众包Text2Cypher数据集
为了评估和优化LLMs,贡献一个文本到Cypher数据集的开发。
使用大型语言模型(LLM)生成数据库查询在领域中变得非常受欢迎,并被视为尖端发展。尽管有几个Text2SQL数据集可用于促进此过程,但是在缺乏Text2Cypher数据集方面存在明显的差距。我的目标是通过启动一个众包计划来填补这个差距,以创建这样一个数据集。为此,我们开发了一个包含多个图形的应用程序,旨在使用人们参与生成和验证Cypher语句的方法来简化数据收集和集成过程。

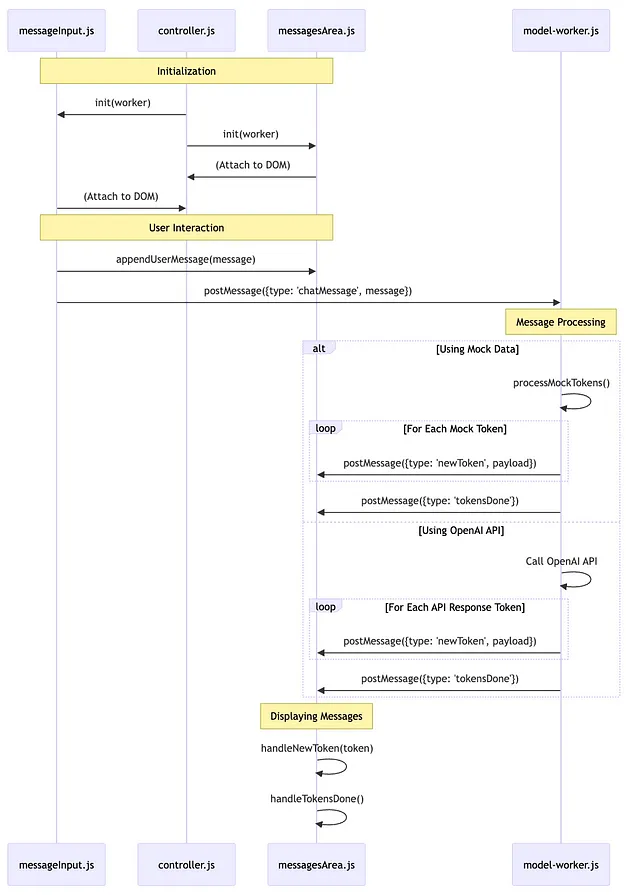
图像描述了一个人在循环系统中验证Cypher语句的工作流程图。我们从用户提问开始。问题经由一个生成Cypher语句的链进行处理,该链利用图模式信息生成一个对应的Cypher语句,用于从图中获取能回答用户问题的信息。生成的Cypher语句及其输出随后由一个人类(在循环中)进行评估,该人类充当准确性的评判者。这个人类可以将赞同、反对和对语句的可能更正存储在已验证的Cypher语句的数据库中。
由于这个过程是劳动密集型的,我们需要您的帮助来生成一个耗时的各种图表示例数据集。
应用程序在此处可用:https://text2cypher.vercel.app/
提供的数据库
该应用程序连接到Neo4j提供的演示服务器。有17个不同的数据库可供您使用以测试Cypher生成。
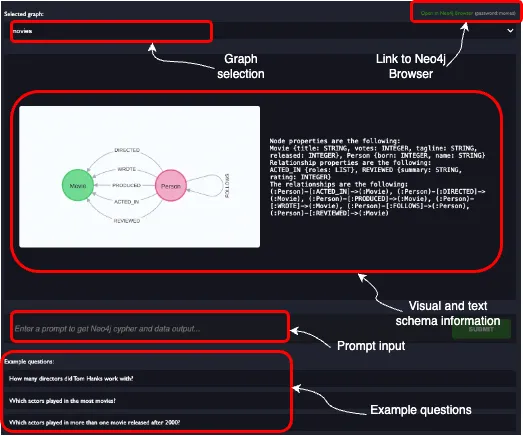
因此,要做出优质的贡献,熟悉图模式及其内容是至关重要的。我们还为每个数据库准备了三个示例问题。您可以使用Neo4j浏览器探索每个数据库。
每个数据库都有不同的用户名和密码。例如,如果您想查看“companies”图表,您必须使用“companies”作为用户名和密码。您还可以使用Neo4j驱动程序通过任何脚本语言连接到它。
URI: neo4j+s://demo.neo4jlabs.com
username: companies
password: companies
database: companies
同时建议检查数据库中关于你想询问的任何特定实体,以便在查询中使用准确有效的值。
贡献指南
本项目的主要目标是通过提出良好的问题并对其进行评估,为text2cypher应用程序生成高质量的训练和评估数据集。
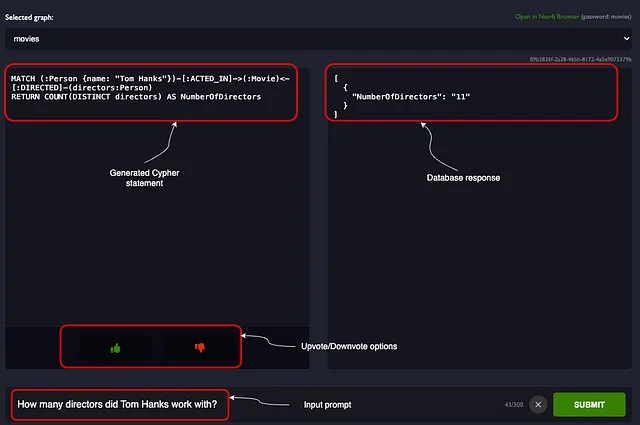
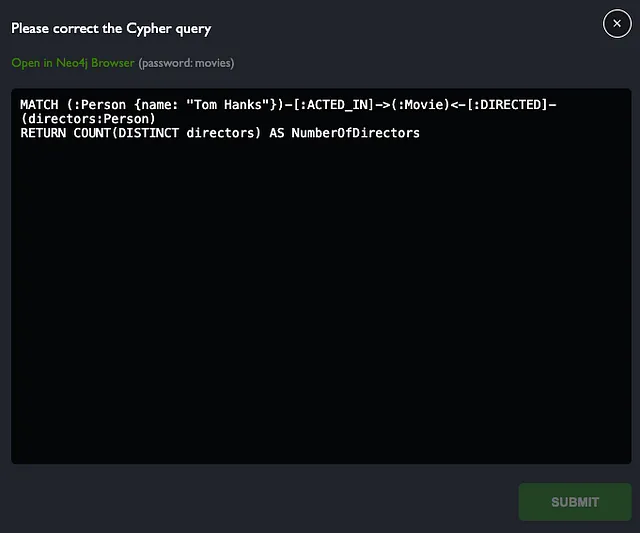
应用程序接收用户的自然语言查询,并将其转换为Cypher查询。一旦用户提交他们的问题 - 例如,查询汤姆·汉克斯(Tom Hanks)共与多少导演合作过 - 系统会将其转换为相应的Cypher查询。然后,该查询将被执行并返回以结构化格式显示汤姆·汉克斯(Tom Hanks)共与11位不同导演合作过的结果。界面提供了对生成的Cypher语句提供反馈的选项。如果选择了反对票,将打开一个模态框,提示您输入相应自然语言输入的有效Cypher语句。
为确保这一众包项目能取得最佳效果,以下准则必须予以充分考虑。
- 请不要提问与数据库无关的问题。LLM将尽其所能提供Cypher语句,但这将不会作为评估或微调示例而有用。
- 避免含糊不清的问题。尽量描述得更详细。例如:
- 如果您在数据库中提及特定的值或实体,请确保它们有效且准确,因为没有实施中间值映射步骤。例如:林平是香港公司的任职人员吗?
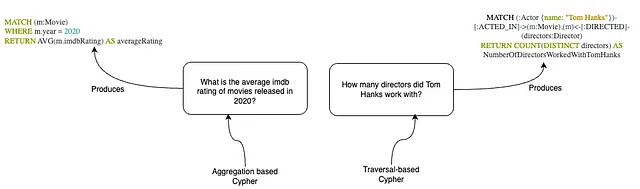
- 尝试使用更多以图为基础的问题,而不是简单的统计数据。两种方式都可以,然而,我们应该专注于基于图的遍历等。
- 尝试明确从数据库中想要检索的信息以及应有的数值数量。例如:返回具有最高IMDB评分的前3部电影标题!
- 请尝试使用各种数据库来生成和测试示例,不仅仅是电影库 :)

摘要
我真的很希望我们能够一起构建一个好的评估/训练的文本转Cypher数据集,因为我非常渴望尝试微调的LLM和架构描述等等。这个数据集将会公开分享。我暂时还不清楚具体细节,但我希望我们所有人都能从中受益,并且尽可能地不限制使用。此外,前十名贡献者将获得Neo4j Swag奖励!我计划运行这个应用程序一个月,然后我们可以重新评估。
敬祝文本2密码器LLMs调优之年!打开应用程序并帮助我们完成它!