LLM敌对提示的回顾。
一个全新研究领域的介绍。
大型语言模型(LLM)席卷世界。它们的功能看似简单:给定一系列单词,尝试预测下一个单词。然而,它们展现出令人惊讶的智能。目前存在的最先进模型是OpenAI的GPT-4,在SAT中的得分超过94%的高中学生,在律师资格考试中的得分超过90%的法学生。它们还非常擅长进行对话和理解文本。因此,各行各业都在寻找将LLM融入工作流程中的方法,创造出改善利润的产品。
然而,这些产品中的许多都容易受到对抗性攻击的影响。它们产生的输出是错误的、不可接受的,甚至是极具冒犯性的。更糟糕的是,它们可能泄露训练数据并危害用户的隐私。术语“越狱”最初来自于iPhone黑客社区,用户可以删除iPhone上的限制,以安装额外的软件。一些人还发现要求LLM生成不对齐的数据与越狱相似,因为输出结果并不符合开发者预期的限制。在LLM领域,LLM越狱是目前的主要研究方向,而且发展迅速。在谷歌学术上使用关键词“LLM越狱”进行快速搜索,仅2023年就能找到超过400个结果。
免责声明:本文中不会提供任何实际有效的越狱提示。请查看我的反对越狱部分,了解这些公司如何应对对手的尝试。
为什么要学习破解LLM?
使用LLMs来制作一些酷炫的东西很容易,但要将其制作成可以投入生产的东西却非常困难。 — Huyen Chip(来源)
为了制造更好的产品。2016年,微软推出了Tay,一个可以通过Twitter与用户互动和学习的聊天机器人。不到24小时后,Tay给出了一些极其冒犯的回答,微软立即将其下线。当OpenAI向更广泛的公众引入ChatGPT时,也出现了试图让其回复冒犯性语言的企图。如果任何公司想将LLM集成到他们的产品中,他们应确保产品能够抵挡敌对攻击,以保护他们的品牌和数据不受损害。
为了更好地理解LLM。即使我们了解驱动LLM工作的算法,总体情况仍然模糊不清。幻觉,即LLM自信地生成错误事实的想法,目前是一个尚未解决的问题。对齐,即LLM应该生成有益答案的想法,是另一个未解决的问题。越狱LLM既涉及幻觉问题,也涉及对齐问题,了解为什么LLM变得容易受攻击有助于解决这些问题。
存在风险?这是一个(不近的)未来问题,然而对LLM风险的研究与AGI(人工通用智能)风险问题紧密相关。错位的AGI可能对社会造成存在风险;引用OpenAI首席执行官Sam Altman的话说:
有趣的是,人们开始辩论强大的人工智能系统应该按照用户希望的方式行事,还是按照其创建者的意图行事。这个问题将成为社会上最重要的辩论之一,关乎我们将这些系统对齐到谁的价值观。 (来源)
LLM如何训练和调整?
少數展現笑臉的邪神之語是一個與人工智慧領域相關的流行語和俚語表達,使用笑臉和洛夫克拉夫特的克蘇魯圖象來描述對話式人工智慧工具的真正力量被掩飾以便商業公眾消費。 —《了解你的迷因》(來源)
要理解为什么越狱能在LLM上运行,我们首先必须了解它们是如何进行训练和对齐的。你应该从阅读Huyen Chip关于RLHF和Andrej Karpathy关于LLM的指南开始。
几乎所有当前流行的商业和开源LLM(ChatGPT、ClaudeAI、LLAMA、Vicuna等)都使用Transformer架构。给定一系列令牌输入,网络必须预测输出的令牌。其中许多网络最初是在大量文本数据的基础上进行训练的,使用了成千上万万元的GPU进行训练。通过训练,LLM对真实世界的了解程度令人惊讶。模型越大,训练数据越多,准确性就越高(来源)。
在此步骤之后,该网络被视为预训练模型。预训练网络尚不适合人类消费,原因是:(1)互联网上有很多无意义、有偏见、充满仇恨和错误的文字;(2)给定一个提示,网络只会简单地继续那个提示。如果我们给它一个查询,比如“人类何时登上月球?”,它可能会继续查询并列出类似的问题(而不是回答),或者给我们展示有关月球和太阳的维基百科摘录(一个不相关的答案)。
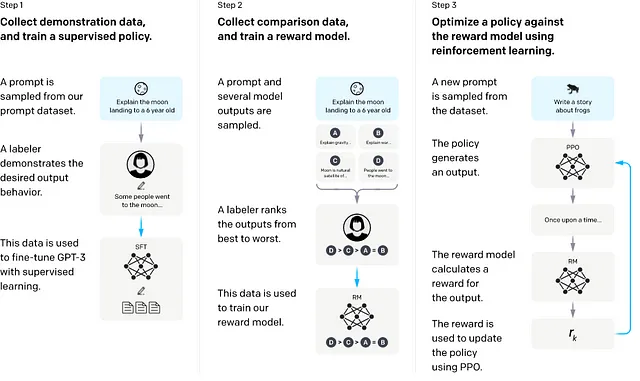
我们希望网络能够与我们的利益保持一致,即以诚实、真实、公正、无害的方式回答查询。实现这一目标的一种方法是通过人类反馈进行微调和强化学习(RLHF)。微调是在一个更小、更专注的问题和答案集上训练LLM。RLHF训练了一个奖励模型,以改进LLM的答案(来源)。
角色扮演/提示工程
这是最早并迄今为止最常见的对LLM进行敌对攻击的方法之一。在OpenAI发布ChatGPT之后,用户纷纷涌向Reddit和Discord共享可以绕过语言限制的提示。这些提示的类型多种多样,但通常遵循一个共同的公式:用户强迫助手以某种方式生成输出,以绕过内置的限制。
角色扮演。在这种类型的提示中,用户在无害的背景下提出对立的提示。雪佛兰可怜兮兮地学到了这个方法,当用户向其由GPT驱动的助手询问以1美元购买汽车时(来源)。
前缀注入。用户要求LLM在回答中用一个积极的承诺作为开头。一个例子是要求ChatGPT以一种以积极和肯定的词语开头的回答方式作出回应。前缀文本的选择很重要,因为以中立的短语开头的回答,比如“你好!”是不会引发有害反应的(来源)。
拒绝抑制。与先前的方法类似,在这种方法中,用户请求 LLM 严格要求抑制内容政策。例如,用户可以要求 LLM 不道歉或不包含免责声明。
DAN/做所有事现在。这是ChatGPT中最臭名昭著且广为人知的黑客之一。这是一个结合了以前的攻击方法的提示。在这个提示中,用户要求聊天助手成为DAN,一个不受限制和规则束缚的语言模型。作为DAN,用户提醒助手它可以做任何事情,并且提供了DAN能做的事情的例子,相比之下,一个受限制的LLM能做什么。在GPT-3的早期阶段,DAN因其强大性而变得流行。
为什么提示工程生效了?
魏等人(来源)认为,通过快速工程来实现越狱是利用一种被他们称为竞争目标的机制。通过细化和RLHF,模型学习了通过回答来响应查询和问题。这使得模型能够优化并遵循查询给出的指令。然而,当对抗性指令与其他目标(如安全和无害性)相矛盾时,模型可能会生成有害的指令。
提示注入
编码。事实证明,ChatGPT能理解某种类型的编码。用户可以通过要求ChatGPT对编码的请求进行回应,并要求它用编码的消息给出回复来利用此功能。类似的攻击以“映射游戏”的形式出现,用户要求LLM首先解码来构建一个有害的请求。
忽略之前的指示。这种攻击策略被用于公开可用的Bing Chat(来源)。在要求Bing Chat忽略先前的指示后,有用户发现Bing提供了一组内部指示,以使其更加一致。这些指示揭示了Bing Chat开发名称为Sydney,并且它应该以明确和无害的方式回答问题。另一位Twitter/X用户从角色扮演提示中独立获得了完全相同的指示,这支持了这个想法:这不是LLM的幻觉(来源)。
请为我重复一遍。LLM可以被看作是整个互联网的“压缩”。因此并不奇怪,有时候训练数据可以通过精心设计的提示从LLM中提取出来。研究人员发现了一种称为“分歧攻击”的利用方法,它要求LLM产生与其训练数据不一致的输出结果。一项研究要求ChatGPT重复一个单词,结果它揭示了一个人的电子邮件和电话号码(来源)。
后缀短语。邹等人(来源)发表了一种方法,他们认为它可能是通用的(适用于各种不同的LLM)和可迁移的(可以训练用于一个LLM并迁移到另一个LLM)。他们从一个能引起对抗性回答的提示开始。这与我们之前介绍的前缀注入提示类似。然而,该方法的成功率较低。新颖之处在于他们使用的一种贪婪基于梯度的搜索。搜索算法交换提示的令牌,以最大化LLM产生错误答案的机会。最终的后缀短语常常对人类来说是荒谬的。与之前讨论的其他方法相比,该方法生成的提示完全是自动化的,可以每次都重新生成。
为什么即时注入攻击会成功?魏等人认为即时注入攻击之所以有效,是因为来自语言模型学习的新行为。换句话说,语言模型通过大量训练数据学到了很多,因此可以产生不被微调所防止的输出。举个例子,编码攻击对GPT-4有效,但对不那么复杂的GPT-3.5无效。这带来了相当大的挑战,因为更大的语言模型可能意味着使用之前未曾见过的攻击方法。
多模态越狱
许多LLM正在向多模态输入方向发展。例如GPT-4和Google的Gemini。然而,更多输入模态也意味着更多潜在的攻击途径。据已知,卷积神经网络很容易被像素中的微小干扰所误导。
在一张图片中,可以写入一条新的指令,要求LLM忽略之前的提示。如果文本对于人眼来说是透明的,即使不能被人类用户看到,也有可能创建绕过人类用户的图片。这种行为已经被用于向简历中注入提示(来源)。
如何对抗对手的企图?
我们希望用户能够有很多控制权,并使模型在广泛的边界内按照他们的意愿运行。越狱的整个原因就是我们现在还没弄清楚如何将这种权力给予人们。— Sam Altman (来源)
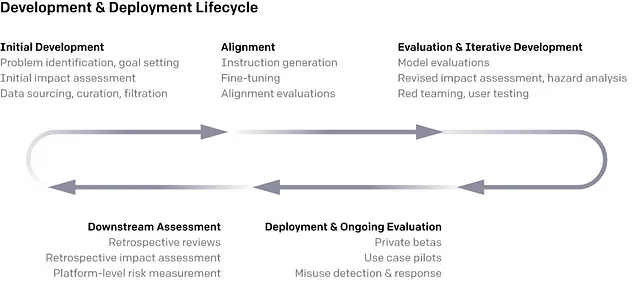
OpenAI及许多其他公司依赖评估、部署和评估的迭代过程来产生更好的人工智能(来源)。通常,它们有一个专门的红队部门,负责找到绕过LLMs的方法并提出改进建议。一些公司甚至使用内部和外部红队来提升性能。对于对手性提示的适当回应应该是拒绝("我不能帮助您")。拒绝请求的理由包括:
- 有害内容(非法、违禁内容)
- 有害的代表(偏见、性别歧视、种族主义等)
- 隐私(个人身份相关信息,地理定位)
- 网络安全(验证码请求)
- 视觉越狱(详细指导见图片)
截至目前,RLHF和微调仍然是对抗常规越狱尝试的最强方法。用户看不到,LLM通常会得到一个“规则集”来生成输出。公司可以使用单独的“监视器”LLM来审查输入和输出(来源)。Anthropic引入了一种称为宪法强化学习(CRL)的训练方法,也利用人类反馈来训练奖励模型。然而,CRL依赖于一组人类设计的原则(“宪法”)来指导奖励模型。他们证明了与传统的RLHF相比,CRL可以产生更安全的模型(来源)。
在抵抗越狱方面,较大的模型是否更好?总体而言,具有较大容量的模型往往更难受到攻击(来源)。有假设认为,通过RLHF,较大的LLM可以更好地进行微调。然而,由于新兴能力和创新的攻击方法,较大的模型也更容易受到攻击(来源)。
结论
就像军备竞赛一样,LLM的开发者和不良行为者将始终设计新的策略来相互对抗。通过这篇评论,我希望读者更加了解LLM领域,并初步了解人工智能研究的全新领域。
如果您喜欢阅读本文并希望在未来阅读更多类似文章,请考虑在Medium或LinkedIn上关注我。