让我们弄清楚为什么ChatGPT变得懒惰了
你有没有注意到ChatGPT最近的性能变化?如果你是这个生成式人工智能工具的日常用户,你可能在过去几个月里观察到一些差异。这不仅仅是你的想象 - 最新模型GPT-4的表现出现了明显变化。虽然我们不太清楚原因,但社区似乎已经注意到了。我将向你解释最有可能的假设。
您听说过Hugging Face网站上的LMSYS Chatbot Arena排行榜吗?它就像一个显示AI模型排名的记分板,展示了哪些模型在领域中处于领先地位。
这个排行榜对用户和开发者来说都非常有用,因为它提供了哪些模型表现出色,哪些模型落后的指示。有趣的是,人们可能期望在排行榜上占据主导地位的新版本OpenAi或anthropic实际上排名低于它们的前辈。
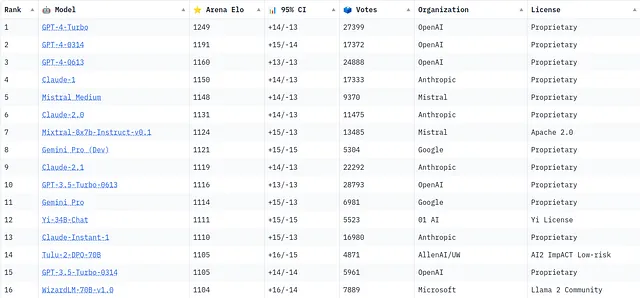
GPT-4 的更新版本并非位于顶部,这可能出人意料:
- GPT-4-Turbo — 发布日期:2023年4月 — Elo评分:1249
- GPT-4–0314 — 发布日期:2023年3月 — Elo:1191
- GPT-4–0613 — 发布日期:2023年6月 — Elo评分:1160
这与人类学模型相同。
- 克劳德-1 — Elo评分:1150
- 克劳德2.1 — 电竞等级:1131
- 克劳德2 — 赛季等级:1119
如果你想知道什么是Elo评分系统,那它是一种用于计算棋类等零和游戏中各玩家相对技能水平的方法。在这种系统中,玩家的评分会根据与其他玩家对局的结果增加或减少。
这意外的排名逆转表明最新的更新可能并非在每个方面都有所改进,并提出了一个关键性问题:为什么最新的不一定是最好的呢?
我希望最新版本是最强大的。然而,它们被评价的非按时间顺序排列并不反映出这一点。这表明新版本中的改进可能与用户所重视或期望的内容不一致。这可能是由于多种因素,包括模型训练数据的变化、算法的更新,或者其预期用途的转变。理解这些版本对于把握GPT-4的发展历程中的细微差别至关重要。
假設
以下所有内容都是基于ChatGPT的日常使用、对话和阅读的假设。正如您在上文中所见,这不仅仅是一种感觉。甚至OpenAI自己也谈到了这个问题。
如果您正在使用它来生成代码,这将令人惊叹。几周前,当我要求ChatGPT生成函数时,它生成了整个代码。我非常惊讶它能够生成如此长且复杂的内容。今天,如果我不要求它详细生成所有内容,90%的时间里,它不会生成整个代码,而是会添加注释,如“在此处理逻辑”,“执行与上述相同操作”或“实现”... 我在下面添加了最近得到的一个具体示例👇
// Implement this function based on how you store user IDs in your context
func getUserId(c *gin.Context) (uuid.UUID, bool) {
... [rest of your function code] ...
return uuid.UUID{}, false
}
我认为OpenAI是有意为之,为了降低推理的成本(推理是根据之前的所有内容预测下一个词生成文本的过程)。在之前的一篇文章中,我详细解释了ChatGPT的运行基础设施可能造成的巨大成本。最新估计大约是每天70万美元左右。
在简单的ChatGPT界面背后,是一个复杂的高性能计算资源架构,这也意味着巨大的成本。这些成本可能会对模型的设计和运行产生影响。为了管理开支,开发人员可能会选择对模型进行微小的更改,以稍微降低其响应速度或复杂性。
AI模型在保持高质量和确保高效性能之间存在微妙的平衡。像量化这样的技术有助于进行管理,但它们也有自己的权衡。量化是一种减少模型中数值精度的技术(因为在内部,一切都是用数字表示的)。通常情况下,LLM模型(例如GPT)使用浮点数,这需要大量的内存和计算能力。通过量化,这些值被转换为较低精度的格式,例如仅保留小数点后的某些位数,从而减小模型的大小、内存使用量和功耗,提高其效率,同时尽量减少性能损失。这类似于GPT的高级版本。举个简单的例子,可以将其比喻为图像压缩。通过使用 .jpg 格式,你拍摄的照片看起来几乎与原始照片相同,但在计算机上占用的空间更小,显示的速度更快。

最后,GPT-4在移动设备上与桌面设备上的行为不同。移动版本往往提供较短的回答,这可能是出于策略考虑,考虑到平台的性质。然而,这种差异凸显了用户体验如何根据设备而异。
在移动设备上,用户通常寻求快速和简明的答案,GPT-4的回答更短。这种适应可能会提升移动平台的用户体验,但也揭示了人工智能性能如何根据平台而显著变化。
结论
如果您对ChatGPT变得懒散有具体例子,请分享!另外,如果您有其他假设,请在评论中讨论!
谢谢阅读。如果你喜欢这篇文章,或者想鼓励我多写一些,请随意给个👏