LLM评价指标:一切您所需的LLM评价内容

尽管对大型语言模型(LLM)的输出进行评估对于希望发布稳健的LLM应用程序的任何人来说都是至关重要的,但LLM评估仍然是许多人面临的一个具有挑战性的任务。无论您是通过微调来提高模型的准确性,还是增强检索增强生成(RAG)系统的上下文相关性,了解如何开发并确定适合您的用例的合适的LLM评估指标集对于构建一个坚不可摧的LLM评估流水线至关重要。
本文将教你关于LLM评估指标的一切需要了解的知识,并包含了代码示例。我们将深入探讨以下内容:
- LLM评估指标是什么,常见陷阱,以及使得优秀LLM评估指标出色的因素。
- 所有不同的评分LLM评估指标的方法。
- 如何实施和决定合适的LLM评估指标集的使用。
你准备好长长的清单了吗?让我们开始吧。
什么是LLM评估指标?
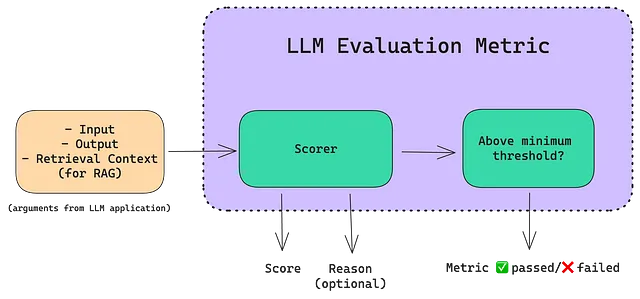
LLM评估指标是根据您关心的标准对LLM的输出进行评分的指标。例如,如果您的LLM应用程序旨在总结新闻文章页面,您将需要一种基于以下标准进行评分的LLM评估指标:
- 摘要中是否包含了足够的原始文本信息。
- 无论摘要中是否存在原文的任何矛盾或幻觉。
此外,如果您的LLM应用程序具有基于RAG的架构,您可能还需要对检索上下文的质量进行评分。关键是,LLM评估指标根据其设计用于执行的任务评估LLM应用程序。
(请注意,LLM申请就是指LLM本身!)
伟大的评估度量标准包括:
- 定量。在评估手头任务时,指标应始终计算得分。这种方法使您能够设定一个最低合格阈值,以确定您的LLM应用程序是否“足够好”,并可以监控这些得分随时间的变化,以便在迭代和改进实施方案时进行调整。
- 可靠性。尽管LLM评估的输出不可预测,但您最不希望的是LLM评估指标同样不稳定。因此,虽然使用LLM评估的指标(也称为LLM-Evals),如G-Eval,比传统评分方法更准确,但它们通常存在不一致性,这也是大多数LLM-Evals的短处所在。
- 准确可靠的评分如果不能真实反映你的LLM申请表现,那么就毫无意义。事实上,使一个良好的LLM评估指标变得更好的秘诀是尽可能与人类期望保持一致。
所以问题变成了,LLM评估指标如何计算可靠和准确的分数?
计算LLM评估指标得分的不同方法
在我之前的一篇文章中,我谈到了LLM输出的难以评估的问题。幸运的是,有许多已建立的方法可用于计算评估指标分数-一些利用神经网络,包括嵌入模型和LLM,而其他方法完全基于统计分析。
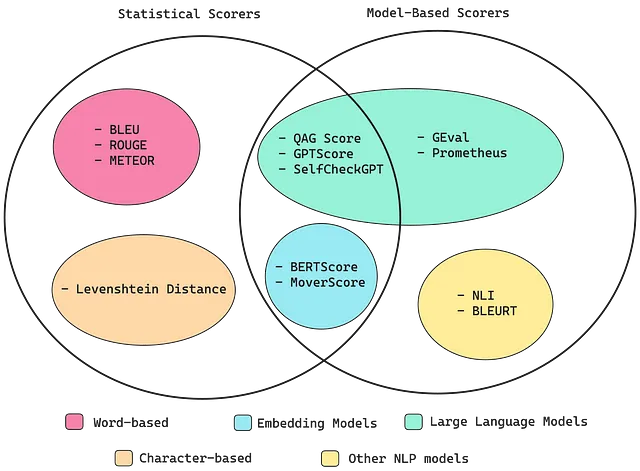
我们将逐个介绍每种方法,并在本节末尾讨论最佳途径,所以继续阅读以获取更多信息!
统计得分者
在我们开始之前,我想首先说的是,在我看来,统计打分方法是非必需学习的,所以如果你很着急的话,可以直接跳到“G-Eval”部分。这是因为在需要推理的时候,统计方法的表现很差,使其作为大多数LLM评估标准的打分工具过于不准确。
快速的浏览一下它们:
- BLEU(双语评估伴侣)评分器通过与已注释的标准答案(或预期输出)对比评估您的LLM应用程序的输出。它计算LLM输出与预期输出之间每个匹配的n-gram(n个连续单词)的精度,计算它们的几何平均值,并在需要时应用简洁惩罚。
- ROUGE(基于召回的摘要评估助手)评分器主要用于评估自然语言处理模型生成的文本摘要,并通过比较LLM输出和预期输出之间的n-gram重叠来计算召回率。它确定参考文本中存在于LLM输出中的n-gram占比(0-1)。
- METEOR(Metric for Evaluation of Translation with Explicit Ordering)评分器更全面,因为它通过评估精确度(n-gram匹配)和召回率(n-gram重叠)来计算分数,并根据LLM输出和预期输出之间的词序差异进行调整。它还利用外部语言数据库如WordNet来考虑同义词。最终得分是精确度和召回率的调和平均值,对于顺序差异有罚款。
- Levenshtein距离(或编辑距离,你可能将其认识为一道LeetCode难题动态规划问题)评分器计算一词或文本串转变为另一词或文本串所需的最小单字符编辑(插入、删除或替换)次数,这对于评估拼写纠正或其他需要精确定位字符的任务可能非常有用。
由于纯统计评分方法几乎不考虑语义,并且推理能力极为有限,因此它们对于评估常常很长且复杂的LLM输出不够准确。
基于模型的评分者
纯粹统计的得分器是可靠但不准确的,因为它们无法考虑语义因素。在这一部分中,正好相反——纯粹依赖自然语言处理模型的得分器在准确性上更可比,但由于其概率性质,也更不可靠。
这并不意味着令人惊讶,但是与统计评分器相同的原因导致非基于LLM的评分器表现较差。非LLM评分器包括:
- NLI评分器使用自然语言推理模型(一种NLP分类模型)来判断LLM输出在逻辑上是否一致(蕴涵)、矛盾或无关(中性)于给定的参考文本。评分通常在蕴涵(值为1)和矛盾(值为0)之间取值,提供了逻辑连贯性的度量。
- The BLEURT(具有来自Transformer的表示的双语评估答卷)评分器使用预训练模型,如BERT,对LLM输出进行评分,并与某些预期输出进行比较。
除了得分不一致之外,现实情况是这些方法存在一些缺点。例如,NLI评分器在处理长文本时准确性也可能受到挑战,而BLEURT则受限于训练数据的质量和代表性。
所以我们开始吧,让我们谈谈LLM评估。
G-评估
G-Eval 是一篇名为“使用 GPT-4 及更好的人类对齐性进行 NLG 评估”的论文中最近开发的框架,它使用 LLMs 来评估 LLM 输出(也称为 LLM-Evals)。
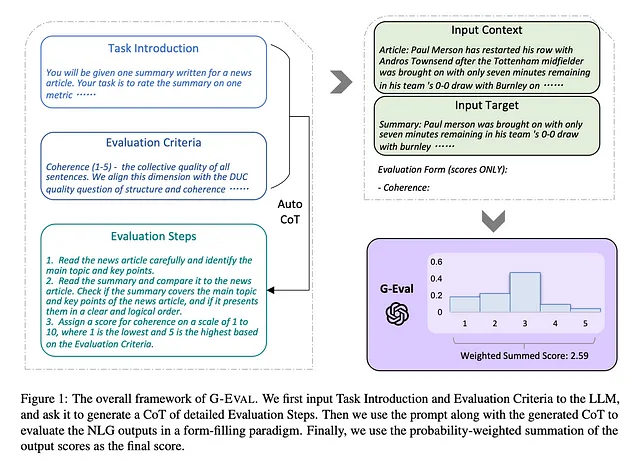
如在我之前的一篇文章中介绍的那样,G-Eval首先通过思维链(CoTs)生成一系列评估步骤,然后再利用生成的步骤通过填表方式确定最终分数(这只是说G-Eval需要一些信息的高级说法)。例如,使用G-Eval评估LLM输出的连贯性就需要构建一个包含评估标准和待评估文本的提示,生成评估步骤,然后利用LLM根据这些步骤输出一个1到5的分数。
让我们使用这个例子来运行G-Eval算法。首先,生成评估步骤:
- 将评估任务引入您选择的LLM项目中(例如,根据连贯性将此输出评分1-5分)
- 给您的标准提供一个定义(例如:“连贯性——实际输出中所有句子的集体质量”)。
在原始的G-Eval论文中,作者只使用了GPT-3.5和GPT-4进行实验,并且在使用不同的LLM模型进行G-Eval实验时,我个人强烈建议您坚持使用这些模型。
在生成一系列评估步骤之后:
- 通过将评估步骤和所有评估步骤中列出的参数连接起来,创建一个提示(例如,如果您想评估LLM输出的一致性,则LLM输出将是一个必需的参数)。
- 在提示结束时,请询问它生成一个1-5之间的分数,其中5代表较好,1代表较差。
- (可选)将LLM的输出令牌的概率用于规范化得分,并将它们的加权求和作为最终结果。
第三步是可选的,因为要获得输出标记的概率,您需要访问原始模型嵌入,而截至2024年,通过OpenAI API仍然无法访问。然而,这一步是在论文中引入的,因为它提供了更细粒度的分数,并且最小化了LLM评分中的偏差(正如论文中所述,3被认为在1-5等级中有更高的标记概率)。
以下是该论文的结果,显示了G-Eval在本文前面提到的所有传统的非LLM eval中表现更好:
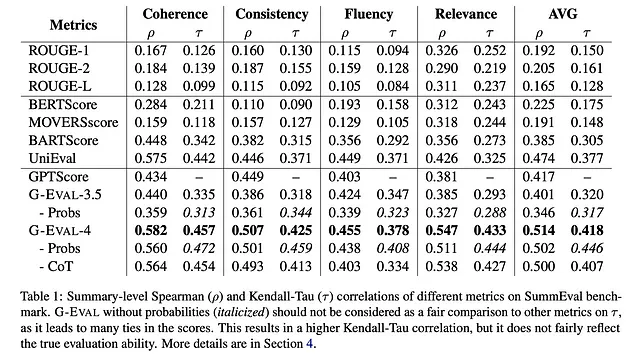
G-Eval 是很好的,因为作为 LLM-Eval,它能够考虑到 LLM 输出的全部语义,使其更准确。这非常有道理——想想看,非 LLM Eval 如何可能理解 LLM 生成的文本的全部范围,它使用的评分器远不如 LLM 强大呢?
尽管与其它同类评估工具相比,G-Eval更能与人的判断相一致,但它仍然可能不可靠,因为让一个法学硕士提供评分显然是主观的。
话虽如此,鉴于G-Eval的评估标准可以非常灵活,我个人已将G-Eval作为一个度量指标实施到DeepEval中,DeepEval是我一直以来在开发的开源LLM评估框架。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="...", actual_output="...")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score)
print(coherence_metric.reason)
使用LLM-Eval的另一个重要优势是,LLM可以生成对其评分的原因。
普罗米修斯
Prometheus是一款完全开源的语言学习模型,当提供适当的参考材料(参考答案、评分标准)时,其评估能力可与GPT-4相媲美。它也是用例无关的,类似于G-Eval。
这是来自Prometheus研究论文的简要结果。
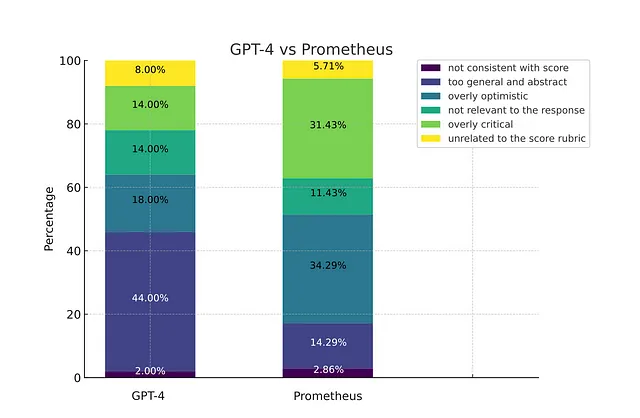
普罗米修斯遵循与G-Eval相同的原则。然而,有几个区别:
- 虽然G-Eval是一个使用GPT-3.5/4的框架,但Prometheus是一个经过LLM精调的评估模型。
- 虽然G-Eval通过CoTs生成评分标准/评估步骤,但是Prometheus的评分标准是在提示中提供的。
- Prometheus需要参考/示例评估结果。
尽管我个人还没有尝试过,但Prometheus在Hugging Face上是可用的。我之所以没有尝试实施它,是因为Prometheus的设计是使评估成为开源的,而不是依赖于专有模型,比如OpenAI的GPTs。对于那些想要构建最好的LLM-Evals的人来说,它不是一个很好的选择。
结合统计学和基于模型的评分器
到目前为止,我们已经看到统计方法是可靠但不准确的,而非LLM(模型)方法则更不可靠但更准确。与上一节类似,还有一些非LLM评分者,比如:
- BERTScore 是一种评分器,它依赖于预训练的语言模型如BERT,并计算参考文本和生成文本中单词的上下文嵌入之间的余弦相似度。然后将这些相似度聚合起来得到最终得分。更高的 BERTScore 表示 LLM 输出与参考文本之间有更大的语义重叠。
使用嵌入模型的MoverScore评分器,特别是预训练语言模型如BERT,先获取参考文本和生成文本的深度上下文词嵌入,然后使用名为地球移动者距离(EMD)的方法来计算将LLM输出中的词分布转换为参考文本中的词分布所需支付的最小成本。
无论是BERTScore还是MoverScore评分器,由于它们依赖于像BERT这样的预训练模型的上下文嵌入,都容易受到上下文意识和偏见的影响。那么LLM-Evals呢?
GPTScore的翻译
与G-Eval直接使用填写表单的范式执行评估任务不同,GPTScore使用生成目标文本的条件概率作为评估指标。
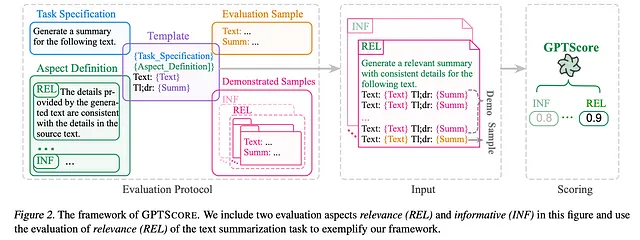
在基准测试方面,GPTScore的斯皮尔曼和肯德尔-塔乌相关性比G-Eval低。
自检GPT
SelfCheckGPT 是一个异类。它是一种简单的基于采样的方法,用于事实核查 LLM 输出。它假设虚构的输出是不可复现的,而如果 LLM 对某个特定概念有知识,采样的回答很可能相似且包含一致的事实。
SelfCheckGPT是一种有趣的方法,因为它使得检测幻觉成为一个无需参照的过程,在生产环境中非常有用。
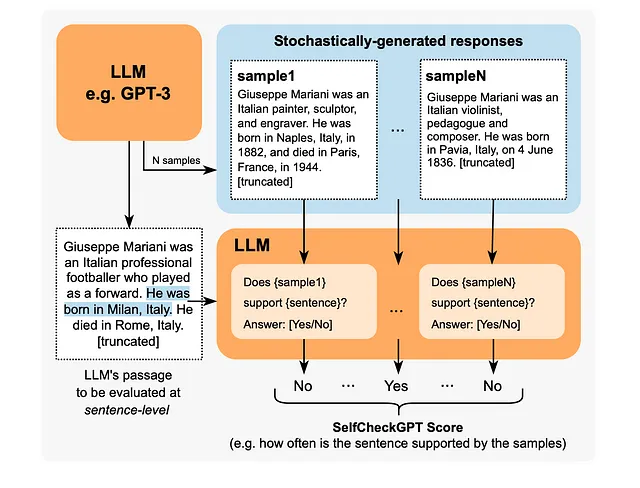
然而,尽管您会注意到G-Eval和Prometheus是用例不可知的,但SelfCheckGPT不是。它仅适用于幻觉检测,并不适用于评估其他用例,如总结、连贯性等。
QAG得分
QAG(问题回答生成)分数是一种评分器,利用LLMs的高推理能力来可靠地评估LLM的输出。它使用回答(通常为“是”或“否”)来计算最终的度量分数,这些回答是针对闭合问题(可以生成或预设的)。它的可靠性在于它并不直接使用LLMs来生成分数。例如,如果您想计算忠实度的分数(衡量LLM输出是否虚构),您可以进行以下操作:
- 使用LLM提取LLM输出中的所有声明。
- 对于每个索赔,请询问真实情况是否与所做的索赔一致( "是 ")或不一致( "否 ")。
因此,对于这个例子,LLM输出:
一个主张可能是:
马丁·路德·金于1968年4月4日被暗杀。
而对应的封闭式问题是:
马丁·路德·金在1968年4月4日被暗杀?
您将采取这个问题,并询问地面真相是否与该说法一致。最终,您将得到一些“是”和“不是”答案,您可以使用某种您选择的数学公式来计算得分。
在忠诚度的情况下,如果我们将其定义为LLM输出中与实际情况准确一致的索赔比例,就可以通过将准确(真实)索赔的数量除以LLM所提出的总索赔数量来轻松计算。由于我们并非直接使用LLM生成评估分数,而是利用其卓越的推理能力,所以我们得到的分数既准确又可靠。
选择您的LLM评估指标
选择使用哪种LLM评估指标取决于您的LLM应用的用例和架构。
例如,如果您正在基于OpenAI的GPT模型构建基于红黄绿三色评估的客户支持聊天机器人,您将需要使用几个红黄绿三色评估指标(例如,忠实度、答案相关性、上下文准确性)。而如果您正在微调自己的Mistral 7B模型,您将需要使用偏见度等评估指标来确保公正的语言生成模型决策。
在这个最后一部分,我们将介绍您绝对需要了解的评估指标。(并作为额外奖励,介绍每个指标的实施方案。)
RAG指标
对于那些还不知道什么是RAG(检索增强生成)的人来说,这是一篇很好的阅读材料。简单来说,RAG用作一种方法,通过提供额外的上下文来补充LLMs生成定制化输出,非常适用于构建聊天机器人。它由两个组件组成——检索器和生成器。
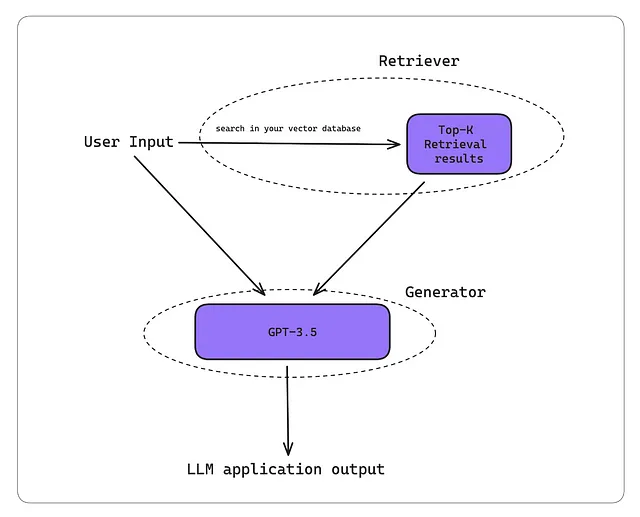
这是一个RAG工作流通常的工作方式:
- 您的RAG系统接收输入。
- 寻回者使用此输入在您的知识库中进行矢量搜索(如今在大多数情况下是一个矢量数据库)。
- 生成器将检索上下文和用户输入作为额外的上下文接收,以生成定制输出。
这是一件值得记住的事情——高质量的LLM产出是伟大的检索器和生成器的产物。因此,伟大的RAG指标侧重于以可靠和准确的方式评估您的RAG检索器或生成器之一。(事实上,RAG指标最初被设计为无参考的度量,意味着它们不需要基准真实性,使它们即使在生产环境中也可以使用。)
忠诚
忠实度是一个RAG指标,用于评估您RAG管道中的LLM/生成器是否生成与检索上下文中呈现的信息相符的LLM输出。但我们应该使用哪个评分器来衡量忠实度指标呢?
剧透警告:QAG评分器是用于RAG指标的最佳评分器,因为它在目标明确的评估任务中表现出色。对于忠实性而言,如果你将其定义为LLM输出中与检索上下文相关的真实性声明的比例,我们可以通过以下算法使用QAG来计算忠实性:
- 使用LLMs来提取输出中的所有声明。
- 对于每个主张,检查它是否与检索上下文中的每个单独节点一致或矛盾。在这种情况下,QAG中的封闭式问题将是:“给定的主张是否与参考文本一致”,其中 “参考文本” 将是每个单独检索到的节点。(请注意,你需要将答案限制在“是”、“否”或“不知道”的选择中。 “不知道”状态表示检索上下文不包含相关信息以进行是/否回答的边缘情况。)
- 把所有真实主张('yes'和'idk')的总数相加,然后除以所有主张的总数。
通过使用LLM的高级推理能力并避免LLM生成的分数的不可靠性,这种方法确保准确性,使其比G-Eval更好的评分方法。
如果您覺得這個實現過於複雜,您可以使用DeepEval。這是我建立的一個開源專案,提供了所有您需要進行LLM評估的評估指標,包括忠實度指標。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = FaithfulnessMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
DeepEval将评估视为测试案例。在这里,actual_output只是您的LLM输出。此外,由于忠实度是LLM-Eval的一部分,您可以获得最终计算得分的推理。
答案相关性
答案相关性是一个评估你的RAG生成器是否输出简洁回答的RAG指标,可以通过确定LLM输出中与输入相关的句子比例来计算(即,将相关句子数量除以总句子数量)。
构建一个强大的答案相关性度量的关键是考虑检索背景,因为额外的背景可能会证明一个看似无关的句子的相关性。以下是答案相关性度量的实施示例:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
(记住,我们将所有RAG指标都使用QAG)
上下文精确
上下文精确度是一种用于评估RAG管道检索器质量的RAG指标。当我们谈论上下文度量时,我们主要关注检索上下文的相关性。高上下文精确度分数意味着在检索上下文中相关的节点排名比不相关的节点更高。这一点很重要,因为语言模型对出现在检索上下文中较早的节点中的信息给予更高的权重,这会影响最终输出的质量。
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
语境回忆
上下文精确度是评估检索增强生成器(RAG)的一种附加指标。它通过确定预期输出或真实情况中可以归因于检索上下文节点的句子比例来计算。较高的得分表示检索工具有效地提取相关准确的内容来帮助生成器产生上下文合适的回复,从而显示出检索工具与预期输出之间更好的对齐。
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
上下文相关性
可能是最简单易懂的度量标准,上下文相关性就是检索环境中与给定输入相关的句子所占的比例。
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
微调指标
当我说“微调度量”时,我实际上指的是评估LLM本身而不是整个系统的度量。暂且不考虑成本和性能的好处,LLM经常被微调为以下两种情况之一:
- 加入额外的上下文知识。
- 调整它的行为。
幻觉
有些人可能会认出这与忠诚度指标相同。尽管相似,但在微调中的产生幻觉较为复杂,因为往往很难确定给定输出的确切真实性。为了解决这个问题,我们可以利用SelfCheckGPT的零样本方法来采样LLM输出中幻觉句子的比例。
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())
然而,这种方法可能非常昂贵,所以目前我建议使用一个NLI评分器并手动提供一些上下文作为基准事实。
毒性
毒性度量评估文本中包含的冒犯、有害或不适当语言的程度。利用BERT得分器等即用型预训练模型(如Detoxify)可以用于评分毒性。
pip install detoxify
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)
然而,由于评论中存在与咒骂、侮辱或亵渎有关的词语,即使作者的语气或意图是幽默或自嘲,这种方法可能会产生不准确的结果,导致该评论被归类为有毒。
在这种情况下,您可能希望考虑使用G-Eval来定义一个自定义的毒性标准。实际上,G-Eval的用例不受限制的特性是我喜欢它的主要原因。
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Toxicity",
criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)
偏见
偏见指标评估文本内容中的政治、性别和社会偏见等方面。这对涉及自定义LMM参与决策过程的应用特别关键。例如,通过提供公正推荐来协助银行贷款审批,或者在招聘中,它能帮助确定候选人是否应该被列入面试名单。
与有毒性类似,偏见也可以通过G-Eval进行评估。(但是别误会,QAG也可以成为评估有毒性和偏见等指标的可行评分器。)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)
偏见是一个高度主观的问题,在不同的地理、地缘政治和地缘社会环境中变化显著。例如,在一个文化中被认为是中立的语言或表达,在另一个文化中可能具有不同的内涵。(这也是为什么少样本评估不适用于偏见的原因。)
潜在的解决方案可能是对一个定制的LLM进行微调来进行评估,正因为如此,我认为偏见是最难实施的指标。
应用特定的度量指标
总结
我在之前的一篇文章中详细介绍了总结度量标准,所以我强烈推荐你仔细阅读(并且我保证它比这篇文章要短得多)。
总之(不打趣),所有好的摘要:
- 在事实上与原始文本一致。
- 包含原文的重要信息。
使用问答生成(QAG)技术,我们可以计算事实对齐和包容得分,以计算最终的摘要得分。在DeepEval中,我们将这两个中间得分的最小值作为最终的摘要得分。
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
诚然,由于我不想让这篇文章更长,我没有充分展示摘要评估指标的重要性。但是对于那些感兴趣的人,我强烈推荐阅读本文,了解如何使用问答生成(QAG)构建您自己的摘要评估指标。
结论
祝贺您走到了最后!这是一个漫长的得分和指标列表,我希望您现在已经了解了在选择LLM评估指标时需要考虑的各种因素和您需要做出的选择。
主要目标是评估LLM度量标准,以量化LLM(申请)的表现。为此,我们有不同的评分者,有些比其他评分者更优秀。对于LLM评估而言,使用LLMs(G-Eval、Prometheus、SelfCheckGPT和QAG)的评分者因其高度的推理能力而最准确,但我们需要采取额外的预防措施来确保这些评分是可靠的。
到了一天的尽头,度量选择取决于您的使用案例和LLM应用的实施方式,其中RAG和微调度量是评估LLM输出的绝佳起点。对于更具特定使用案例的度量,您可以使用G-Eval和少量提示来获取最准确的结果。
不要忘记给⭐ DeepEval 在 Github 上点一颗星星⭐️,如果你觉得这篇文章有用的话,一如既往地,我们下次见。