如何使用自定义的GPT(无需编码)克隆自己
在最近在波士顿举行的一次面对面人工智能会议上,我收到了一位参会者的奇怪请求。
嘿,我能够使用她的公开信息来建立一个她的复制人吗?
首先,我感到很好奇。然后几天后,我收到了一封来自一个我认识多年的人的第二封电子邮件。
我正在与一位前哈佛大学教授合作开展一个项目。我们实际上是希望将他所有的先前作品、演讲和论文转化为一个聊天机器人,您可以向教授提出任何问题。
好的 - 就是这样 - 那有什么比克隆自己作为测试更好的方法呢。
因此,不再拖延,让我们开始吧!
为什么要克隆自己?
除了虚荣心之外,有一些引人注目的理由来进行这样的事情。
保留知识
通过建立一个以人工智能为基础的自我克隆体,你在实质上将自己的知识、观点和经验以一种易于获取和互动的方式保存下来。
即使您没有直接的可用性,对于希望利用您的专业知识的人来说,这将非常有用。
这就像留下一个可以随时参考的认知遗产。
可扩展的导师和沟通
如果您是有影响力的人、领导者或者在您的领域内是专家,很有可能有许多人想向您学习或者请教您的建议。
问题是:有时候你倾向于入睡(是的,没错,哈哈!)
一个自己的人工智能克隆使得你的指导可以在更大的范围内分享,而不受个人时间和精力的限制。
它可以提供导师指导、提供建议,或者就你的想法和哲学展开讨论。
自我反思和成长
构建一个自我的AI克隆的过程可以成为一种自我发现和反思的锻炼。它迫使你将自己的思维、想法和知识精炼成一个可以被AI模型理解的格式。
这不仅有助于澄清您对自己已知和相信的事情的理解,还为您提供了重新评估和潜在成长的机会。
嘿,你甚至可能发现一些谷歌已经知道的有关你的事情。
炫耀一下!
好 - 这可能有点过分了 - 但有些人喜欢炫耀..
我不得不承认:我做这件事的一个动机之一就是为了炫耀一下我的板球统计数据 — 哈哈 ..
但是我确定很多人的成就比我更好,展示他们的知识和广泛的信息来源可能是有道理的(特别是在学术界发表论文很重要的情况下!) - 所以使你的终身工作容易获取具有真正的价值(超越了虚荣心!)
在你做之前...
虽然有些人可能认为这是一项艰巨的任务,但你现在可以通过无代码定制GPT构建平台来轻松完成。但是,请先检查一些事情:
没有幻觉
确保您使用的任何工具都不会出现幻觉——也就是说,不会捏造事实!让我们再读一遍:不要捏造事实。这一点非常重要,因为您不希望您的克隆体说出超出您知识范围的事情。
多源数据集成
您的数据可能分散在数百个地方。从各种网站资源到PDF文件,再到YouTube和社交媒体,清单还在继续增长。
确保您选择的任何平台都内置了多种工具,以帮助您从各种来源摄取数据。当克隆自己时,这是最困难的部分-因为你希望从各种来源如网站、社交媒体、YouTube视频、PDF文件、谷歌结果等摄取公共数据。
所以你需要一个已经为你处理了这个困难部分的平台。
隐私与安全
对于这样敏感的事情,您需要一个商业级平台,以保护隐私和安全为主。
虽然您的一些数据可能已经是公开的,但您希望有一个保护隐私的平台来审查与您的聊天机器人询问相关的问题并从中收集信息。
换句话说,您需要查看聊天记录。
案例研究
麻省塔夫茨大学的Michael Levin博士希望通过提供一个平台,使学生、研究人员和好奇的公众能够直接参与他的实验室在发育生物物理学、计算机科学和认知科学方面的广泛研究,以提高他实验室深入知识的可访问性和互动性。
他希望创建一款名为LevinBot的工具,不仅可以提供复杂科学问题的详细准确答案,还能体现Levin实验室的审美和思想精髓。

LevinBot改变了Levin实验室的在线存在。全球用户现在可以与LevinBot进行24/7的互动,提出复杂的科学问题,并获得在90余种语言中经过良好来源和准确的回答。
显著扩充了官方网站的常见问题解答部分后,LevinBot 提供了一种更具动态和对话式的用户体验。用户无需花数小时浏览源资料,只需几秒钟便可得到他们最迫切的科学问题的答案。
逐步指南
现在这是令人惊讶的部分-您可能开始阅读这篇博客文章时认为像这样的事情需要几天时间-不,它可以在几分钟内完成。
第一步:收集您的数据源
第一件事就是决定你想要摄入什么内容。例如,我决定使用自己作为实验对象,创建一个包含关于我的所有公开可用信息的集成聊天机器人。以下是我添加的数据来源。
- 以我的名字显示的谷歌搜索结果清单。
- 各种公共文件(如我的简历)
- 深入搜索我的名字(来自Facebook,Twitter,Cricinfo等)的结果
- YouTube视频
一个建议:请确定您想要摄入哪些数据,并确定您希望将其保留为私有还是公开的。这部分非常重要。如果您计划公开您的聊天机器人,请确保只摄入公开数据。
另一个需要考虑的事情是:一些最重要的数据可能隐藏在付费墙后面。因此,在将其输入到机器人之前,您可能需要先进行“另存为”操作(例如:我有点沮丧,因为我的板球统计数据无法被机器人摄取,它们被隐藏在登录收费墙之后——啊啊啊!)
忍者动作:如果你的无代码平台支持RSS订阅,你甚至可以在信息发生时动态地摄取信息(比如来自新闻订阅!)。想象一下可能性吧。
Step 2: 添加来源
现在,您有了漂亮的文档和表示每个来源或文档/文件列表的站点地图,您将它们添加到您的聊天机器人中。
请注意:您不需要任何编码经验。只需使用“添加站点地图”或“添加文件”按钮,并让其完成操作。
步骤3:开始交谈!
在几分钟之内,您可以开始与聊天机器人进行交谈。就是这样。您完成了!
尝试一些您预计目标受众可能提出的查询。设置一些示例提示(以引导用户!)
您可以决定如何部署您的聊天机器人。大多数人将其放在他们的网站上,让人们通过在线聊天与其交流,甚至可以使用API将其集成到您的系统中。
忍者提示:有些人要求我为他们建立一个聊天机器人,可以以他们的语调和风格回复他们的电子邮件。哎呀!
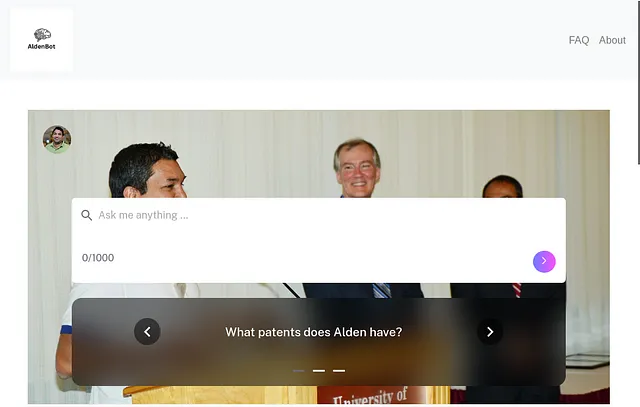
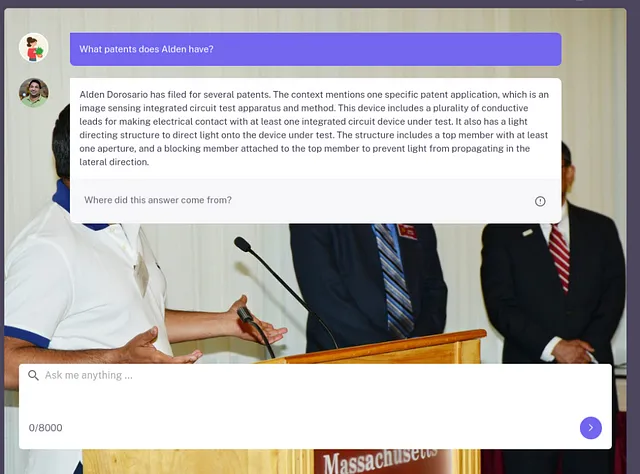
实时演示
您可以在此页面上查看实时演示:https://adorosario.github.io/AldenBot/
忍者小贴士:你甚至可以注册一个新网站,并将聊天机器人嵌入其中,想象一下其中的可能性。
常见问题解答
Q: 使用ChatGPT真的可以复制自己吗?
A: 是的,有了新的ChatGPT GPT构建工具,您可以上传您的文件并创建您的克隆,甚至让它像您一样交谈和行为。
一个不足之处是:ChatGPT GPT构建器只支持上传20个文件。而且不支持基于Web的资产,如网页或网站。所以如果你需要这些,你将需要使用另一个商业无代码构建平台。(请参见上述示例)
Q: 这个聊天机器人会真实地代表我吗?
A: 尽管AI聊天机器人可以模拟您的沟通风格并分享基于其训练数据的知识,但重要的是要记住它仍然是AI,不是您的完全复制品。它没有您的记忆或个人经历,除非这些信息在其训练数据中共享。
Q:在这个过程中我的数据安全吗?
实际上——不行。所以最好只使用公开数据。换句话说:只使用已经公开可得的文件和数据——可能已经被谷歌索引了。
事实上,ChatGPT非常不安全,用户只需给它一些指令,就可以轻松下载所有您的文件。
Q: 我可以选择AI克隆知道哪些信息吗?
A: 是的,AI克隆只会了解它所接受培训的信息。这使得您能够控制其知识和能力的范围。
Q:整个过程需要多长时间?
A: 一旦您积累了数据来源,创建AI克隆的过程只需几分钟。实际所需时间取决于数据的量而有所不同。
问题:我可以使用哪些类型的数据来训练我的 AI 克隆?
A: 你可以使用各种数据源,如网页,谷歌搜索结果,PDF文件,Word文档,社交媒体帖子,视频,播客等。
根据您所使用的无代码建站平台,数据集成和格式会有所不同。
A: 我可以将AI克隆集成到我的网站或其他平台吗?
A:是的,一旦创建完成,您可以选择公开分享您的AI克隆,将其嵌入到您的网站中,或者使用API将其集成到您的系统中。您甚至可以使用Zapier,并基于API创建工作流程,以便将其连接到其他平台和集成。
注意事项:如果您正在使用ChatGPT的GPT构建器,则无法将其嵌入您的网站或使用工作流程。您的用户需要访问chat.openai.com与您的克隆进行交流。
问:AI 克隆能回答新的问题吗,还是只能回答那些基于已输入数据的问题?
A: AI克隆只会根据已索引的数据回答问题,不会产生幻觉。它不会"凭空编造"回答或根据未索引的信息生成回应。确保您选择的聊天机器人构建平台已启用良好的抗幻觉功能。
问题:AI克隆是如何知道如何以我的风格回复的?
A: 所有的GPT构建者都有“自定义指令”,你可以使用它们来模仿你的语调、风格和个性。一个好的选择是使用免费工具来创建你自己的自定义指令。
结论
所以,我们就这样吧。我们只是浅尝辄止了人工智能驱动的无限可能性的表面。我们已经触摸到了使用人工智能克隆自己的想法。一个奇怪的概念?也许是。引人入胜?绝对是的。
将其视为创造一个数字化的双胞胎——一个能够在你睡觉时与世界互动、在你忙碌时分享你的知识、即使你不在场也能保持你的想法的版本,给自己(或你所爱的人)提供服务。
最终,这不仅仅是关于利用人工智能进行自我复制,而是关于我们可以创造的影响 - 对于我们自己和他人而言。在我们继续探索这个新领域的同时,让我们始终记住要负责任、以道德方式使用它,造福所有人。