抄袭ChatGPT是否实际可行?
从世界各国政府到先锋模型拥有公司,每个人都开始分析生成模型所带来的风险,以及将这项技术交到错误的人手中可能产生的后果。在十月底,拜登政府发布了一项命令,旨在确保人工智能的安全和受控使用。高风险人工智能的要求之一是进行红队测试以识别安全漏洞,同时采取物理和网络安全措施来保护模型权重。Anthropic的一位高级领导人Jason Clinton还告诉VentureBeat,他们将大部分资源用于保护包含通用人工智能模型权重的一个文件。Open AI也宣布了一个漏洞赏金计划,邀请研究人员发现系统中的漏洞,以保护GPT模型,尤其是模型权重。中国互联网技术公司字节跳动已经被抓到试图使用Chat GPT模型输出来训练自己的人工智能聊天机器人。
为什么要采取措施保护模型权重和模型架构?
模型的权重和架构被视为宝贵的知识产权,因为它们代表了长时间计算、大量精心选择的数据、算法、架构以及熟练研究人员对它们进行的勤奋实验的独特状态。如果落入错误角色的手中,可能会带来危险。
恶意行为者可以
- 获得模型所需的训练费用。避免通过API获取目标模型的费用,或是将目标模型复制并进行利润获取。
- 使用这些模型,生成假身份和信息来欺骗和误导容易受骗的人群。
- 可能将这些模型误用于生物武器的发展。
- 敏感专有信息泄露,目标模型已经训练完成。
我将继续探讨一种可能的方式,即如何攻击Gen AI模型以窃取其权重和架构。
实用模型窃取指南
传统上,对模型的盗窃可以通过使用模型的直接属性,如模型输入、模型输出、模型算法,或者通过使用诸如模型推理时间或内存访问、模式或利用物理特性(如电磁辐射或功耗)的侧信道进行。
但由于LLMs的规模巨大,使用这些方法来有意义地提取整个模型是困难的。但研究人员仍然发现了利用LLMs的漏洞并创建副本模型的方法。
使用模型直接属性窃取机器学习模型的一种流行方法是替代模型攻击。这是一种基于查询的攻击,攻击者假设通过API或应用程序对模型具有黑箱访问权限。然后,攻击者向目标模型发送查询并获取结果输出,并使用这些信息来训练替代模型。攻击者的目标是训练一个与目标模型相似的替代模型。
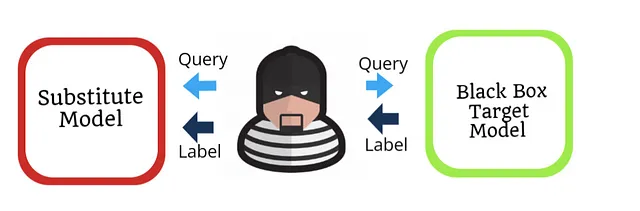
替代模型攻击导致了其受欢迎的原因。
- 您不需要访问目标模型所训练的原始训练数据集。用于训练替代模型的数据集可以是公共数据集或由Gen AI生成的人工数据集。在《THIEVES ON SESAME STREET!》一文中的研究中,作者展示了即使使用随机抽样的词序列,也可以提取出一个bert模型。
- 它们很便宜。有许多提出的方法来优化对原始模型的查询数量,例如使用主动学习、生成对抗网络(GANS)和抽样技术。这些技术的结合可以显著减少对API的查询。
但是这种方法将如何用于LLMs呢?您能通过替代模型攻击来窃取大型模型吗?
由于培训LLMs所需的费用和时间较大,它们成为了很好的目标。然而,创建一个具有与目标模型相同能力的替代模型仍然是昂贵的。但最近的研究[4]表明,一个通用的LLM可以用于微调一个小型模型,以完成特定任务,如代码翻译。
根据研究论文,当评估编译正确性的通用模型LaMDA(137B)时,其结果仅为4.3%;而编码具体模型Codex(12B)则获得了81.1%。
因此,一个小型模型,在特定任务的数据上进行微调,可能比大型通用LLM表现更好。而且,使用通用LLM生成的数据非常容易训练小型微调模型。对于许多自然语言处理和编程相关任务来说,通用LLM生成的数据比公开可用的数据要好得多。当对使用公开数据和通用LLM生成的数据进行微调的代码T5模型进行对比时,使用通用LLM生成的数据,模型性能提高了一倍。因此,对手可能希望使用模型API来收集数据并训练一个小型模型,以避免使用API的成本。Github每月向个人收费10美元以使用他们的编码副手。对手也可以部署自己的模型以获取利润。
随着人工智能的进步,对模型的攻击也会不断出现。将开发利用模型漏洞的新方法。在机器学习的历史上,训练模型的成本从未如此之高,因此可能的偷盗的回报也变得巨大。有趣的是,机器学习模型主要被机器学习技术所利用。这几乎就像一个进退两难的境地。目睹人工智能如何保护自己充满了趣味性。
参考资料:
Daryna Oliynyk, Rudolf Mayer 和 Andreas Rauber。2023年。我知道你去年训练了什么:关于盗取机器学习模型和防御的调查。ACM 计算机调查。55卷,14s期,324篇文章(2023年12月),41页。https://doi.org/10.1145/3595292
- 苏哈姆·帕尔(Soham Pal)、亚什·古普塔(Yash Gupta)、阿迪蒂亚·舒克拉(Aditya Shukla)、阿迪蒂亚·卡纳德(Aditya Kanade)、希里什·谢瓦德(Shirish Shevade)和维诺德·加纳帕蒂(Vinod Ganapathy)。2019年一种利用公共数据提取深度神经网络的框架。https://arxiv.org/pdf/1905.09165.pdf
- Thieves在芝麻街上!BERT-based API的模型提取:alpesh Krishna和Gaurav Singh Tomar和Ankur P. Parikh和Nicolas Papernot和Mohit Iyyer https://arxiv.org/pdf/1910.12366.pdf
- 在从大型语言模型中提取专业代码能力方面的可行性研究: 李宗杰,王朝正,马平川,刘朝伟,王帅,吴道源,高翠云,刘洋。







