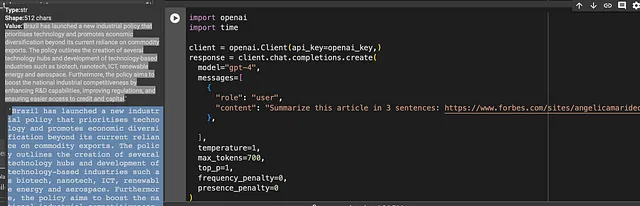
浏览器爬取:我应该使用ChatGPT还是在Browserless.io上构建一个爬虫?
探索每日新闻摘要、股市新闻监测和学术研究的最佳总结和提取技术。
中世纪:B4 OpenAI 浏览器插件
在将OpenAI的浏览器插件整合到ChatGPT之前,传统的网页抓取,比如使用Browserless.io这样的服务,需要更多的技术和实践方法。这种方法需要对编程有很好的理解、对网页技术有熟悉,通常还需要花费大量的时间来进行设置和维护。

工作原理
在传统的网页抓取中,使用像Browserless.io这样的工具,通常需要从编写自定义脚本开始。这些脚本通常使用Python或JavaScript等编程语言编写,它们会指示浏览器如何浏览网页、选择特定数据、处理各种网页元素,如表单、弹出窗口和AJAX请求。这种方法不仅需要编码技能,还需要对HTML、CSS选择器和可能的JavaScript有深入的理解,以有效地与网页的文档对象模型(DOM)进行交互。
此外,使用Browserless.io或类似工具管理网络爬虫项目涉及处理JavaScript加载的动态内容、管理需要登录的网站的cookie和会话,并实施避免被网站阻止的技术。这可能包括轮换IP地址、管理请求头,遵守网站的robots.txt文件等。
新学校
让我们从简单到复杂,来探讨三个具体的使用案例,并分析使用其中任何一个的优点和缺点。
ChatGPT与浏览插件或Browserless.io适用于每个场景。
每日新闻摘要(使用案例1)
你想从特定新闻网站创建每日新闻摘要。

ChatGPT带浏览插件:
优势:易于设置和使用;您可以直接要求模型概括该网站的头条新闻。
集成自然语言处理,可用于创建易于阅读的摘要。
缺点:仅限于浏览模型能够访问和解释任务的范围。
如果网站布局复杂或经常更改,则可能无法始终准确识别“头条”新闻。
Browserless.io 网页浏览器
优势:可以编程导航网站,根据特定的标准(如最多浏览次数,最高评级等)识别头条新闻,并提取精确信息。
更可靠的日常自动化任务,具有特定要求。
缺点:需要更多的技术设置,包括编写网页抓取流程的脚本。
您将需要额外的工具或脚本来处理和总结提取的数据。
监控特定公司的股市新闻(用例2)
您希望监控多个金融新闻网站,以获取关于特定公司最新文章并实时获取提醒。

ChatGPT with Browsing Plugin 具备浏览插件的ChatGPT
优点:快速询问特定公司的更新情况。能够提供易于理解的摘要,对于快速获取见解非常有用。
不足之处:可能无法提供实时监控和警报。在同时处理多个来源或应用复杂过滤器方面有限。
无浏览器.io
优点:可以设置为连续监控多个网站并实时提取信息。
高度可定制,以便针对特定公司,甚至具有复杂的标准。
缺点: 需要精密的编程来处理实时数据提取和警报。
资源消耗较大,可能导致更高的成本。
学术研究 — 从多个来源提取数据(用例 3)
您正在进行学术研究,需要从各种学术期刊、论坛和数据库收集数据,其中一些可能具有复杂的导航或需要登录凭据。
ChatGPT与浏览插件
优点:可快速从公开可访问的网页上提取信息。
可以帮助以简单的方式总结研究论文或讨论。
缺点:可能无法访问付费墙或登录要求后面的内容。
对于复杂学术数据库或专业搜索查询的导航能力有限。
无浏览器.io
优势:能够高效地浏览复杂网站,处理登录操作,以及从多种格式中提取数据。
可以自动化多个来源的重复任务,对于广泛的研究项目非常重要。
缺点:需要进行重要设置,包括处理身份验证和遵守网站条款和学术诚信的维护。可能更昂贵,尤其是当访问大量资源时。
结论

为了简便和快速摘要
ChatGPT与浏览插件结合非常出色。它易于使用,并结合了AI驱动的摘要功能,非常适合进行简单的任务,如每日新闻摘要或快速股票更新。
对于复杂且个性化的任务
Browserless.io在需要详细定制的网络交互方面表现出色,比如学术研究或跨多个站点的实时监控。它提供精确性和控制,但需要更多的技术专长和设置。
更多见解,关注我们。
领英:https://www.linkedin.com/in/vlad-shostak-mba/
软件代理公司:https://novastone.ai/