与您的数据交谈 | 入门指南
你是否希望根据你的数据集开发一个类似ChatGPT的聊天机器人?本文可以为你的潜在应用提供坚实的基础。与其他文章不同,我旨在保持简单。
这个跟随使用的主要工具有:
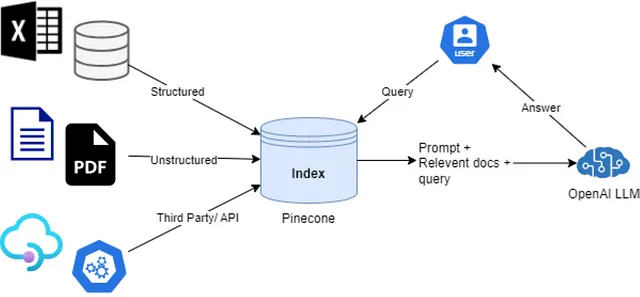
- Langchain:一款开源的LLMOps库,在RAG(检索增强生成)应用方面提供广泛支持,简单来说就是利用您的数据集实现与人工智能的问答。
- 松果:一个向量数据库,用于存储您的数据集,以便之后使用。
- OpenAI:我们将使用OpenAI的gpt-3.5-turbo模型API(ChatGPT背后的模型),虽然不是免费的,但在注册时提供了一些积分。
为什么我们需要这个的一个例子

虽然伟大的创始人盖茨和扎克伯格在2009年的论文中可惜没有涉及,但ChatGPT背后的语言模型的训练语料库中存在着其他信息,无论是明确还是隐含的。
让我们来构建一个可以从Paul Graham的文章数据集中回答问题的应用程序。
加载中
我正在使用这个数据集,并将使用LangChain从一个目录中加载数据,并在Google Colab上构建。
首先,我们安装依赖项。
!pip install langchain langchain-openai openai pinecone-client tiktoken unstructured -qU
# If not running on notebook.
pip install langchain langchain-openai openai pinecone-client tiktoken unstructured -qU
接下来,我们需要将文件或数据集上传到笔记本,并将它们加载到一个文件夹中。
import shutil
# Extracting essays from zip file to a folder
shutil.unpack_archive(
filename="/content/PaulGraham.zip",
extract_dir="/content/",
format="zip"
)
from langchain_community.document_loaders import DirectoryLoader
# Loading essay files using unstructured.io loader
essays = DirectoryLoader("/content/PaulGraham").load()
len(essays)
>>> 212
这是一个加载器将加载文件作为Document对象的方法。现在让我们来看看RAG/Chat-with-your-data应用的另一个常见方面。
# Average Length of essay files, or each Document object.
sum([len(essay.page_content) for essay in essays])//len(essays)
>>> 13631
# max Length of an essay file, or each Document object.
max([len(essay.page_content) for essay in essays])
>>> 74890
现在我们需要知道,像ChatGPT这样的LLM使用一种称为“令牌”的长度度量,并且对输入的令牌数量有限制。一个令牌大约等于4个字符,因此我们最长的文章可以有大约18,722个令牌,稍微超过OpenAI的模型gpt-3.5-turbo的限制。
所以我们将数据分成较小的块,并且最好不要给LLMs提供超过其需求的数据,因为这可能会使我们的机器学习模型产生困惑。
块化
from langchain.text_splitter import RecursiveCharacterTextSplitter
# To recursively separate firstly with paragraph,
# if there's no paragraph split it looks for a next line,
# if no line split exists, it looks for a space " "
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " "],
chunk_size=3500, # splits after every 3500 characters.
)
splitted_essays = text_splitter.split_documents(essays)
len(splitted_essays)
>>> 1060
这有效地将我们的文章数量从212篇分成了1060个块。下一步是将数据上传到我们的向量存储(Pinecone)。
索引和存储
当您通过Google或电子邮件注册Pinecone时,您可能需要输入一些与您使用它的计划相关的细节。之后,它将要求您选择基于Pod的索引或选择他们推荐的无服务器方案,但我建议选择基于Pod的方案,因为它有免费套餐,并且只要您进行测试,就不会产生任何费用。如果您希望转移到生产环境,可以根据需要切换到无服务器方案。
安装完成后,转到索引并创建一个索引。
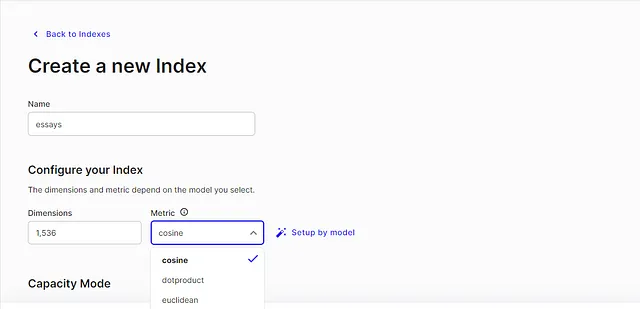
一些需要注意的事项,尺寸是指我们的嵌入模型生成的维度大小,并且我们将数据存储为数值嵌入。
嵌入是文本的数值表示,可用于衡量两段文本之间的相关性。嵌入对于搜索、聚类、推荐、异常检测和分类任务非常有用(OpenAI)。
根据需要,我们将使用OpenAI的文本嵌入ada-002模型。其次,我们选择的距离度量是余弦相似度,这是在搜索文档时的更好度量标准。
选择索引的相似性度量时的一般思路:使用与训练嵌入模型相同的相似性度量。在这里阅读更多(Pinecone)。
然后您可以创建一个索引,并且从导航中转到 API 密钥处并复制该 API 密钥,我们将使用它来上传数据到我们的索引。此外,您还可以获取您的 OpenAI API 密钥。

初始化松果
import pinecone
from langchain.vectorstores.pinecone import Pinecone
from langchain_openai.embeddings import OpenAIEmbeddings
# Loading our embedding model
embedding_model = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# Initializing pinecone client
pc = pinecone.Pinecone(
api_key=PINECONE_API_KEY, pool_threads=20
)
index = pc.Index("essays")
上传
from itertools import islice
from typing import Iterable, Iterator, List, TypeVar
T = TypeVar("T")
def batch_iterate(size: int, iterable: Iterable[T]) -> Iterator[List[T]]:
"""Utility batching function."""
it = iter(iterable)
while True:
chunk = list(islice(it, size))
if not chunk:
return
yield chunk
embedding_chunk_size = 1500
batch_size = 70 # size of batch (length of chunks in one go.)
texts = [chunk.page_content for chunk in splitted_essays]
metadata_list = [chunk.metadata for chunk in splitted_essays]
ids = [str(i) for i in range(len(texts))]
for metadata, text in zip(metadata_list, texts):
metadata["text"] = text
for i in range(0, len(texts), embedding_chunk_size):
chunk_texts = texts[i : i + embedding_chunk_size]
chunk_ids = ids[i : i + embedding_chunk_size]
chunk_metadatas = metadata_list[i : i + embedding_chunk_size]
embeddings = embedding_model.embed_documents(chunk_texts)
# uploading asynchronously
async_res = [
index.upsert(
vectors=batch,
async_req=True,
)
for batch in batch_iterate(
batch_size, zip(chunk_ids, embeddings, chunk_metadatas)
)
]
[res.get() for res in async_res]
最后,我们设置了我们的聊天机器人查询功能。
查询
def query_pinecone(query: str, top_k: int = 4) -> dict:
"""
Query the Pinecone index with the given parameters.
Parameters:
query: The query string to be embedded and searched.
top_k: The number of top results to return.
:return: The query responses from Pinecone.
"""
embedded = embedding_model.embed_query(query)
try:
# Query the Pinecone index
responses = index.query(
vector=embedded,
top_k=top_k,
include_metadata=True,
)
except Exception as e:
# Handle query errors
print(f"Error during Pinecone query: {e}")
return {}
return "\n\n".join([text.metadata["text"] for text in responses["matches"]])
提示模板
from langchain.prompts import PromptTemplate
# Setting up prompt template which
RETRIEVAL_TEMPLATE = """Given content from Paul grahams essays, answer the question accordingly, \
if you cannot answer using the information below just say "I don't know".
{summaries}
Question: {question}
Helpful Answer:"""
RETRIEVAL_PROMPT = PromptTemplate(
template=RETRIEVAL_TEMPLATE, input_variables=["summaries", "question"]
)
LLM链至问题/答案
from langchain_community.chat_models import ChatOpenAI
from langchain.chains.summarize import LLMChain
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
openai_api_key=OPENAI_API_KEY,
)
chain = LLMChain(llm=llm, prompt=RETRIEVAL_PROMPT, verbose=False)
现在我们拥有它。

希望你觉得这个很有用,我计划要在这个即时通讯和数据/状态预警应用上制作一个系列视频,如果你不想使用第三方模型,你可以部署自己的模型,比如LLama2,这里有一个跟随进行的指南。
欢迎在评论区提问或报告你在此过程中遇到的任何错误。
同时,我和我的团队还整理了一些现代人工智能和关系图谱中最先进的功能,以满足特定领域和复杂应用的需求。
需要進一步優化您的LLM應用程序性能,並獲得頂尖LLM專家的支持?還是從頭開始?
在LinkedIn上与我联系
或者设置一个一对一的电话