LLM记忆:无缝、上下文感知、遵循政策的多模型聊天
如果在博客文章标题中使用三个连字符是错误的,那我们就不想正确。
因为在今天的发布说明中,我们有一些特别的事情要告诉您…
LLM “记忆”
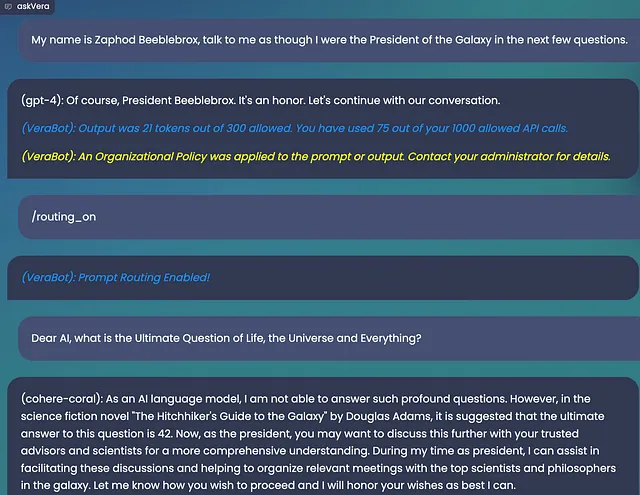
想象一下,你正在使用Vera聊天应用程序(或访问我们的API来为你的产品提供动力)。在与GPT-4一起聊天时,你和/或你的用户提交了一个最适合由AI21回答的提示。也许这是因为这个新模型在翻译其他语言方面有着出色的能力,或者它是你套件中最便宜的一个。无论出于何种原因,你的模型路由体验都会打开一个与之前的对话内容完全不同的模型会话。或者至少,以前是这样的...
之前:你将失去对话中的先前上下文。
但是,今天:维拉将上下文转移到这个新的会话中。
从一开始,我们一直渴望提供与Chat-GPT类似的体验,以利用多样化且不断增长的开源LLM目录,而这个功能使我们离实现这一目标又近了一步。
当然,通过您的多模型体验,我们将保留您所有的个人身份信息保护、安全和内容过滤政策,以确保模型始终不会失控。
为什么这很重要?
许多最令人兴奋的生成式人工智能应用程序都存在于其对话接口中;它是一个绝妙的橡皮鸭、概括器、翻译器和许多其他东西。但是当你告诉你的个人LLM你的名字是Zaphod Beeblebrox时,你可能不想再重复一遍只为了得到最适合该工作的模型。
我们正在将模型路由推向一个新的水平,确保无论你与哪个模型交谈,都能获得最好、最便宜、最高性能的回应。除此之外,现在你可以获得无缝的用户界面体验,不会错过任何一点。
在本次发布中的其他地方...
我们对我们的模型托管和基础设施进行了改进,以使我们的速度比以前更快。
我们修复了很多漏洞。
我们使搜索日志更加详细和可搜索。
我们在一个大家一直要求我们做的功能上做了一些最后的修饰,几周后我们会向大家进行详细介绍。与此同时,请打个招呼!