使用ChatGPT和Azure AI Vision生成图像字幕(Alt文本)

想象一下这种情景,你的网站上有成千上万张图像,但却没有标题... 逐个手动添加标题的想法比起学习新知识并撰写一篇博客文章来说,显然没有吸引力,所以我们现在就在这里!
对于那些不了解的人来说,Alt文本是与网页上的图像相关联的不可见标题。最好的做法是为每个图像都设置一个Alt文本。
世界上有数亿视觉受损的人,其中许多人依赖于屏幕阅读器。替代文本描述了人们无法亲自看到的图像。
"大不了!"我听到一些人大喊道,"我没有时间去关注无障碍。我还有截止日期呢!"
好吧,我不会对截止日期提出异议,但你可能会为SEO腾出时间。Alt文本被谷歌和其他搜索引擎用于帮助索引你的网站。它还可以帮助你的产品在谷歌和Etsy等市场网站的图像搜索结果中出现。
直到最近,仅人类才能用自然语言描述图像。但现在不再如此...
计算机视觉历史:图像分类
在不到十年前(2014年),当Randall Munroe在XKCD上发布这个漫画时,图像分类是一个复杂的问题:

然而不到十年后,我们认为这是相当琐碎的。现在有许多图像分类模型和教程可以免费获取,例如来自Hugging Face。
分类是将图像进行处理并为其内容应用一个或多个标签的过程,通常还会对结果分配一个概率(例如,有98%的可能是一只猫,有0.05%的可能是一只神奇的双齿脊椎动物)。
然而,对于我们的替代文本问题,仅仅将我们的产品图像标记为“猫”是不够的。一个好的替代文本应该描述该图像。“有90%的可能性这是一只猫”也不一定能满足SEO团队的要求。
语义基础与多模态学习
语义基础是一个术语,用于描述AI模型将语言概念与其他感官输入(例如图像或视频)相连接的方式。基本上,它是关于在词汇和它们所描述的物理世界之间建立联系。
多模态AI模型是训练在多种输入类型(例如图像和文本)上,以推断这些联系。
这是一个很大的进步,超越了简单的图像分类,使得这样的模型可以执行任务,比如:
- 图像字幕:为图像生成文本描述。
- 视觉问答:根据图像内容回答问题。
用难度极高的雙語理解技巧實現視覺與語言敏感度,意味著模型在將圖像和文本的內容分開理解的同時,還要理解它們之間微妙的關係。地域化任務所涉及到的知識包括對視覺和語言暗示的高深理解。
聊天GPT的愿景
每个人都知道Chat GPT可以进行对话,但很多人没有意识到Chat GPT 4是一个多模态模型。它可以分析文本和图像,使其成为解决我们小小的Alt文本问题的完美工具。
通过Chat GPT网站上的简单提示,我们可以要求它描述我们的产品(比如这个极客风格的杯子)并生成我们的备选文本输出。
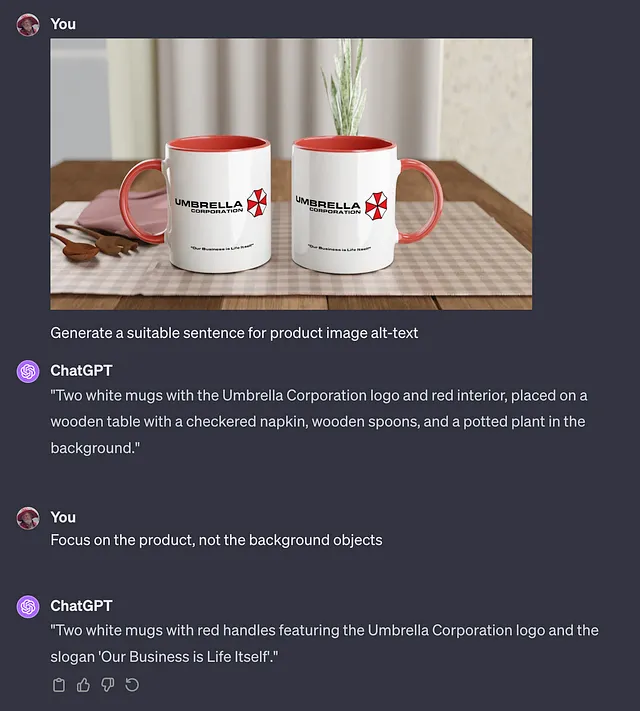
这几乎太容易了!请注意它不仅能理解图像中的对象,还能理解它们之间的关系(即“背景对象”)。
现在我们知道该要求什么,我们可以轻松地将其包装成一段Python代码,并自动地为我们的每个图像调用它。
from openai import OpenAI
client = OpenAI(
api_key="** OPENAI KEY **"
)
def generate_alt_text(image_url):
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Generate a suitable sentence for product image alt-text. Focus on the product, not the background objects."},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=4096,
)
if __name__ == "__main__":
text = generate_alt_text("https://i.etsystatic.com/45823779/r/il/4f38a8/5516029834/il_1588xN.5516029834_sn85.jpg")
print(text)
运行此演示脚本对这个Stardew Valley杯子生成以下字幕:
五颜六色的陶瓷杯,黄色手柄,一侧上面有一个带有增益效果的“茶艺品”标签,另一侧描绘了一个充满活力的“星露谷”农场场景。
令人难以置信!现在由于这是ChatGPT,我们可以通过将产品描述与提示信息连接起来来轻松增加输出。这可能有助于搜索引擎优化,通过添加无法从图片中轻松确定的关键词来实现。
生成适合产品图像的替代文本句子。注重产品本身,而非背景物体。考虑到额外的产品文本:“15盎司星露谷杯”。
返回了几乎完美的句子:
“15盎司星露谷谷物杯:一款鲜艳的黄色杯子,带有游戏内风格标签,标注为‘茶叶 — 工艺品’,详细介绍了能量和健康加成等增益效果。”
我认为我自己做不出更好的了!
Azure AI Vision / Microsoft Florence Azure AI 视觉 / 微软 Florence
ChatGPT 并非免费,而且目前访问 GPT-4 视觉模型是受限制的。幸运的是,这并不是唯一的选择。
微软已经创建了一个名为“Florence”的多模型模型,它生成了令人惊叹的结果,并且甚至可以返回边界框、类别和OCR文本。它托管在微软的Azure云上。
Azure AI Vision 提供的完整功能套件包括:
- 可识别的物体
- 一个图像的标题(与Chat GPT Vision类似)
- 一个浓密的标题,不仅描述图像,还描述图像中的特定区域。
- 对象及其位置(边界框)
- 人们
- 文本 (OCR)
- 裁剪建议(适用于确定适合裁剪缩略图的位置)
Microsoft已经创建了一个很好的教程,让您在Azure上进行设置和开始使用Microsoft Vision。
让我们试一试!以下代码以图像的URL作为输入,并打印出模型生成的信息:
import load_secrets
import time
import pprint
import azure.ai.vision as visionsdk
def analyse_image_async(image_url: str):
"""
Analyze image from URL, asynchronous (non-blocking)
"""
service_options = visionsdk.VisionServiceOptions(load_secrets.endpoint, load_secrets.key)
vision_source = visionsdk.VisionSource(url=image_url)
analysis_options = visionsdk.ImageAnalysisOptions()
analysis_options.features = (visionsdk.ImageAnalysisFeature.CROP_SUGGESTIONS |
visionsdk.ImageAnalysisFeature.CAPTION |
visionsdk.ImageAnalysisFeature.DENSE_CAPTIONS |
visionsdk.ImageAnalysisFeature.OBJECTS |
visionsdk.ImageAnalysisFeature.PEOPLE |
visionsdk.ImageAnalysisFeature.TEXT |
visionsdk.ImageAnalysisFeature.TAGS)
image_analyzer = visionsdk.ImageAnalyzer(service_options, vision_source, analysis_options)
callback_done = False
def analyzed_callback(args: visionsdk.ImageAnalysisEventArgs):
"""callback that signals analysis is done"""
print_result(args.result)
nonlocal callback_done
callback_done = True
image_analyzer.analyzed.connect(analyzed_callback)
image_analyzer.analyze()
while not callback_done:
time.sleep(.1)
def print_result(result: ImageAnalysisResult):
if result.caption is not None:
print(" Caption:")
print(" '{}', Confidence {:.4f}".format(result.caption.content, result.caption.confidence))
# etc. Snipped for brevity
if __name__ == '__main__':
analyse_image_async("https://i.etsystatic.com/45823779/r/il/4f38a8/5516029834/il_1588xN.5516029834_sn85.jpg")
在保持HTML结构的前提下,将以下英文文本翻译为简体中文:使用与我们的ChatGPT示例相同的Stardew Valley马克杯,运行程序后结果如下:
Image height: 894
Image width: 1588
Model version: 2023-02-01-preview
Caption:
'two mugs on a table', Confidence 0.8097
Dense Captions:
'two mugs on a table', Rectangle(x=0, y=0, w=1588, h=894), Confidence: 0.8097
'a mug with a picture on it', Rectangle(x=785, y=300, w=510, h=479), Confidence: 0.7364
'a yellow and white mug with text on it', Rectangle(x=214, y=301, w=508, h=468), Confidence: 0.7640
'two mugs with pictures on them', Rectangle(x=181, y=296, w=1206, h=578), Confidence: 0.7211
'a close up of a plant', Rectangle(x=883, y=0, w=167, h=316), Confidence: 0.8322
'a yellow letter on a green background', Rectangle(x=840, y=481, w=256, h=73), Confidence: 0.6944
'a wooden spoons on a table', Rectangle(x=0, y=598, w=290, h=136), Confidence: 0.7201
'a close-up of a yellow handle', Rectangle(x=219, y=389, w=170, h=286), Confidence: 0.8220
'a close-up of two mugs', Rectangle(x=295, y=2, w=1045, h=404), Confidence: 0.7562
'a close up of a handle', Rectangle(x=1125, y=387, w=171, h=288), Confidence: 0.8319
Objects:
'Container', Rectangle(x=217, y=314, w=530, h=453), Confidence: 0.6280
'Container', Rectangle(x=792, y=316, w=511, h=469), Confidence: 0.5130
Tags:
'coffee cup', Confidence 0.9426
'tableware', Confidence 0.9313
'indoor', Confidence 0.9262
'mug', Confidence 0.9221
'table', Confidence 0.9137
'drinkware', Confidence 0.8934
'serveware', Confidence 0.8911
'ceramic', Confidence 0.8728
'cup', Confidence 0.8679
'pitcher', Confidence 0.8463
'coffee', Confidence 0.7267
'plant', Confidence 0.5999
People:
Rectangle(x=892, y=619, w=25, h=44), Confidence 0.0013
Crop Suggestions:
Aspect ratio 1.95: Crop suggestion Rectangle(x=66, y=112, w=1456, h=745)
Text:
Line: 'Tea', Bounding polygon {437, 428, 492, 433, 492, 461, 435, 458}
Word: 'Tea', Bounding polygon {438, 428, 488, 432, 486, 462, 436, 458}, Confidence 0.6720
Line: 'STARDEW', Bounding polygon {827, 413, 1105, 416, 1103, 488, 826, 483}
Word: 'STARDEW', Bounding polygon {836, 414, 1087, 417, 1087, 488, 835, 484}, Confidence 0.4400
Line: 'Artisan Goods', Bounding polygon {435, 465, 585, 468, 585, 495, 434, 491}
Word: 'Artisan', Bounding polygon {437, 465, 505, 467, 504, 494, 435, 492}, Confidence 0.8320
Word: 'Goods', Bounding polygon {510, 467, 585, 469, 584, 496, 509, 494}, Confidence 0.9960
Line: 'VALLEY', Bounding polygon {851, 480, 1079, 483, 1078, 541, 850, 539}
Word: 'VALLEY', Bounding polygon {852, 480, 1071, 485, 1070, 541, 851, 540}, Confidence 0.9060
... snipped ...
尽管响应中包含了比ChatGPT更多的细节,但模型构建的总体标题较弱:
桌子上有两个杯子
注意:我怀疑使用Florence-2会得到更好的回答,你可以将其作为进一步训练的基础模型。
然而,就是因为ChatGPT如此强大,即使在处理文字时,我只是把整个回应(包括分类、OCR结果和区域字幕)输入给它:
基于以下的 Microsoft Vision 输出,为图像生成一个替代文字标签:图片高度:894图片宽度:1588模型版本:2023–02–01-preview标题:‘桌上的两只杯子’,置信度 0.8097… 裁剪内容...
哪个产生了更满意的输出结果:
“两个带有Stardew Valley和工艺茶图案的杯子,具有游戏内的效益,在一张带有植物和木勺的桌子上摆放着。”
结论
多模态人工智能模型让人瞠目结舌,而我只是触及到了它们能力的冰山一角。我的思绪充满了各种可能性,比如屏幕阅读器软件与视觉模型的整合,可以让视觉受损者在阅读书籍或浏览网站时“可视化”图像。
在这个世界上有着巨大的潜力,然而在此刻,他们惊人的力量正在用于为我制作备选文本。







