[第二部分] 模型如何工作,例如ChatGPT?- 描绘变压器结构
本文第1部分我们介绍了Transformer架构的基本构建模块。一旦您编写了Transformer模型的基本构建模块并理解它们的工作原理,就可以将它们组合起来了。在本文中,我们将亲自编写一个完全功能的Transformer模型,并在第3部分中使用IWSLT15数据集在云端的GPU上进行训练。
让我们开始吧!
先决条件
Google Colab是一个很好的起点,因为它提供免费的计算资源,包括GPU。它还预装了大多数必要的库,所以不需要手动设置环境。
对于这篇文章,我创建了一个免费访问的笔记本,里面包含了所有的代码。你可以在这里找到这个笔记本。
确保通过点击Runtime>更改运行时类型并选择T4 GPU来将运行时更改为GPU。
将所有内容放在一起
让我们现在开始构建我们的Transformer模型。我们将使用PyTorch,因为它提供了构建模型所需的所有基本功能。
位置编码作为构建块
我们首先要做的是将在第一部分中编写的位置编码函数放入一个代码块中,以便我们可以在模型中使用它。为此,我们将创建一个PyTorch nn.Module类,其中包含位置编码函数,并将其作为forward()函数公开,以供模型训练流程使用:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, device, max_len):
super(PositionalEncoding, self).__init__()
self.pe = positional_encoding(max_len, d_model).to(device)
def forward(self, x):
# We don't want the PE to be part of the positional encoding, therefore we disable gradient tracking
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return x
在此块中,我们预计算PE向量并将它们保存在一个pe变量中。在前向步骤中,我们将PE向量添加到嵌入向量中,即变量x,从而对位置信息进行编码。
嵌入
在《注意力就是你所需要的一切》论文的指导下,我们现在可以实现嵌入块,它将从我们的输入标记创建向量并对其应用位置编码。
from torch.nn import Embedding
class Embeddings(nn.Module):
def __init__(self, vocab_size, d_model, max_len, dropout_p, device):
super(Embeddings, self).__init__()
self.d_model = d_model
self.emb = Embedding(num_embeddings=vocab_size, embedding_dim=d_model)
self.pos_enc = PositionalEncoding(d_model=d_model, max_len=max_len, device=device)
def forward(self, x):
x = self.emb(x)
x = x * math.sqrt(self.d_model)
x = self.pos_enc(x)
return x
在这里,我们使用PyTorch实现的Embeddings来创建一个固定字典和尺寸的查找表。根据设计,在位置编码之前,计算得到的嵌入向量会乘以sqrt(d_model)。
编码器块
为了构建编码器块,我们将使用具有相同架构的层。编码器层包含多个内部块:
- 多头注意力(MHA)-也称为编码器自我注意力,正如之前讨论的那样,它是使用查询、键和值矩阵来计算的。在编码器自我注意力的情况下,这些矩阵包含完全相同的输入嵌入数据。
- 前馈网络(FFN)- 用于增加模型的非线性
- 层归一化——遵循《Attention is all you need》论文的规范,应用于MHA(多头自注意力)和FFN(前馈神经网络)。PyTorch已提供了层归一化的代码,通常用于稳定训练、减少协变量漂移并提高模型泛化能力。查阅《Understanding and Improving Layer Normalization》一文,了解更多关于层归一化的内容。
- 退学 - 也遵循原始架构,在多头自注意力机制(MHA)和前馈神经网络(FFN)之后使用,以减少模型过拟合。同样地,我们将使用PyTorch提供的退学实现。
这是我们的编码器层的代码。
class EncoderLayer(nn.Module):
def __init__(self,
d_model,
n_heads,
d_ff,
dropout_p,
layer_idx):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model=d_model,
n_heads=n_heads)
self.feed_forward = FeedForwardNetwork(d_model=d_model, d_ff=d_ff)
self.self_attn_layer_norm = LayerNorm(d_model)
self.ff_layer_norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout_p)
self.layer_idx = layer_idx
self.n_heads = n_heads
def forward(self, x, mask):
# Compute self-attention and add+norm
_x = x
x = self.self_attn_layer_norm(x)
x = self.self_attn(x, x, x, mask)
x = self.dropout(x)
x = _x + x
# Compute FFN and add+norm
_x = x
x = self.ff_layer_norm(x)
x = self.feed_forward(x)
x = self.dropout(x)
x = _x + x
return x
正如您所见,我们在类构造函数中初始化了所有组件。之后,我们将按照论文架构图的流程来实现forward()函数。
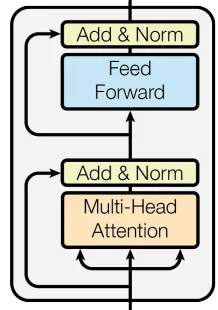
以下是我们将要实施的计算步骤:
- 将原始输入嵌入数据保存在一个临时变量中。
- 在输入嵌入上应用自注意力层归一化
- 在规范化的数据上应用自注意力
- 在自注意力的多头注意力机制输出上应用dropout。
- 将原始输入添加到处理后的输入中
- 将处理后的数据保存在一个临时变量中
- 在处理的数据上应用FFN层归一化
- 在规范化数据上应用FFN
- 在FFN输出上应用dropout
- 将原始处理输出添加到新处理的数据中
所以我们现在已经实现了一个编码器层,并将使用它来实现我们的编码器块。
class Encoder(nn.Module):
def __init__(self,
d_model,
n_heads,
d_ff,
max_len,
vocab_size,
dropout_p,
n_layers,
device):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
n_heads=n_heads,
d_ff=d_ff,
dropout_p=dropout_p,
layer_idx=layer_idx) for layer_idx in range(n_layers)])
self.norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout_p)
self.embs = Embeddings(d_model=d_model,
max_len=max_len,
vocab_size=vocab_size,
dropout_p=dropout_p,
device=device)
def forward(self, x, mask):
x = self.embs(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, mask)
x = self.norm(x)
return x
在这个块中,我们使用源语言词汇表的大小初始化多个编码器层和嵌入层。嵌入层将为词汇表中的每个词生成向量。按照原文的方法,在forward()函数中,我们在嵌入计算之后应用dropout。
解码器块
整体Transformer架构中下一个缺失的部分是解码器模块。如果我们比较编码器和解码器层的架构,可以看到它们只是略有不同。解码器层包含额外的多头注意力机制(MHA),利用编码器模块的输出(即最后一个编码器层的输出)。

我已经用红色和蓝色标记了相同的组件。你可以看到绿色圈内的组件在编码器层中不存在。绿色圈内的MHA被称为解码器交叉注意力,顾名思义,它将缩放的点积注意力应用于编码器和解码器产生的合并数据上。
这是两个不同领域的数据发挥作用的关键点。解码器的交叉注意力负责找到来自两个领域的数据之间的关系,得益于此,我们可以教导 Transformer 模型处理诸如语言翻译、文本到图像、文本到语音生成等任务。
在内部,交叉注意力的结构与自注意力完全相同(即它只是一个MHA块)。唯一的区别在于输入数据,查询和键是相同的矩阵,其中包含来自编码器输出的数据。值矩阵包含来自内部解码器处理步骤(即目标句子嵌入数据)的数据。
正如你们可能已经猜到的,蓝色圈中的解码器 MHA 被称为编码器自注意力,并且具有与编码器自注意力完全相同的功能。
将所有代码放在一起的样子如下所示:
class DecoderLayer(nn.Module):
def __init__(self,
d_model,
n_heads,
d_ff,
dropout_p,
layer_idx):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model=d_model, n_heads=n_heads)
self.enc_dec_attn = MultiHeadAttention(d_model=d_model, n_heads=n_heads)
self.feed_forward = FeedForwardNetwork(d_model=d_model, d_ff=d_ff)
self.self_attn_layer_norm = LayerNorm(d_model)
self.enc_dec_layer_norm = LayerNorm(d_model)
self.ff_layer_norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout_p)
self.n_heads = n_heads
self.layer_idx = layer_idx
def forward(self, x, enc_out, enc_mask, mask):
# Compute self-attetion and add+norm
_x = x
x = self.self_attn_layer_norm(x)
x = self.self_attn(x, x, x, mask)
x = self.dropout(self.self_attn_layer_norm(x))
x = _x + x
# Compute cross-attetion and add+norm
_x = x
x = self.enc_dec_layer_norm(x)
x = self.enc_dec_attn(x, enc_out, enc_out, enc_mask)
x = self.dropout(x)
x = _x + x
# Compute FFN and add+norm
_x = x
x = self.ff_layer_norm(x)
x = self.feed_forward(x)
x = self.dropout(x)
x = _x + x
return
解码器层中信息的流动与编码器层相同,唯一的区别在于额外的交叉注意力计算。因此,以下是实现的方式:
class Decoder(nn.Module):
def __init__(self,
d_model,
n_heads,
d_ff,
max_len,
vocab_size,
dropout_p,
n_layers,
device):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
n_heads=n_heads,
d_ff=d_ff,
dropout_p=dropout_p,
layer_idx=layer_idx) for layer_idx in range(n_layers)])
self.embs = Embeddings(d_model=d_model,
max_len=max_len,
vocab_size=vocab_size,
dropout_p=dropout_p,
device=device)
self.dropout = nn.Dropout(dropout_p)
self.norm = LayerNorm(d_model)
def forward(self, x, enc_out, enc_mask, mask):
x = self.embs(x)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, enc_out, enc_mask, mask)
return self.norm(x)
转换器
在我们继续之前,我想祝贺你走到了这一步。如果你理解了所有讨论过的概念,你正在取得很大的进步。保持良好的心态,让我们继续前进吧!
在我们构建第一个Transformer模型之前,让我们在模型的输出上再添加一个抽象层次。如果你考虑Transformer架构在做什么,它只是简单地预测序列中下一个最可能的单词。Transformer模型被称为自回归模型,意味着每个预测的单词都会作为输入序列的一部分放回到输入中,并用于生成下一个单词。这就是像ChatGPT这样的模型生成输出的方式。其中没有什么大秘密,它只是逐字逐句地创建文本段落,根据从MHA中提取的上下文确定下一个最可能的单词。
预测下一个单词也必须被定义为一个数学概念。Transformer模型只能预测先前见过的单词,这意味着在我们的情况下,只能预测目标语言词汇中的单词。鉴于我们已经对单词进行了标记,并将它们表示为标记,我们需要找到一种方法来确定最有可能的标记,根据我们的解码器块的输出。
编码器输出中的嵌入数据以矩阵形式存在,本身没有具体的语义含义。为了从中提取意义,我们必须提供一个机制来实现这一点。论文《注意力机制就是你所需要的》在编码器块之上添加了一个线性层,它将矩阵形式的数据通过线性投影转换为目标语言词汇表大小的向量。这反过来使我们能够将模型训练为最大化目标语言词汇表中最可能单词的向量组成部分的分类器。
让我们称之为"生成器",并以以下方式编写代码:
from torch import log_softmax, nn
class Generator(nn.Module):
def __init__(self, d_model, vocab, no_softmax=False):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
self.no_softmax = no_softmax
def forward(self, x):
if self.no_softmax:
out = self.proj(x)
else:
out = log_softmax(self.proj(x), dim=-1)
return out
您可以看到,我们对嵌入数据应用线性投影,并使用对数Softmax函数将向量中的值转换为概率。最后,向量组件中具有最高值的索引对应于词汇表中最有可能出现的下一个单词的索引。通过这种方式,可以预测出下一个最有可能出现的单词。
我们现在可以构建我们的转换器,并且我们以以下方式进行:
class Transformer(nn.Module):
def __init__(self,
src_voc_size,
trg_voc_size,
d_model,
n_heads,
max_len,
d_ff,
n_layers,
drop_p,
device):
super(Transformer, self).__init__()
self.encoder = Encoder(d_model=d_model,
d_ff=d_ff,
n_heads=n_heads,
max_len=max_len,
vocab_size=src_voc_size,
dropout_p=drop_p,
n_layers=n_layers,
device=device)
self.decoder = Decoder(d_model=d_model,
d_ff=d_ff,
n_heads=n_heads,
max_len=max_len,
vocab_size=trg_voc_size,
dropout_p=drop_p,
n_layers=n_layers,
device=device)
self.generator = Generator(d_model, trg_voc_size)
def forward(self, src, trg, src_mask, trg_mask):
enc_out = self.encoder(x=src, mask=src_mask)
dec_out = self.decoder.forward(x=trg, enc_out=enc_out, enc_mask=src_mask, mask=trg_mask)
out = self.generator(dec_out)
return out
第二部分结束
在本博客系列的这一章中,我们已经看到了如何构建整个Transformer架构。恭喜您做到了这一点!现在剩下的是训练我们自己的文本翻译Transformer模型。我们将在第三部分讨论这个问题。
如果您对此主题有任何问题或反馈,请随时与我联系。
领英:https://www.linkedin.com/in/penkow/
快乐编码,敬请期待更多!:)







