Word2Vec:像ChatGPT这样的现代NLP的基石
介绍
在不断发展的自然语言处理(NLP)领域中,词向量(Word2Vec)作为一个革命性的概念脱颖而出,是塑造我们在人工智能中处理语言方式的重要基石。本文旨在揭示词向量的复杂性,解释其重要性,并提供直观的类比和代码示例来加深您的理解。
Word2Vec的诞生
Word2Vec,由谷歌的一支由Tomas Mikolov带领的研究团队开发,改变了机器对人类语言的理解方式。它不仅仅是一个技术里程碑;它是使机器能够解释我们话语的细微差别的桥梁。
一个直观的类比
在想象一个热闹的市场,每个摊位代表着不同的单词。这些摊位彼此的亲近程度取决于这些单词在一起使用的频率。例如,“黄油”和“面包”可能是邻居,而“黄油”和“自行车”则处于市场的两端。Word2Vec本质上就是这个市场的地图。
核心概念
Word2Vec封装了两个模型:连续词袋模型(CBOW)和Skip-Gram模型。CBOW根据上下文词预测目标词,而Skip-Gram则相反。可以将CBOW比作根据周围的拼图块猜测缺失的一块,而将Skip-Gram比作当给出中心块时找到周围拼图块。
代码示例:实现Word2Vec
import gensim
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# Sample sentences
sentences = [['this', 'is', 'a', 'sample', 'sentence'],
['word2vec', 'model', 'example'],
['another', 'sentence'],
['one', 'more', 'sentence']]
# Training the Word2Vec model
model = Word2Vec(sentences, min_count=1)
# Summarize the loaded model
print(model)
# Access vector for one word
print(model.wv['sample'])
# Save model
model.save('model.bin')
# Load model
new_model = Word2Vec.load('model.bin')
这段代码片段提供了使用Python中的gensim训练Word2Vec模型的基本示例。
可视化词嵌入
Word2Vec最令人兴奋的一点之一就是其能够可视化单词之间的关系。通过通过主成分分析(PCA)降低单词向量的维度,我们可以在一个二维空间中绘制这些单词。
!pip install gensim
import gensim
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# Sample sentences
sentences = [['this', 'is', 'Dr', 'Ernesto', 'Lee'],
['Madison', 'born', 'December'],
['Caesar', 'January'],
['Jordan', 'in', 'October']]
# Training the Word2Vec model
model = Word2Vec(sentences, min_count=1)
# Summarize the loaded model
print(model)
# Access vector for one word
print(model.wv['Lee'])
# Save model
model.save('model.bin')
# Load model
new_model = Word2Vec.load('model.bin')
# Extracting the word vectors
word_vectors = model.wv
words = list(word_vectors.index_to_key)
# Reducing dimensions to 2D using PCA
X = word_vectors[words]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
# Creating a scatter plot of the projection
pyplot.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()
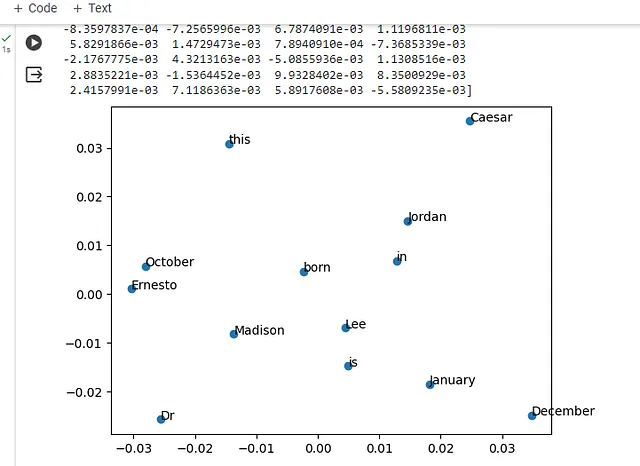
Word2Vec就像一个智能程序,它通过学习与其他词语频繁共现的方式来将词语在想象空间中进行映射。它类似于绘制词语的社交圈子;例如,“king”(国王)可能与“queen”(皇后)相近,因为它们经常出现在故事和对话中。
现在,看着你分享的图像,就像我们在看一个学校的快照,每个单词就像是在操场上闲逛的学生。在类似语境中使用的单词,比如"一月"和"十二月",它们靠得更近,因为它们都是月份,它们在对话中分享着相似的"话题"或"朋友"。另一方面,"凯撒"与"一月"和"十二月"稍微有些距离,这表明它在不同的语境中使用(比如关于古罗马历史或文学的)并且在单词世界中与月份不太"一起出现"。Word2Vec可以帮助我们以视觉方式看到这些关系,就像我们可以根据他们的共同兴趣看到哪些孩子在操场上不同的地方聚集在一起一样。
Word2Vec的重要性和价值
Word2Vec奠定了自然语言处理领域随后突破的基础,包括ChatGPT等复杂模型的开发。毫不夸张地说,如果没有Word2Vec,我们今天所互动的先进对话型人工智能也不可能存在。
为什么它重要
- 理解上下文和含义:Word2Vec对于捕捉单词的上下文和语义含义的能力是机器理解人类语言的基础。
- 效率和可扩展性:这是一个高效的模型,可以处理大规模的数据集,使其适用于现实世界的应用。
- 灵活性:Word2Vec的嵌入已经被用于各种应用,从情感分析到语言翻译。
结论
Word2Vec 不仅仅是一个算法;它是自然语言处理领域的范式转变。通过将单词映射到一个高维空间中,保留它们之间的语义关系,Word2Vec为理解和生成人类语言的高级人工智能模型铺平了道路,具有卓越的准确性。
随着人工智能领域的不断发展,Word2Vec所带来的原则和洞见无疑将继续成为我们旅程中至关重要的一部分,提醒着我们理解语言对于缩小人工智能与人类之间的鸿沟所产生的深远影响。