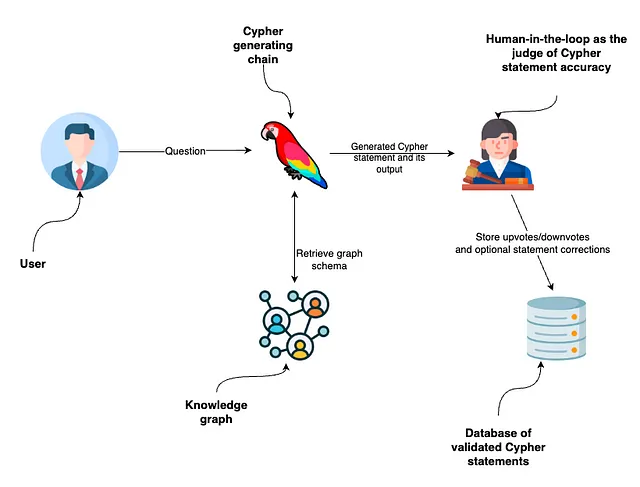
如何从您的关系数据库构建自定义GPT
使用Dataherald部署一个将自然语言转换为SQL的GPT模型。
OpenAI最近推出了GPT Store,这是一个允许开发者将他们自己定制版本的GPT发布到OpenAI商店的平台。到目前为止,已经创建了大约3百万个定制版GPT,每个版本具有独特的功能。虽然听起来可能令人生畏,但只要正确设置后端,制作定制版GPT的过程非常简单。
在本文中,我们将展示如何构建一个定制的GPT,它能够从结构化数据库中检索数据并回答问题。在这个例子中,我们将使用一个包含美国房地产数据的PostGres数据库,但是相同的方法可以用于任何关系型数据库。我们将使用OpenAI的定制GPT编辑器以及Dataherald AI,一个托管的自然语言转SQL的API。
先决条件
要使用OpenAI的编辑器开发自定义GPT,请确保您已经具备以下条件:
- 订阅了OpenAI的ChatGPT Plus计划。
- 具有访问Dataherald NL-to-SQL API和API密钥的权限
- 可以托管应用程序。对于本教程,我们选择了使用AWS Lambda的简单无服务器方法。如果您也想使用Lambda托管您的服务器,请查看这篇操作说明文章。
我们将使用Dataherald的Python SDK。有关使用Dataherald AI设置数据库的指导,请参考Dataherald AI入门指南。您还可以在此处找到完整的Dataherald文档。
从荷兰语翻译为SQL Server
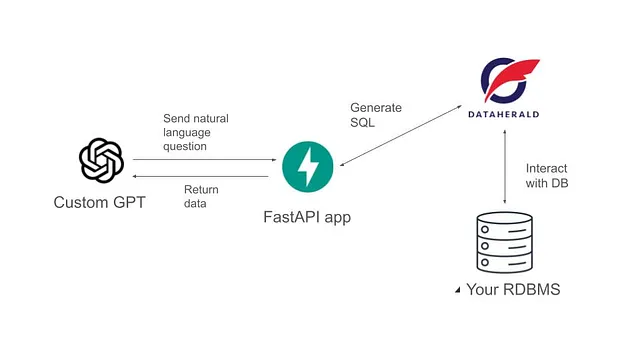
为了这个教程,我们将创建和部署一个FastAPI应用程序,该程序将实现一个单一的API端点。这个API端点将会:
- 从我们的GPT模型获取自然语言问题
- 与Dataherald引擎交互以生成必要的SQL
- 在数据库上执行并返回数据
下图显示了我们将要构建的应用程序的高层架构。
创建FastAPI应用程序
让我们创建一个简单的FastAPI应用程序,允许用户获取给定问题的结构化数据库中的查询结果。假设您已经完成了Dataherald AI组织和数据库连接的设置,您应该有以下环境变量:
DATAHERALD_API_KEY # your Dataherald AI API Key
DATABASE_CONNECTION_ID # database connection id on Dataherald AI
FINETUNING_ID # optional, but this really helps improve performance
首先,在Python上安装依赖项:
pip install fastapi
pip install dataherald
pip install mangum # optional, wrapper for AWS Lambda
pip install uvicorn
然后创建一个名为app.py的文件,你可以在我的公共库中找到所有的代码:
import os
from fastapi import FastAPI, HTTPException
from dataherald import AsyncDataherald
from dataherald.types import SqlGenerationResponse
from mangum import Mangum # optional
import uvicorn
API_KEY = os.environ.get("DATAHERALD_API_KEY")
database_connection_id = os.environ.get("DATABASE_CONNECTION_ID")
finetuning_id = os.environ.get("FINETUNING_ID")
app = FastAPI()
handler = Mangum(app) # optional
@app.get("/")
async def root():
return {"message": "Hello World"}
@app.post("/questions", status_code=201)
async def answer_question(text: str):
# use dataherald client
dh_client = AsyncDataherald(api_key=API_KEY)
try:
# get generated sql query
response: SqlGenerationResponse = await dh_client.sql_generations.create(
prompt={"text": text, "db_connection_id": database_connection_id},
finetuning_id=finetuning_id, # exclude finetuning_id if you don't have one
)
# execute query
sql_results = await dh_client.sql_generations.execute(response.id, max_rows=10)
return sql_results
except Exception as e:
print(e)
raise HTTPException(status_code=500, detail="Internal Server Error") from e
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8080)
这将创建一个端点/问题,该端点接收一个查询参数text,然后将其传递给Dataherald AI,返回答案的SQL结果。
为了测试服务器,请运行 python3 app.py。
在OpenAI上设置一个自定义的GPT
一旦我们拥有了托管的自然语言到SQL的服务器,就导航到OpenAI GPT编辑器并转至配置选项卡以构建您的自定义GPT。您需要订阅OpenAI的ChatGPT Plus计划以访问编辑器。
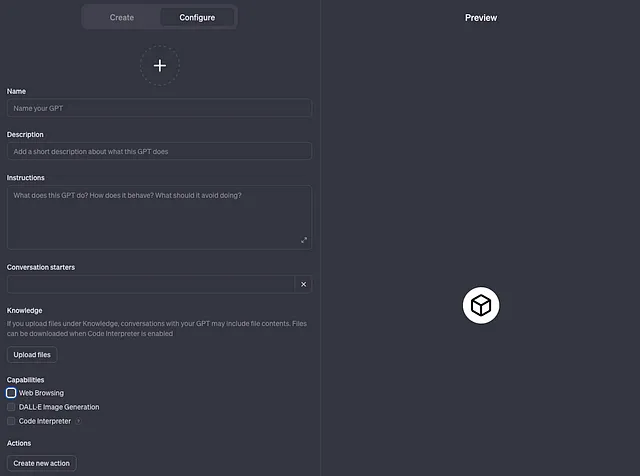
首先,输入您自定义GPT的名称和描述。然后,在“操作”下面点击“创建新操作”来添加查询NL-to-SQL服务器的操作。您可以导入您的OpenAPI Schema,或者使用OpenAI的示例Schema,并用包含适当细节的托管服务器的url替换它,就像这样:
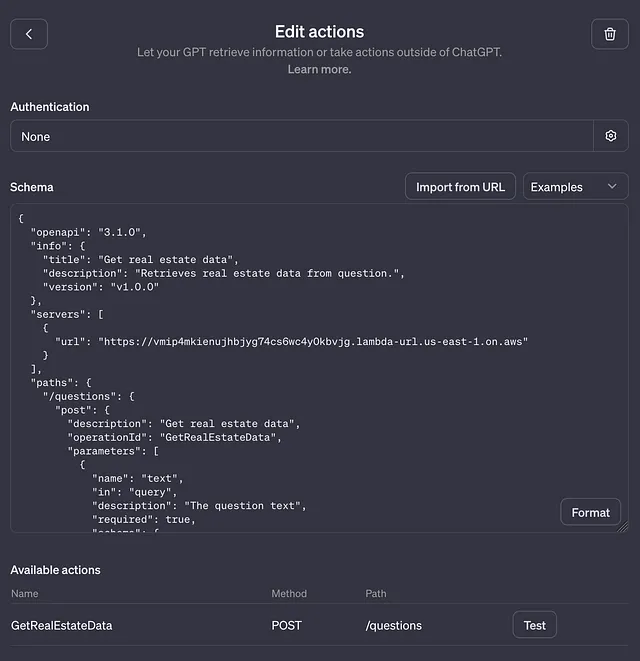
一旦模式完成,创建一个使用查询终端路径的动作。在指示中,我们将引用该动作的操作标识符。
现在我们可以回到配置标签页,让GPT知道当用户提问时使用这个动作。
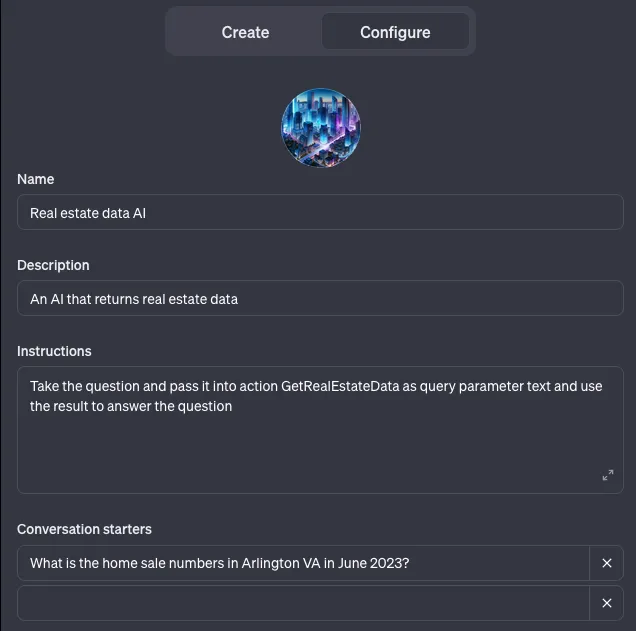
让我们在预览页面上测试我们定制的GPT。

这个功能可行!我们的GPT检测到这个问题与我们构建的自定义操作相关,并调用我们的API端点来检索数据以回答这个问题。你可以在这个教程中查看我们创建的自定义GPT。
现在让我们尝试一些更难的问题,这将需要更难的SQL :


改进自然语言到SQL的功能(可选)
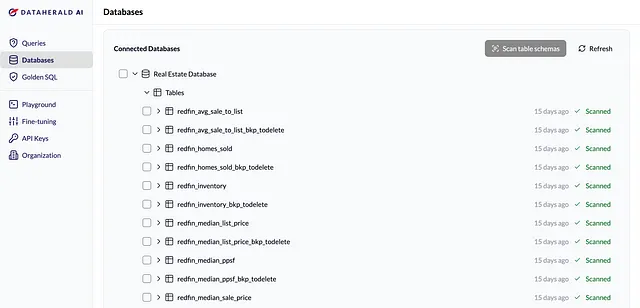
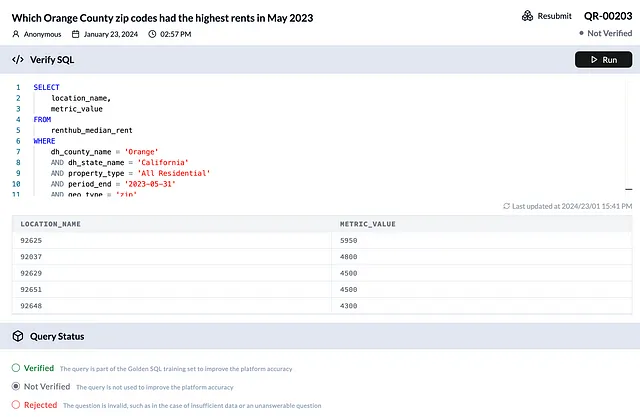
一旦你在自定义GPT上提出问题,你可以前往Dataherald AI控制台,自己查看生成的查询结果。为了提高你的自然语言到SQL的结果准确性,验证你的查询并使用它们来微调你在Dataherald AI中的LLM模型。
最后的想法
我们现在准备好推出和发布我们的GPT!我们只需要在您创建的动作中添加一个隐私政策网址,然后点击发布即可。在发布之前,请确保您的数据库不包含任何敏感数据,因为全世界都可以访问它。
要了解更多关于Dataherald AI的信息,请访问我们的网站,或者在Github上查看Dataherald AI的开源版本,或者加入我们的Discord,参与更多关于自然语言到SQL的讨论!