在1分钟内使用您自己的数据训练ChatGPT。
在这篇文章中,我们将学习如何使用一个名为embedchain的开源框架来在您自己的数据上聊天与ChatGPT。
介绍
我们大家都一定知道并且在某个时间点或另一个时间点都使用过ChatGPT。ChatGPT是来自OpenAI的一个非常擅长生成内容、回答问题、帮助学习新话题、写诗等等众多出色事物的LLM。
但是ChatGPT没有您的数据上下文。假设您问“约翰是否安排了本周的会议”,它将无法回答。
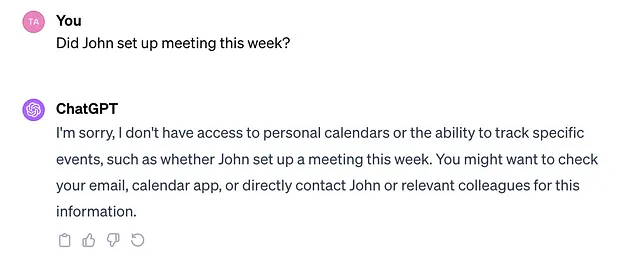
这是因为ChatGPT无法获得您自己数据的上下文。在这里,您的数据可以是访问所有电子邮件或日历应用程序。
所以如果我们想要解决这个问题,我们可以称其为“ChatGPT但适用于您自己的数据”或“与您自己的数据进行交流”。
与您自己的数据聊天的好处
当您与您的数据进行交流时,您也可以控制LLM免受幻觉的影响。这是因为LLM根据您的数据回答问题,而不是依靠其一般智能。为了验证这一点,您还可以要求该模型引用引文或参考资料,以便您验证答案是否合理。
使用自己的数据进行聊天的方法
有两种被广泛认知的方法来与你的数据进行聊天:
- 优化LLM
- 检索增强生成(RAG)
优化LLM是一个漫长的过程,因为它首先需要第一手数据来进行优化。此外,如果您的数据正在更新(比如新的电子邮件或日历事件),那么您将不得不持续或至少定期地对LLM进行优化。
另一方面,RAG是一个更合适的方法。RAG代表检索增强生成。这意味着在一个LLM生成答案之前,它会检索与查询相关的背景,并将其传递给LLM,并要求LLM在被固定的情况下进行回答,这样LLM就不会产生幻像,并只从您的数据中回答问题。
现在我们将实现RAG。我们将使用Python和一个名为embedchain的开源框架来创建一个RAG应用程序。
使用RAG实现与自己的数据进行聊天
在这个例子中,我们将创建一个应用程序,允许您与您的数据进行聊天。它由3个步骤组成:
- 安装必要的库(这里是embedchain)
- 创建应用程序并将数据集添加到其中
- 使用该应用程序
我们将把我的简历作为PDF文件使用OpenAI的LLM和嵌入模型进行交流。你可以选择其他数据类型,如Google文档、代码仓库,甚至是Slack频道。你还可以选择其他免费或付费的LLM。Embedchain支持多种选项。
首先,我们将安装 Embedchain 框架。
pip install embedchain
一旦安装了embedchain,我们将创建一个名为main.py的文件。我们将把所有的代码内容添加到这个文件中,完成后,我们将通过运行它来执行。
python main.py
由于我们正在使用OpenAI模型,因此我们需要将OPENAI_API_KEY设置为环境变量。你可以从这里获取你的OpenAI密钥。
如果你在shell上运行这个程序,你可以通过这样做
export OPENAI_API_KEY=sk-xxxx
如果你想在Python脚本中设置,你只需在main.py的开头添加以下代码即可。
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxx"
让我们开始往我们的 main.py 文件里添加代码。让我们先导入 App,并创建一个实例。我们可以通过以下代码实现。
from embedchain import App
app = App()
上述两行代码很简单且容易理解。我们只是引入了App类,并创建了一个名为app的实例,以便我们以后可以使用它。
现在让我们来处理PDF文件。我已经将PDF文件存储在下载文件夹中,它的名称是resume.pdf。因此其路径为/Users/taranjeet/Downloads/resume.pdf。但对于您来说,这可以是任何路径,甚至是一个URL。以下是一些虚拟示例:
- https://example.com/my-file.pdf(可通过链接获取的pdf文件)
- https://mywebsite.com (网页)
- /Users/user1/Downloads/my-data(您计算机上的整个文件夹)
- https://mywebsite.com/sitemap.xml(这将获取此网站地图中的所有网页)
所以现在让我们添加我们的PDF文件。
app.add("/Users/taranjeet/Downloads/resume.pdf")
这一行代码可以添加整个 PDF。当你运行这一行时,它会读取 PDF 文件的内容,然后以 AI 能理解的特定格式存储它。你可以添加多行类似的代码。Embedchain 框架支持多种数据类型。你可以在这里找到完整的列表。
现在的下一步是使用您自己的数据进行聊天。为此,您只需使用.chat端点。
app.chat("What is Taranjeet doing now?")
# Taranjeet is currently building embedchain.ai
是的,现在您可以使用这条线来与您的数据进行聊天。它可以自动保持和管理历史记录。
如果您想要一个连续的循环,在其中不断提问,您可以运行一个 while True 循环,或者循环直到用户输入 "exit"。您可以修改您的代码以实现此功能。
while True:
user_input = input("Ask something (type 'exit' to stop): ")
if user_input.lower() == 'exit':
print("Exiting.")
break
else:
print(f"Query: {user_input}")
answer = app.chat(user_input)
print(f"Answer: {answer}")
将整个 main.py 放在一起
from embedchain import App
app = App()
app.add("/Users/taranjeet/Downloads/resume.pdf")
while True:
user_input = input("Ask something (type 'exit' to stop): ")
if user_input.lower() == 'exit':
print("Exiting.")
break
else:
print(f"Query: {user_input}")
answer = app.chat(user_input)
print(f"Answer: {answer}")
这样你就可以与任何您拥有的数据进行聊天。
结论
在这篇文章中,我们学到了什么是使用自己的数据进行对话,以及有哪些不同的方式可以实现这一点。然后我们了解了 RAG,即检索增强生成。然后,我们使用 embedchain 框架创建了一个使用我的个人简历进行对话的示例。Embedchain 是一个开源的检索框架(在 GitHub 上有 7.2K 颗星),它允许任何人在自己的数据之上创建 ChatGPT 类似的体验。
我写关于LLMs,RAGs系统,并分享在构建embedchain时的经验教训。您可以在Twitter或LinkedIn上关注我以获取最新消息。








