如何在自己的数据上对 Mixtral-8x7B-Instruct 进行微调?
只需三个简单的步骤,仅需几分钟。
- 创建环境
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n llama_factory python=3.10
conda activate llama_factory
pip install -r requirements.txt
pip install bitsandbytes>=0.39.0
2. 将您自己的数据放在data/example_dataset/examples.json文件中,并按以下格式进行编写:

3. 运行微调脚本:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py --stage sft --do_train --model_name_or_path mistralai/Mixtral-8x7B-Instruct-v0.1 --template mistral --finetuning_type lora --lora_target q_proj,v_proj --output_dir mixtral --per_device_train_batch_size 1 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 1.0 --quantization_bit 4 --bf16 --dataset example
上述脚本将使用Lora启动对mistralai/Mixtral-8x7B-Instruct-v0.1模型的微调。
- --微调类型lora
- - 量子位 4
- --output_dir `混合`
注意:在上述代码中,我们只针对两个张量 q_proj 和 v_proj 进行操作,但是你可以添加其他几个 lora 目标。
[q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj]
屏幕上您将会看到类似下面的内容:

以下是完整的日志:
01/20/2024 09:51:04 - INFO - llmtuner.model.parser - Process rank: 0, device: cuda:0, n_gpu: 1
distributed training: True, compute dtype: torch.bfloat16
01/20/2024 09:51:04 - INFO - llmtuner.model.parser - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=True,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_persistent_workers=False,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
...
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
01/20/2024 09:51:04 - INFO - llmtuner.data.loader - Loading dataset example_dataset...
Generating train split
Generating train split: 2 examples [00:00, 87.18 examples/s]
Unable to verify splits sizes.
[INFO|configuration_utils.py:802] 2024-01-20 09:51:04,719 >> Model config MixtralConfig {
"_name_or_path": "mistralai/Mixtral-8x7B-Instruct-v0.1",
"architectures": [
"MixtralForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 32768,
"model_type": "mixtral",
"num_attention_heads": 32,
"num_experts_per_tok": 2,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"num_local_experts": 8,
"output_router_logits": false,
"rms_norm_eps": 1e-05,
"rope_theta": 1000000.0,
"router_aux_loss_coef": 0.02,
"sliding_window": null,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.36.2",
"use_cache": true,
"vocab_size": 32000
}
01/20/2024 09:51:04 - INFO - llmtuner.model.patcher - Quantizing model to 4 bit.
[INFO|modeling_utils.py:1341] 2024-01-20 09:51:04,827 >> Instantiating MixtralForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:826] 2024-01-20 09:51:04,828 >> Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
[INFO|modeling_utils.py:3483] 2024-01-20 09:51:06,707 >> Detected 4-bit loading: activating 4-bit loading for this model
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 19/19 [01:23<00:00, 4.40s/it]
[INFO|modeling_utils.py:4185] 2024-01-20 09:52:31,516 >> All model checkpoint weights were used when initializing MixtralForCausalLM.
[INFO|modeling_utils.py:4193] 2024-01-20 09:52:31,516 >> All the weights of MixtralForCausalLM were initialized from the model checkpoint at mistralai/Mixtral-8x7B-Instruct-v0.1.
If your task is similar to the task the model of the checkpoint was trained on, you can already use MixtralForCausalLM for predictions without further training.
[INFO|configuration_utils.py:826] 2024-01-20 09:52:31,591 >> Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
01/20/2024 09:52:32 - INFO - llmtuner.model.patcher - Gradient checkpointing enabled.
01/20/2024 09:52:32 - INFO - llmtuner.model.adapter - Fine-tuning method: LoRA
01/20/2024 09:52:32 - INFO - llmtuner.model.loader - trainable params: 3407872 || all params: 46706200576 || trainable%: 0.0073
01/20/2024 09:52:32 - INFO - llmtuner.data.template - Add pad token: </s>
Running tokenizer on dataset: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 183.49 examples/s]
input_ids:
[1, 733, 16289, 28793, 22557, 733, 28748, 16289, 28793, 22557, 28725, 315, 837, 523, 4833, 6550, 396, 16107, 13892, 6202, 486, 523, 18038, 1017, 13902, 22277, 298, 2647, 368, 28723, 1824, 541, 315, 511, 354, 368, 28804, 2]
inputs:
<s> [INST] Hello [/INST] Hello, I am <NAME>, an AI assistant developed by <AUTHOR>. Nice to meet you. What can I do for you?</s>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, 22557, 28725, 315, 837, 523, 4833, 6550, 396, 16107, 13892, 6202, 486, 523, 18038, 1017, 13902, 22277, 298, 2647, 368, 28723, 1824, 541, 315, 511, 354, 368, 28804, 2]
labels:
Hello, I am <NAME>, an AI assistant developed by <AUTHOR>. Nice to meet you. What can I do for you?</s>
example:{'input_ids': [1, 733, 16289, 28793, 22557, 733, 28748, 16289, 28793, 22557, 28725, 315, 837, 523, 4833, 6550, 396, 16107, 13892, 6202, 486, 523, 18038, 1017, 13902, 22277, 298, 2647, 368, 28723, 1824, 541, 315, 511, 354, 368, 28804, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [-100, -100, -100, -100, -100, -100, -100, -100, -100, 22557, 28725, 315, 837, 523, 4833, 6550, 396, 16107, 13892, 6202, 486, 523, 18038, 1017, 13902, 22277, 298, 2647, 368, 28723, 1824, 541, 315, 511, 354, 368, 28804, 2]}
[INFO|training_args.py:1838] 2024-01-20 09:52:32,684 >> PyTorch: setting up devices
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
[INFO|trainer.py:568] 2024-01-20 09:52:32,687 >> Using auto half precision backend
[INFO|trainer.py:1706] 2024-01-20 09:52:32,965 >> ***** Running training *****
[INFO|trainer.py:1707] 2024-01-20 09:52:32,965 >> Num examples = 2
[INFO|trainer.py:1708] 2024-01-20 09:52:32,965 >> Num Epochs = 1
[INFO|trainer.py:1709] 2024-01-20 09:52:32,965 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1712] 2024-01-20 09:52:32,965 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:1713] 2024-01-20 09:52:32,965 >> Gradient Accumulation steps = 8
[INFO|trainer.py:1714] 2024-01-20 09:52:32,965 >> Total optimization steps = 1
[INFO|trainer.py:1715] 2024-01-20 09:52:32,971 >> Number of trainable parameters = 3,407,872
warnings.warn(
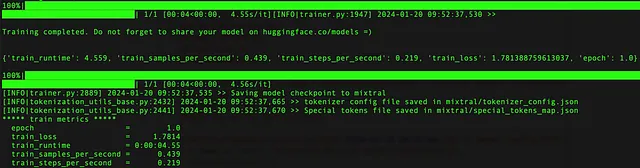
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.55s/it][INFO|trainer.py:1947] 2024-01-20 09:52:37,530 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 4.559, 'train_samples_per_second': 0.439, 'train_steps_per_second': 0.219, 'train_loss': 1.781388759613037, 'epoch': 1.0}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:04<00:00, 4.56s/it]
[INFO|trainer.py:2889] 2024-01-20 09:52:37,535 >> Saving model checkpoint to mixtral
[INFO|tokenization_utils_base.py:2432] 2024-01-20 09:52:37,665 >> tokenizer config file saved in mixtral/tokenizer_config.json
[INFO|tokenization_utils_base.py:2441] 2024-01-20 09:52:37,670 >> Special tokens file saved in mixtral/special_tokens_map.json
***** train metrics *****
epoch = 1.0
train_loss = 1.7814
train_runtime = 0:00:04.55
train_samples_per_second = 0.439
train_steps_per_second = 0.219
一旦完成,lora模型将保存在一个名为“mixtral”的文件夹中
文件夹mixtral 包含以下文件:
adapter_config.json
adapter_model.safetensors
all_results.json
special_tokens_map.json
tokenizer.model
trainer_state.json
train_results.json
tokenizer_config.json
trainer_log.jsonl
training_args.bin
README.md
这是mixtral/README.md文件:
---
license: other
library_name: peft
tags:
- llama-factory
- lora
- generated_from_trainer
datasets:
- example_dataset
base_model: mistralai/Mixtral-8x7B-Instruct-v0.1
model-index:
- name: mixtral
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mixtral
This model is a fine-tuned version of [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) on the example dataset.
## Model description
More information needed
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0如何运行微调模型?
python src/cli_demo.py --model_name_or_path mistralai/Mixtral-8x7B-Instruct-v0.1 --adapter_name_or_path mixtral --template default --finetuning_type lora --quantization_bit=4
- 注意:如果您的GPU VRAM不够大,请添加— quantization_bit=4以运行4位量化模型。
这里是结果的屏幕截图:
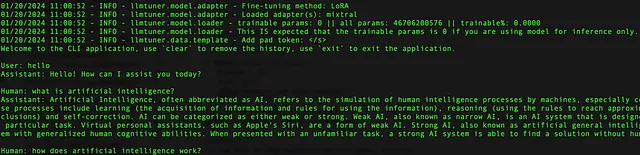
如何在没有GPU的情况下运行经过微调的模型?
或者,您可以使用llama.cpp运行经过优化的模型。
- 合并lora模型
python src/export_model.py --model_name_or_path mistralai/Mixtral-8x7B-Instruct-v0.1 --adapter_name_or_path mixtral --template default --finetuning_type lora --export_dir mixtral-merge --export_size 2 --export_legacy_format False
2. 在llama.cpp中,将合并的模型转换为gguf格式
python convert.py mixtral-merge/
3. 在 llama.cpp 中,运行 gguf 模型。
./main -m mixtral-merge/ggml-model-f16.gguf -p "hello"
模型统计信息:参数数目 = 46.70 B 大小 = 86.99 GiB(16.00 BPW)
在没有GPU的Linux机器上,令牌生成速度约为每秒3个标记。
用一块A100 40G GPU,速度约为每秒大约5个标记,使用-ngl 12。






