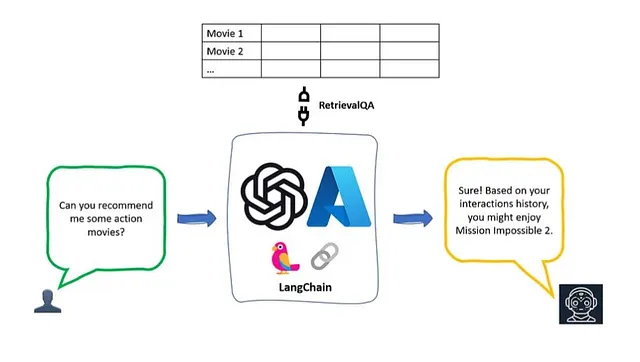
LLM,Lang Chain和Pydantic:面向对象的Web数据提取的三剑客
你想以面向对象的方式从任何网站或URL中提取数据,而无需编写复杂的解析器或手动初始化对象吗?如果是的话,那么这篇文章就是为你准备的。在本文中,我将向你展示如何使用LLM¹(语言学习模型)和Lang Chain,这是一个用于构建自然语言应用程序的强大框架,将数据从任何来源提取出来并解析成用户定义的Pydantic¹模型。Pydantic是一个使用Python类型注释验证和解析数据的库。通过使用LLM、Lang Chain和Pydantic,你可以轻松以干净、可预测和结构化的方式提取数据,并直接访问提取对象的属性。这将节省你大量的时间和精力,并使你的网络爬虫任务更加愉快和高效。
例如,如您所见,我想从此网址提取产品详细信息,下面是我想提取的手机列表。
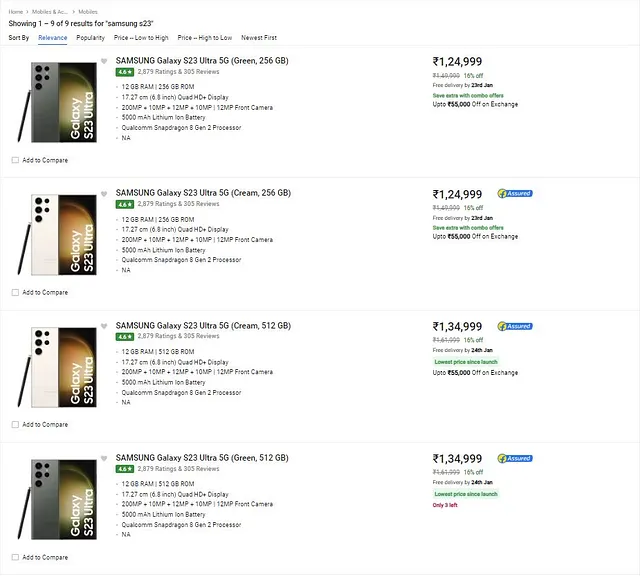
这是从LLM直接提取的数据的对象表现形式。

如果您想了解如何从任何外部来源(例如网络)中以对象格式提取数据,请花点时间了解相关概念。
要了解什么是LLM和LangChain,请阅读我之前的故事,我在其中详细解释了。因此,在我们进入细节之前,我们需要熟悉一些称为输出解析器的Lang Chain功能。
输出解析器是Lang Chain中的对象,它们允许我们解析LLM的输出/响应为干净且可预测的数据类型或对象。Lang Chain提供了一些输出解析器,我已在下面列出。
- 日期时间 — 将响应解析为日期时间字符串
- 以逗号分隔 — 返回逗号分隔的数值列表
- PandasDataFrame — 用于对pandas数据框进行操作的有用工具
- Pydantic⁴ — 接受用户定义的 Pydantic 模型,并以该格式返回数据
要使用Pydantic模型,我们需要安装pydantic Python模块。我将在最后提供完整的源代码。
pip install pydantic
从lanchain中导入PydanticOutputParser,如下所示。
from langchain.output_parsers import PydanticOutputParser
使用我们的Python类创建您的Pydantic模型。
class ProductDetails(BaseModel):
'''
This class is used to capture additional product details related to Mobile
'''
RAM: int = Field(descriptoin="RAM of the mobile")
ROM: int = Field(description="ROM of the mobile")
Battery: int = Field(description="Battery capacity of the mobile")
class Product(BaseModel):
'''
This class is used to capture primary product details of Mobile
'''
Name: str = Field(description="Name of the mobile.")
Price: int = Field(description="Price of the mobile.")
Details: ProductDetails = Field(description="Additional features of the Mobile")
class Products(BaseModel):
'''
This class is used to store the collection/list of Mobiles
'''
Mobiles: list[Product] = Field("List of mobiles listed in the text")
现在我们可以创建输出解析器并查看输出解析器的格式说明。幸运的是,Pydantic为我们创建了这些说明,所以我们不再需要担心精确调整我们的提示了。
output_parser = PydanticOutputParser(pydantic_object = Products)
format_instructions = output_parser.get_format_instructions()
'''
The output should be formatted as a JSON instance that conforms to the JSON
schema below.\n\nAs an example, for the schema
{
"properties": {
"foo": {
"title": "Foo",
"description": "a list of strings",
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"foo"
]
}
\n
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema.
The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\n
Here is the output schema:\n```\n
{
"$defs": {
"Product": {
"description": "This class is used to capture primary product details of Mobile",
"properties": {
"Name": {
"description": "Name of the mobile.",
"title": "Name",
"type": "string"
},
"Price": {
"description": "Price of the mobile.",
"title": "Price",
"type": "integer"
},
"Details": {
"allOf": [
{
"$ref": "#/$defs/ProductDetails"
}
],
"description": "Additional features of the Mobile"
}
},
"required": [
"Name",
"Price",
"Details"
],
"title": "Product",
"type": "object"
},
"ProductDetails": {
"description": "This class is used to capture additional product details related to Mobile",
"properties": {
"RAM": {
"descriptoin": "RAM of the mobile",
"title": "Ram",
"type": "integer"
},
"ROM": {
"description": "ROM of the mobile",
"title": "Rom",
"type": "integer"
},
"Battery": {
"description": "Battery capacity of the mobile",
"title": "Battery",
"type": "integer"
}
},
"required": [
"RAM",
"ROM",
"Battery"
],
"title": "ProductDetails",
"type": "object"
}
},
"description": "This class is used to store the collection/list of Mobiles ",
"properties": {
"Mobiles": {
"default": "List of mobiles listed in the text",
"items": {
"$ref": "#/$defs/Product"
},
"title": "Mobiles",
"type": "array"
}
}
}
'''
'The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\nAs an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}\nthe object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\nHere is the output schema:\n```\n{"$defs": {"Product": {"description": "This class is used to capture primary product details of Mobile", "properties": {"Name": {"description": "Name of the mobile.", "title": "Name", "type": "string"}, "Price": {"description": "Price of the mobile.", "title": "Price", "type": "integer"}, "Details": {"allOf": [{"$ref": "#/$defs/ProductDetails"}], "description": "Additional features of the Mobile"}}, "required": ["Name", "Price", "Details"], "title": "Product", "type": "object"}, "ProductDetails": {"description": "This class is used to capture additional product details related to Mobile", "properties": {"RAM": {"descriptoin": "RAM of the mobile", "title": "Ram", "type": "integer"}, "ROM": {"description": "ROM of the mobile", "title": "Rom", "type": "integer"}, "Battery": {"description": "Battery capacity of the mobile", "title": "Battery", "type": "integer"}}, "required": ["RAM", "ROM", "Battery"], "title": "ProductDetails", "type": "object"}}, "description": "This class is used to store the collection/list of Mobiles ", "properties": {"Mobiles": {"default": "List of mobiles listed in the text", "items": {"$ref": "#/$defs/Product"}, "title": "Mobiles", "type": "array"}}}\n```'
现在,让我们创建一个链来调用网页的文本并查看输出,如果你看一下提示,我刚刚写了一个基本的提示,其余的事情都由输出解析器处理。
# Create a prompt and pass the html text to LLM for extracting data as per our model
human_text = "{instruction}\n{format_instructions}"
message = HumanMessagePromptTemplate.from_template(human_text)
prompt = ChatPromptTemplate.from_messages([message])
chain = prompt | llm | output_parser
products = chain.invoke({"instruction":"Extract all the products from the below text \n" + html_text,"format_instructions":format_instructions})
print(products.Mobiles)
'''
[Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Cream, 256 GB)', Price=124999, Details=ProductDetails(RAM=12, ROM=256, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Green, 256 GB)', Price=124999, Details=ProductDetails(RAM=12, ROM=256, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Phantom Black, 256 GB)', Price=124999, Details=ProductDetails(RAM=12, ROM=256, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Cream, 512 GB)', Price=134999, Details=ProductDetails(RAM=12, ROM=512, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Green, 512 GB)', Price=134999, Details=ProductDetails(RAM=12, ROM=512, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Green, 1 TB)', Price=154999, Details=ProductDetails(RAM=12, ROM=1024, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Cream, 1 TB)', Price=154999, Details=ProductDetails(RAM=12, ROM=1024, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Phantom Black, 1 TB)', Price=154999, Details=ProductDetails(RAM=12, ROM=1024, Battery=5000)),
Product(Name='SAMSUNG Galaxy S23 Ultra 5G (Phantom Black, 512 GB)', Price=134999, Details=ProductDetails(RAM=12, ROM=512, Battery=5000))]
'''
哇,输出看起来很棒。虽然我们没有初始化对象内的数据,但 Pydantic 解析器已经处理了一切。我们只需引用每个对象的相应属性,并直接使用它们。
我希望分享下面的完整工作笔记,请随意尝试。这将使我们在使用LLM时更加方便。
在这篇文章中,我向你展示了如何使用LLM、Lang Chain和Pydantic以面向对象的方式来爬取网络数据。这种方法通过允许你将数据提取到用户定义的Pydantic模型中,而无需编写复杂的解析器或手动初始化对象,简化了网络爬取过程。你可以直接访问提取对象的属性,并将它们用于分析或应用程序中。如果你想自己尝试这种方法,你可以在我的GitHub存储库中找到代码和说明。如果你喜欢这篇文章,请给它点赞并与你的朋友分享。如果你有任何问题或反馈,请随时在下方留言。感谢你的阅读,祝你愉快的网络爬虫! 😊
[1] LLM:大型语言模型 — 维基百科
[2] Pydantic:欢迎使用Pydantic — Pydantic
[3] LangChain: 开始 | 🦜️🔗 Langchain
[4] Pydantic输出解析器:Pydantic解析器| 🦜️🔗 Langchain