颠覆语言模型:突破规模,以上下文预训练为智慧之本

引言
在ICLR 2024的聚焦会议上,介绍了在开发大型语言模型(LLM)方面的一个重要转变。核心信息很明确:仅仅增加LLM的大小并不足以改善文本生成的质量。相反,有一个迫切的需求,即这些模型在学习过程中变得更加智能,而不仅仅是变得更大。
纸质文件链接
在上下文训练中:新的焦点
提出了一种特殊的教学方式,称为“上下文预训练”。这就好像当你从相关的不同故事中学习一个主题,而不是随机事实。例如,如果你阅读了许多关于足球的故事,了解到在2022年之前世界杯奖金从未超过1000万美元,然后你了解到在2022年跃升至4200万美元,你会得到一个更清晰的画面。这与仅仅阅读关于巴黎的河流的随机事实,然后突然转到足球不同- 它们之间没有很好的联系。


目标是提高下一个令牌预测的准确性,这对生成高质量的文本至关重要。强调了考虑上下文的重要性,即使是在最近的五分钟内的对话中,它对生成文本的连贯性和相关性有重要影响。

当前LLM项目面临的挑战
然而,目前LLMs在理解和生成上下文相关文本方面存在一些限制。各种研究指出,增加标记数量(这是模型扩展的常见做法)并不一定意味着对文本的理解或生成能力的提升。这一发现强调了上下文在生成高质量、连贯文本方面的重要性。它实际上是关于信息如何连接的问题。
在上下文预训练方法学
在详细描述大型语言模型(LLMs)的特征时,标准的令牌预测方法因其复杂性而受到了审查,这是由于对大量令牌的广泛依赖造成的。本文强调下一个令牌预测的准确性并不能保证生成文本的连贯性。
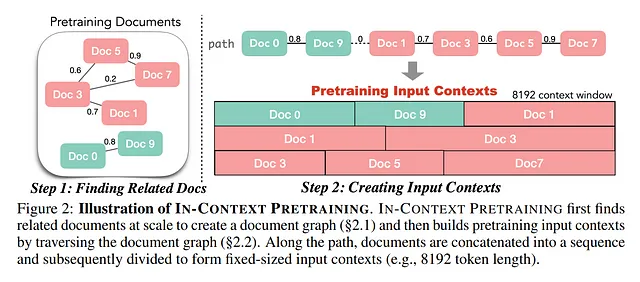
因此,引入了一种新的训练方法,称为上下文预训练(in-context pretraining)。这有助于模型更好地理解和创建更加连贯和合理的句子。
该技术利用扩展的上下文窗口和数据增强来预训练LLMs,从而增强模型训练过程中可用的上下文池。
它通过在所有标记上应用数据增强来简化广泛背景的整合过程,从而避免了解决复杂的NP难问题的需求。相反,它采用了一种简化的方法,类似于“最大旅行商”算法(贪心算法)应用于文档图中,其中通过迭代选择基于最小度和具有最大相似性的最近邻节点来构建路径,从而促进更高效的解决方案探索。此外,训练过程通过利用Contrivier模型将一般标记嵌入转化为对比嵌入来进化,这一转化对于改善模型在各种背景下区分标记的能力至关重要,从而显著增强了LLM的预测性能。
换句话说,该论文建议在预训练中使用贪婪算法进行路径优化,提出了一种策略性选择文档路径以最大程度地提高相关性和上下文连续性。通过设计一种用于在文档图中构建路径(P)的算法,可以实现有效的路径选择。该过程从选择具有最小度数的文档开始,并根据相似性度量逐步添加最近的邻居,最终创建出一条代表预训练阶段的文档精选序列的路径。
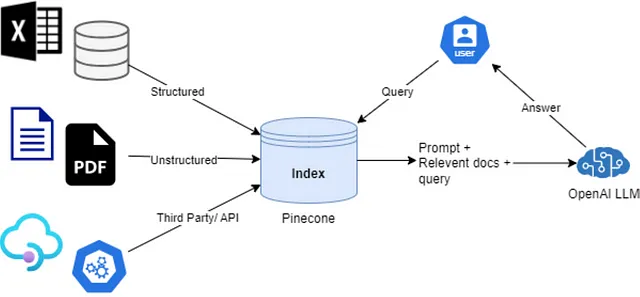
像添加不同类别的信息,比如链接到网站,这有助于他们更好地理解和回答问题。
数据增强和路径优化
这个转换过程结合数据增强,极大地丰富了模型运行的上下文。为了有效地检索相似的上下文,采用了一种使用FAISS的倒排文件系统(IVFPQ)的kNN方法,该方法能够处理30个邻居的k值。
k-最近邻居(kNN)算法主要用于语言模型尝试确定在一个句子中下一个应该出现的单词或短语时。如果模型能够参考之前学习到的类似例子,它将会非常有帮助。
通过检查这些相似的例子,模型可以获得关于在当前上下文中合适的词语或短语的线索。这个过程可以帮助模型进行更好的预测,并生成更连贯和上下文相关的文本。
提供了量化令牌集合的示例,显示了多样化的上下文窗口生成方法。该方法不仅局限于本地或最近使用的令牌,还将模型对各种上下文的接触范围进行了扩展。
该论文提供了有关文本上下文预训练对提高LLM性能潜力的全面概述。通过利用扩展的上下文数据、创新的预处理和数据增强技术,该方法旨在整合到现有的训练流程中,通过从更广泛和相关的上下文中学习,提高模型理解和生成文本的能力。这种方法通过整合到现有的训练框架中,可以显著提高LLM在复杂的语言理解任务中的性能。
性能改善和案例研究
也强调了在预训练中数据增强的重要性,其中的策略包括添加超链接及其相关文本,以提供更多样化和全面的训练数据集。这样的增强预计将增强模型在阅读理解和问题回答方面的能力,使其接触更广泛的上下文丰富信息。
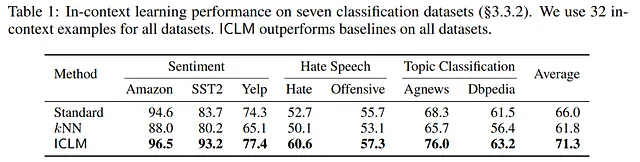
这些技术的实施是在从英文常见爬网数据源中获取的一个庞大数据集上进行演示的,该数据集包含2.35亿个文档。通过LLaMAO数据集的结果证明,通过上下文预训练能够显著提高自然语言理解任务的效果,包括阅读理解和问题回答等。
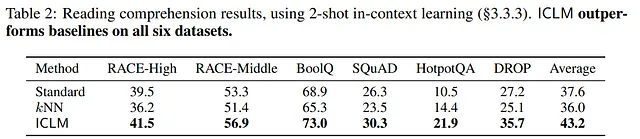
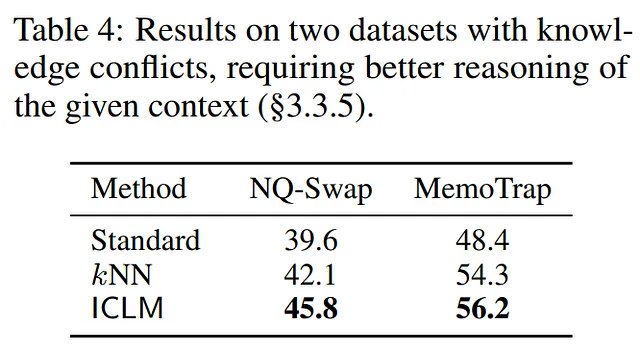
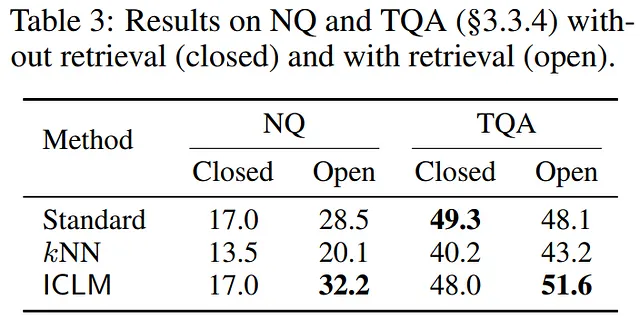
LLM扩展性与可持续性的实用性
讨论还涉及持续扩大LLM规模的可行性问题,考虑到日益复杂的需求和资源要求。该论文提出,仅仅扩大规模可能会出现边际收益递减的现象,而像上下文预训练这样的方法可能会为性能提升提供更高效的途径,避免不可持续的资源消耗增加。
会议强调了继续研究这些方法的必要性,着眼于计算效率和环境可持续性。在语境预训练方面提出的令人信服的结果表明,这种方法可能会在自然语言处理领域取得重大突破,推动LLMs在不需要不断扩展的情况下实现更大的成果。
环境和计算考虑
对计算资源的讨论涉及到kNN方法的高要求,需要大量地使用GPU,并将其与资源消耗较低的标准方法进行对比。这一方面突显了计算开销与上下文检索质量之间的权衡。
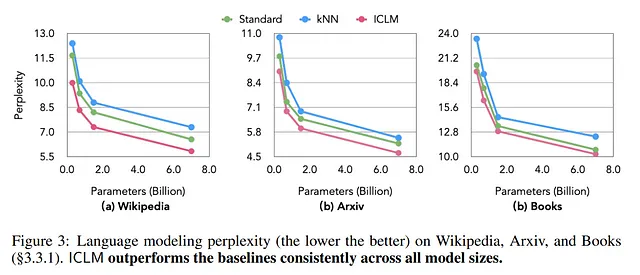
模型困惑度和训练效率
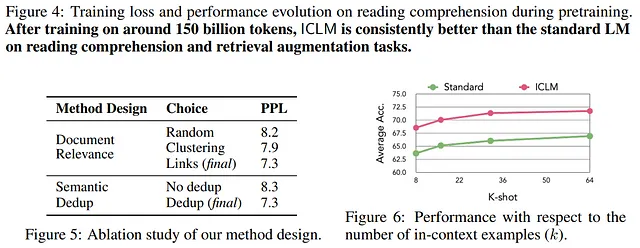
此外,本论文还讨论了通过去重来降低模型困惑度的方法。去重是一种通过细化训练语料库以减少冗余从而提高预测准确性的过程。在去重后,困惑度从8.3降低到7.3,这表明在语言预测任务中模型的效率提高了。
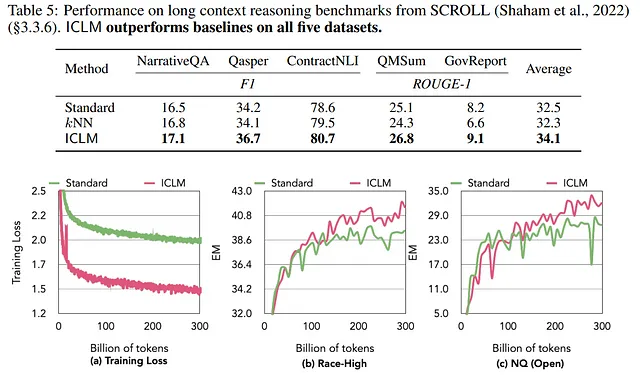
在评估所提出的方法学时,显示训练损失的图表表明ICLM方法随着时间的推移实现了更低的训练损失,表明学习更加有效。这些图形分析展示了上下文预训练方法在标准方法上的具体好处。
结论
本质上,ICLR 2024论文提出了一个令人信服的观点,即从扩展到通过创新的培训方法将LLMs智能化的焦点转移。这些方法优先考虑上下文和效率。通过更大的上下文窗口、数据增强和战略路径选择等技术,实现了在众多语言处理任务中提升LLMs性能的有希望的策略。