[第1部分] ChatGPT是如何工作的?—揭示Transformer架构
如果您偶然发现了这个页面,那么很有可能您已经听说过围绕OpenAI所创建的革命性语言模型ChatGPT所产生的轰动。现在,您可能会好奇,这种人工智能的魔法到底是如何运作的呢?好了,系好安全带,因为我已经踏上了深入理解Transformer模型内部奥秘的旅程,并打造了一种新颖的方法来增强它们的性能。毫不拖延,让我以一种快速易懂的方式揭示这个突破性的模型构架的内部运作机制。
架构概览
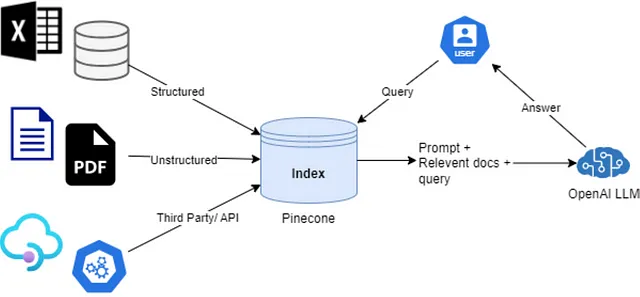
正如您可能已经猜到的那样,ChatGPT主要是一个变换器模型。GPT是“生成式预训练变换器”的缩写,该架构于2017年由Google的研究人员在论文《Attention is all you need》中提出。这是一项具有开创性意义的发明,主要由两个部分组成——编码器和解码器,如下图所示:
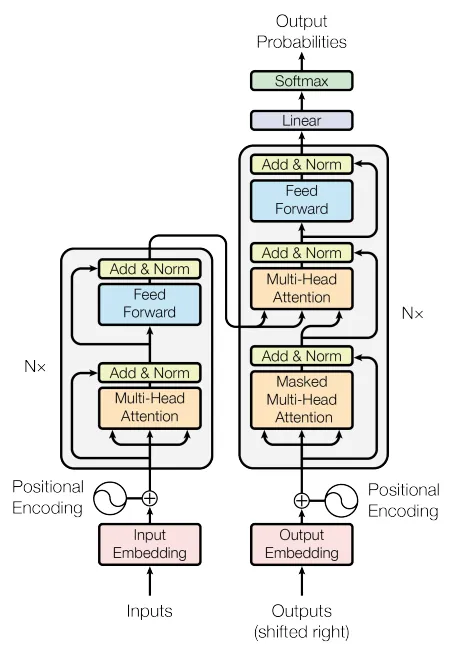
两个灰色区块分别是编码器(左侧)和解码器(右侧),它们具有各自的内部机制。两个区块都由多层组成,在图中用Nx表示。正如您所见,编码器和解码器层非常相似,但解码器还有一个额外的注意力区块,从编码器获取输入。这对模型的功能至关重要,因为它使我们能够对文本到图像、语言翻译、文本到语音和其他多领域任务进行建模。
为了简单起见,在本教程中,我们将专注于语言翻译作为目标任务。考虑到这一点,信息的流动如下所示:
源语言句子
源语句经过输入嵌入块。生成的嵌入向量通过编码器层流动。每一层都会对更多信息进行处理,以使输出的预测尽可能准确。最后,编码器的输出被馈送到解码器的每层,并参与解码流程。这个输出称为上下文向量,其中包含输入句子中最重要信息的抽象表示。
目标语言句子
目标语言句子通过输出嵌入块进行处理。解码器层中的计算与编码器中的计算类似。每个层中还有一个额外的步骤,在此步骤中,编码器中的上下文向量与流经解码器的提取数据合并在一起。此时,模型使用源句子提取的上下文来影响目标句子的输出。
此时,对于您来说,这个描述听起来可能很抽象,并且在某种程度上会让人感到困惑,但不要试图在没有进一步细节的情况下理解整个概念。在这里至关重要的是理解信息在架构中的流动方式。还需要提到的是,如果模型正在进行训练或用于推理,输入数据的输入数据会发生变化。
整體而言,Transformer 模型是一種編碼器解碼器的架構。編碼器將輸入數據編碼為抽象表示,解碼器則使用這些表示生成新的數據。
建筑模块
正如之前提到的,编码器和解码器块中的构建模块是相同的。在这里,我们将剖析架构并单独讨论每个构建模块。
嵌入
所有的机器学习模型都基于数学信息,然而,在语言翻译任务中,我们面临的是句子作为输入数据。为了在数学领域中进行语言转换,单词必须被转化为数字。这是通过嵌入块的帮助来实现的。嵌入表示将文本句子作为一个多维向量,其中上下文由每个单词向量在这个多维空间中的位置来捕获。
一个非常简单的例子来展示嵌入的概念如下:我们来考虑单词猫、蜥蜴和人。此外,我们采用一个非常简单的二维单词嵌入模型,具有以下特性:
- 第一个轴表示单词听起来有多“动物”
- 第二个轴是单词“哺乳动物”听起来的表示方式。
我们的模型将输出类似以下的词向量:
- 猫 [1, 1]
- 蜥蜴 [1, 0]
- 人类 [0, 1]
如您所见,使用向量的组成部分来捕捉词的上下文有些许的可能,因为我们了解每个维度的语义意义。现在,如果您想像一个多维向量,您可以更全面地捕捉到有关单词的更多复杂信息。
有不同的方法可以从单词中提取嵌入,例如CBOW、Skip-Gram、GloVe和Word2Vec,我建议你去了解一下,以便更好地理解。幸运的是,在Transformer架构中,单词嵌入是隐式学习的。
位置编码
在句子中,单词的语义关系可能根据它们的位置而有所不同。一个简单的示例就是句子“狗追逐猫。”与句子“猫追逐狗。”传达的信息不同。
位置编码提供了关于序列中单词的顺序或位置的信息。在变形金刚中,模型以并行方式处理输入序列,而不考虑元素的顺序。然而,正如我们从示例中看到的那样,在涉及自然语言的任务中,序列中元素的顺序往往携带着重要的信息。
位置编码将位置信息添加到输入嵌入中,帮助模型更好地捕捉数据内部的连续关系和依赖关系。考虑到我们将词表示为多维向量,我们可以添加预定义的位置编码向量,将位置信息整合到我们的嵌入向量中。计算这样的位置向量可以使用论文《注意力机制全凭自我》中的以下公式实现。
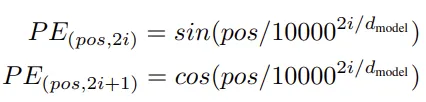
在这里,我们可以看到,根据我们预期输入句子的最大长度,我们可以预先计算位置向量。这些向量也取决于一个叫作d_model的变量,它是我们嵌入的维度。最后,变量i对应于计算当前PE值的维度。借助给定的公式,我们可以计算每个句子位置向量的每个组成部分。括号中的索引对应于向量的组成部分。
让我们预先计算一个嵌入尺寸为d_model=512的模型的512个位置的所有向量。
import torch
import math
def positional_encoding(max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
return pe
pe = positional_encoding(512, 512)
这样可以得到一个512乘以512的PE矩阵,我们可以将其作为热图绘制出来以可视化这些向量。
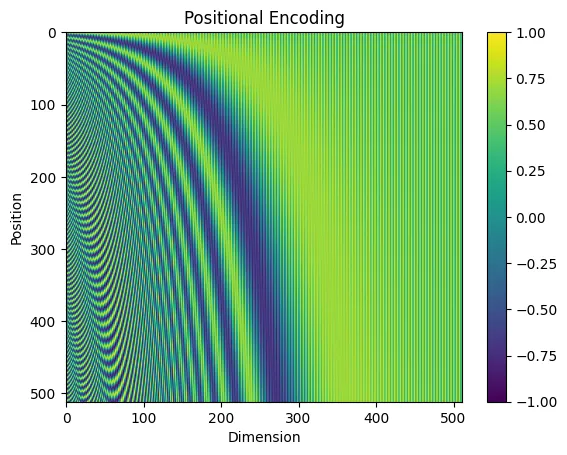
考虑将这个热力图的行视为独立的位置向量。我们可以得出结论,每个向量都略有不同于其他向量,并且可以用来编码位置。
注意力机制
机制的注意力增强了神经网络,使其能够专注于输入数据的特定部分。
它根据与给定背景相关性,为输入元素分配不同的权重,以改善模型在涉及顺序或变长数据的任务中的性能。该机制包括为每个输入生成注意力分数,计算加权和,并将结果用作后续层的上下文向量。它在自然语言处理等应用中被证明是有效的,尤其是在Transformer等模型中。
从Transformer架构图中,我们可以看到编码器和解码器层都包含注意力块,称为多头注意力(MHA)。块中的每个“头”负责从嵌入(将嵌入视为文本句子)中“关注”不同的内容。每个头执行的计算都遵循相同的数学概念。这个概念称为“缩放点积注意力”,在原始论文中用以下公式表示:
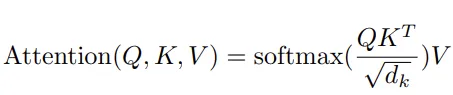
在数学抽象中,Q、K、V是矩阵,分别代表查询(Query)、键(Keys)和数值(Values)。这些矩阵是通过连接句子中每个单词的嵌入向量而创建的。目前,考虑到这些矩阵包含完全相同的数据并且具有完全相同的维度。但在编码器和解码器中实现MHA时存在差异,我们将在后面详细讨论。
让我们逐步通过计算缩放点积注意力来理解它的工作原理。
- 多个查询向量和转置关键字矩阵之间的点积计算将得到一个与之前维度相同的矩阵。考虑到创建查询和关键字的向量具有语义含义,点积将指示哪些元素彼此之间存在更高的关联性或重要性。
- 将点积除以常数d_k的平方(这个常数即为Keys矩阵的维数)作为一个标量,在模型训练过程中用于数值稳定性。
- 将Softmax应用于计算矩阵可以将内部的值转化为概率分布。通过这种方式,生成的矩阵传达了关于各个组成部分重要性的信息。
- 将重要性矩阵与数值矩阵相乘,可以对其中的组成部分进行缩放,并得到一个最终矩阵,该矩阵传递了关注的特定上下文的信息。
迄今为止,如何准确解释每个注意力头的输出仍然不为人知。研究表明,不同的头部关注不同的事物(通常是多个事物),但没有明确而具体的解释。将注意机制视为在谈论一个句子的上下文时确定哪个词更重要的数学方式。说到这一点,现在让我们实现缩放点积注意力:
import math
import torch
from torch import nn
def scaled_dot_product_attention(query, key, value, mask=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# This will come in handy when training the model
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
# (batch size, head count, tokens (should be padded to max_len) , d_model/h)
return torch.matmul(p_attn, value), p_attn
多头注意力
“注意力就是一切”的论文建议将从输入句子得到的嵌入矩阵分解为多个较小的矩阵,以便注意力头可以同时关注输入序列的不同部分。通常,分割是沿着最后一个维度进行的,该维度对应于输入的特征或通道。计算完成后,所有头部的输出将再次连接起来生成具有原始尺寸的输出矩阵。
这在下图中可视化,取自原始论文。
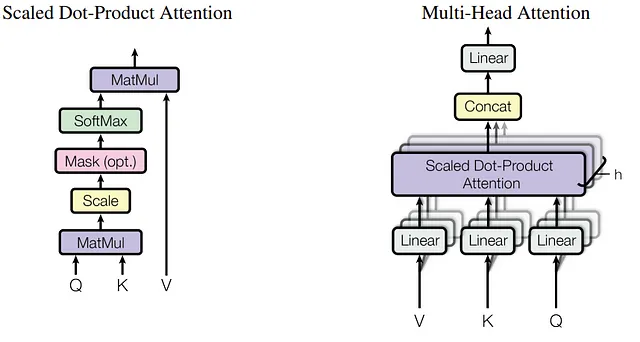
让我们将这部分实现为一个类,以便以后可以将其作为代码块重用。在这里,我们将使用torch.nn.Module作为基类来继承模型训练的功能。
from torch import nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads, dropout_p):
assert d_model % n_heads == 0
self.head_dim = d_model // n_heads
self.n_heads = n_heads
self.weights_q = nn.Linear(d_model, d_model)
self.weights_k = nn.Linear(d_model, d_model)
self.weights_v = nn.Linear(d_model, d_model)
self.weights_out = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
layer(data).view(nbatches, -1, self.n_heads, self.head_dim).transpose(1, 2)
for layer, data in zip((self.weights_q, self.weights_k, self.weights_v), (query, key, value))
]
# Apply attention on all the projected vectors in batch.
x, attn = scaled_dot_product_attention(
query, key, value, mask=mask
)
# "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.n_heads * self.head_dim)
)
return self.weights_out(x)
正如你所看到的,在这里我们介绍了MHA图中的查询、键、值和输出线性层的模型权重,保持了HTML的结构。线性层作为可学习的投影,将输入转化为每个注意力头所在的不同子空间。通过添加可训练的参数,模型可以适应特定任务的模式,并从训练数据集中学习到最相关的表示。
前馈网络
整体Transformer架构图中最后一个可见的组件是前馈网络(FFN)。它由两个线性层组成,具有ReLU激活函数。第一层增加了数据的维度,第二层将数据恢复到其先前的大小。这个操作为模型添加了非线性,并允许捕捉数据中复杂的关系。
实施FFN很简单:
from torch import nn
import torch
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, d_ff):
super(FeedForwardNetwork, self).__init__()
self.fc_1 = nn.Linear(d_model, d_ff)
self.fc_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.fc_2(self.fc_1(x).relu())
参数d_ff负责增加维度。论文“Attention is all you need”建议选择一个大小为d_model的4倍的值。
第一部分结束
如果您已经达到这一点,那么您已经取得了令人印象深刻的进展。我真诚地感谢您对内容的参与,并建议您继续前进。您刚刚阅读的只是我们实施旅程的开始。对于接下来的部分,我们将深入研究如何构建整个Transformer模型以及在语言翻译任务上的训练过程,请继续保持激动。
像往常一样,如果您在旅途中有任何问题或建议,随时联系我们。我们非常欢迎您的意见。
领英:https://www.linkedin.com/in/penkow/
快乐编码! :)