仅在特定地区可用,您可能需要使用该地区的订阅才能使用它(并始终关注新可用地区的更新)。
** babbage-002 和 davinci-002 并没有接受过按照指示行动的训练。
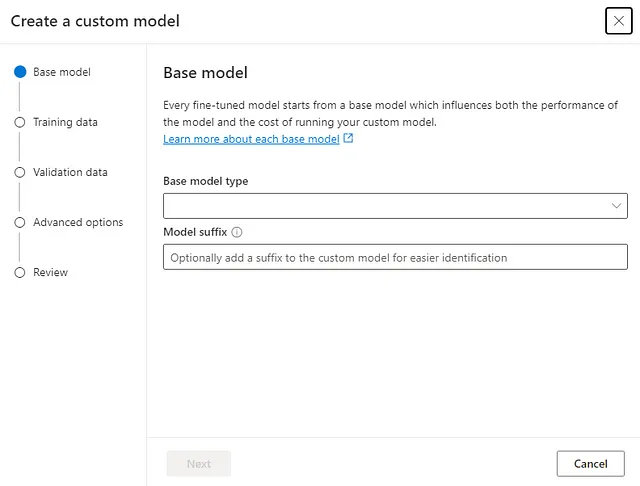
我们将通过在模型选项卡中创建一个自定义模型选项来创建部署,这将弹出上述屏幕。我们将选择最新提供的GPT-3.5-Turbo (0613)模型,然后选择我们之前在Python中创建的训练和验证数据集。
执行微调
在接下来的步骤中,我们集中关注选择微调的超参数的关键任务。这些超参数包括:
迭代次数:模型训练的迭代次数
批大小:用于训练单次通过的训练样例数量
学习率:微调学习率是预训练中使用的原始学习率乘以这个值。
提示减肥:控制模型在学习从给予的指示中获得的专注程度。
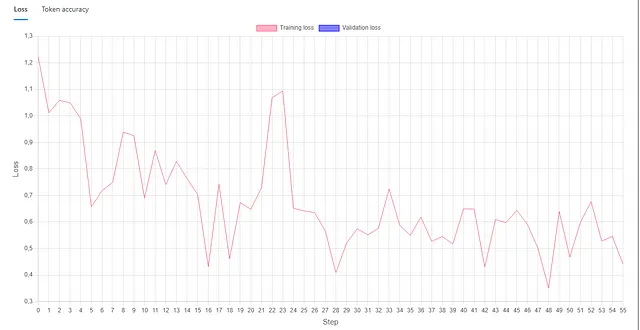
一切准备就绪后,我们可以开始微调工作。此过程的持续时间取决于数据集的大小。就我个人而言,由于我的数据集相当小,而且我仅针对较少的时代排队,所以这个过程大约花了4个小时。在微调工作完成后,我们可以查看指标来评估我们的训练情况。正如您所见,我的微调工作仍有很大的改进空间。
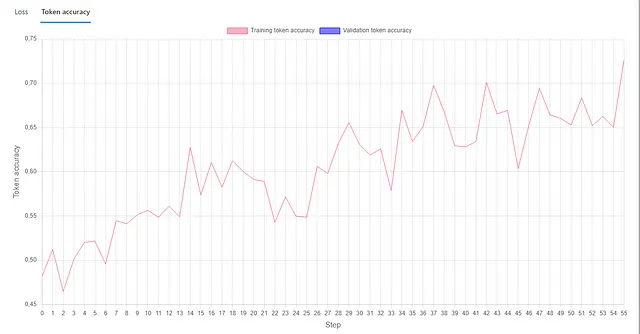
如果您对模型的不同版本进行了微调或使用了不同的数据,您可以像下面显示的那样单独检查每个实例。
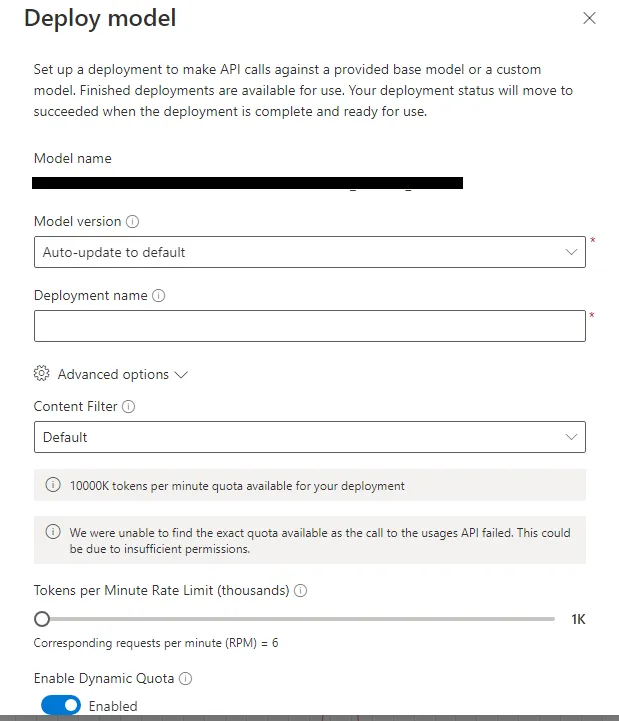
部署模型
最后,我们对我们的精调模型进行了一些测试,如果符合期望,我们可以通过在部署选项卡中创建新的部署选项将其部署用于常规使用。这将打开一个窗口,在那里我们可以选择我们的精调模型,配置速率限制,并通过内容过滤器选择要屏蔽的内容类型。
而且,就是这样,TADA!我们的模型已经准备好用了。如果你觉得这太容易,或者你有一个开发者思维,想通过代码来执行所有这些步骤,你可以参考这个指南。
此外,请不要忘记在评论部分分享您在微调过程中的经验和方法,以及任何您发现有用的有趣工具或指南,这样我们所有人都有机会相互学习。
如果你仍然感觉需要学习更多,这里是由OpenAI、Cohere和AI21共同开发的关于LMM部署最佳实践的指南:《部署语言模型的最佳实践》(openai.com)。
那就是今天的内容,但是不要担心,冒险还会继续!在 LLM 系列的下一章中,我们将看看 GPT 模型的功能调用能力。如果这个指南激发了你的好奇心,并且你希望在这个 LLM 系列中探索更多令人兴奋的项目,一定要关注我。对于每个新项目,我承诺带给你一次充满学习、创造力和乐趣的旅程。此外:
- 👏为这个故事鼓掌(50次鼓掌),帮助这篇文章成为特别推荐。
- 🔔跟着我: 领英 | Medium | 网站 | 有人工智能问题吗?
参考文献
- 注意力就是你所需要的。
- Google研究人员成功让ChatGPT揭示其训练数据,研究报告(businessinsider.com)
- 微调还是不微调?| Michiel De Koninck作品 | ML6团队
- 部署语言模型的最佳实践(openai.com)
- Azure OpenAI微调教程