什么是大型语言模型?(LLMs:从零到英雄)
一系列文章展示了我与大型语言模型的学习之旅。这是第一篇文章。
背景
在2023年11月,我偶然发现了OpenAI开发者会议的消息,这个事件让我为其在人工智能领域的突破性进展所折服。渴望更深入地探索这个引人入胜的领域,我报名参加了ChatGPT,并且没过多久,我就对大型语言模型(LLMs)背后的技术感到无比的动力与热情。
但是就像我们大多数人一样,从零开始学习LLM,很难知道从何处开始。
在经过数百小时的阅读和实验后,我整理出了一些最佳资源,以帮助我们入门。假设你只具备基本的编程和初中数学的理解,这个学习路径将引导你了解人工智能和机器学习的基础知识,然后帮助你构建自己的大规模语言模型。
模型定义
大型语言模型(LLM)如ChatGPT正在成为当今科技界的热门话题。根据维基百科的定义,LLM是:
一个大型语言模型(LLM)是一个以其能够实现通用语言理解和生成而著名的语言模型。LLM通过在计算密集型的自我监督和半监督训练过程中从文本文档中学习统计关系来获得这些能力。LLM是遵循变压器架构的人工神经网络。
换句话说
LLMs (语言模型) 是在庞大的文本数据集(如书籍、网站或用户生成的内容)上训练的。它们能够以自然的方式生成继续初始提示的新文本。
LLM模型基本上是一个具有大量参数的神经网络。粗略地说,参数越多,模型越好。因此,我们总是听说模型的大小,也就是参数的数量。例如,GPT-3具有1750亿个参数,而GPT-4可能拥有超过1万亿个参数。
但是一个模型究竟长什么样呢?

模型只是一个文件
一个语言模型只是一个二进制文件。
在上面的图像中,参数文件是Meta的Llama-2–70b模型,其大小为140GB,包含70亿个参数(以数字格式表示)。run.c文件是用于查询模型的推理程序。
训练这些超大模型非常昂贵。像GPT-3这样的模型训练成本高达数百万美元。

截至今天,最出色的模型GPT-4不再是单一模型,而是多个模型的混合体。每个模型都在特定领域进行训练或微调,并在推理过程中共同发挥最佳性能。
但是不要担心,我们的目标是了解和学习大型语言模型的基本原理。幸运的是,我们仍然可以在个人电脑上训练一个(参数较少的)模型。我们将在后续文章中一起深入探讨并逐步编码。
模型推理
当模型训练完毕且准备好后,用户通过问题查询该模型,将问题文本传入那个140GB文件,并逐个字符进行处理,然后返回最相关的文本作为结果输出。
按最相关的意思,这意味着模型将返回最有可能成为输入文本下一个字符的文本。
例如,
> Input: "I like to eat"
> Output: "apple"
由于模型训练所基于的大型数据集,"apple" 作为下一个字符的可能性最大,因为它在"I like to eat"之后出现。
记住我们之前提到的书籍和网站吗?根据我们提供的数据块,你可以这样思考:
我喜欢吃苹果是这个模型学习了多次的一个非常常见的句子。
我喜欢吃香蕉,这句话也很常见,但比上面那句话较少见。
在训练过程中,模型:
在我喜欢吃之后,记录了苹果出现的概率为0.375。
在我喜欢吃之后,记录了香蕉出现的概率为0.146。
...其他字符概率...
所以这些概率会导致概率集保存在参数模型文件中。(机器学习领域通常将概率称为权重。)
所以基本上,LLM模型是一个概率数据库,为任何给定的字符及其相关的上下文字符分配概率分布。
这在以前听起来是不可能的。但自从2017年发表了论文《注意力机制就是你所需要的》之后,变换器架构被引入,通过在非常大规模的数据集上训练神经网络,使得这种大规模上下文理解成为可能。
模型架构
在LLM出现之前,机器在神经网络上的训练确实局限于使用相对较小的数据集,并且在上下文理解方面具有极少的能力。这意味着早期模型无法以与人类相同的方式理解文本。
当论文首次发表时,其初衷是用于训练语言翻译目的的模型。然而,OpenAI团队发现变形金刚架构是字符预测的关键解决方案。一旦在整个互联网数据上进行训练,该模型有潜力理解任何文本的上下文,并像人类一样连贯地完成任何句子。
以下是一个展示模型训练过程内部发生情况的图示:
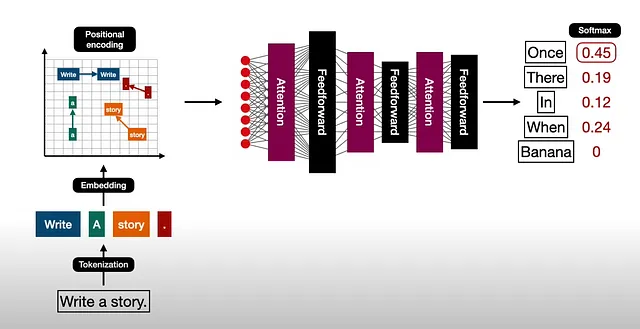
当然,在我们第一次看到它时,我们并不理解,但不用担心,在接下来的文章中我们很快就会解析它。
在我们深入讨论编程方面和数学细节之前,让我们来理解一下下一篇文章中模型的概念和运行过程。