LLMs(如ChatGPT)将如何重塑数据科学学习和职业?
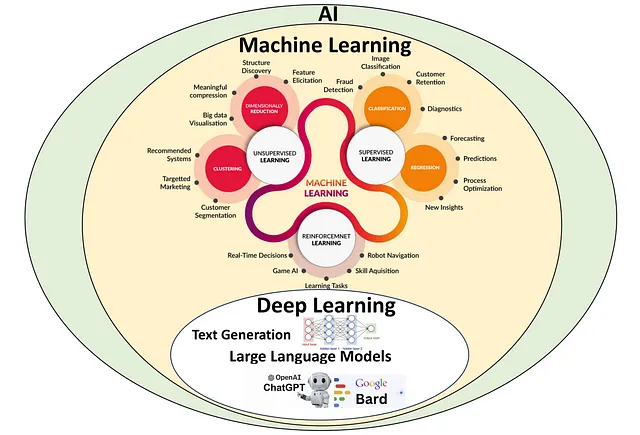
大型语言模型(LLMs)和ChatGPT的出现为数据科学职业带来了一个引人入胜的拐点。虽然一些人担心这些强大的工具将使编程技能变得过时,但仔细观察会发现一个更加细致的未来,技术专长和人类理解相互补充。这些先进的人工智能技术不仅正在改变我们与机器互动的方式,也正在革新数据科学技能的学习和应用方式。在这个卓越创新的时代,传统的数据科学学习方法正在重新定义,为更具活力和沉浸式的教育体验铺平道路。深度学习(DL)是我们今天看到的LLMs中发展起来的一个子领域,属于机器学习(ML)的子集。而机器学习则是人工智能(AI)的一个子集。如今广泛认可的LLMs是通过深度学习(DL)技术精心打造的复杂模型。这些模型展示了广泛理解和生成人类语言的能力,正如OpenAI的ChatGPT和Google Bard(参见图1)所展示的那样。
大型语言模型可以理解并适应个人学习风格。通过利用这项技术,学习数据科学可以变得更加个性化,满足个人和组织的独特需求和偏好。这些模型可以分析用户学习行为的模式,推荐个性化资源,并提供有针对性的反馈,最终促进更高效和定制化的学习体验。像ChatGPT这样的LLM在自然语言处理(NLP)方面的能力为NLP培训开辟了新的途径,这是数据科学中至关重要的组成部分。ChatGPT等LLM的协作性质为用户创造了互动和协作学习环境的可能性。
在这个时代,没有编码专业知识的个人(即不懂得如Python、R、Java、C++等编程语言编写算法的能力)可以通过提示工程无缝地将任务分配给ChatGPT。这给传统数据科学家带来了重大挑战,引发了对未来机器可能取代他们角色的担忧,这种情况正在成为现实。LLM确实可以根据请求执行数据科学任务,如代码生成。这可能会产生编码技能是可有可无的错觉。然而,关键问题出现了,例如:
- 不需要编程领域知识,是否可以有效地解释和调试LLM的输出?
- 能ChatGPT和其他LLM真正理解您特定问题的细微差别,并相应地调整代码吗?
- 由于LLMs自身依赖于复杂的代码进行训练和优化,那些没有编码流畅度的人将建立和维护这些关键系统吗?
专家们面临着几个重大挑战,比如人工智能的伦理使用、消除偏见,并在人工智能驱动和传统学习方法之间找到一种和谐的平衡。这些问题和挑战意味着与常规规范的背离,为一代新的数据科学家铺平了道路,他们的角色在LLM技术时代将变得越来越不可或缺。
解读性数据科学家的崛起
虽然LLMs可以自动化常规编码任务,但数据科学将越来越多地向人类转变,作为解释者和战略家与LLMs技术协作工作。解释性数据科学家协助LLMs的用户通过他们的研究问题、假设、扭臀提示、发现偏见和道德问题来构建建设性的提示(见图2)。
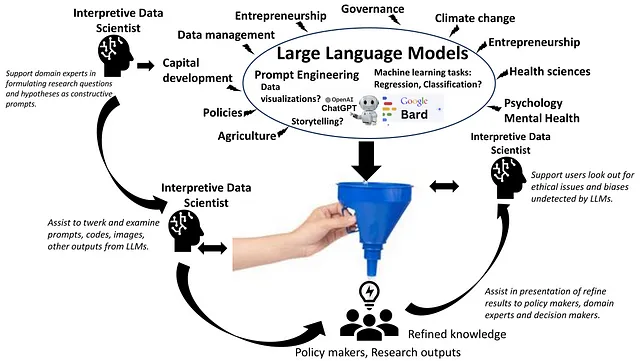
熟练的数据科学家将在将LLM的输出转化为可解释的见解方面起到关键作用,确保模型的可信度和责任感。LLM通常难以处理领域特定的复杂问题。具有对问题领域深刻理解的数据科学家对指导LLM的应用和改进其结果至关重要。数据科学家将组织设计和监督LLM驱动的管道,例如在更广泛的分析框架中LLM处理具体任务的复杂工作流程。但是,所有这些解决方案都不够,因为解决这些问题没有一种适合所有情况的方法。然而,发展其他值得注意的技能并与领域专家合作,以了解他们的需求,可能在推进数据科学学习方面起到关键作用。
软技能成为超能力
除了技术专长之外,LLM强调软技能在数据科学中的日益重要性。例如,发展有效的沟通和讲故事的能力。有效地将复杂的数据洞察力传达给不同的受众,将是最大化LLM生成结果影响力的关键。此外,批判性思维和解决问题的能力是开发LLM可能自动化任务的建设性提示所必需的。虽然人类仍然需要定义问题、解释结果,并基于洞见做出明智决策。合作和团队合作是与LLM合作时的关键,因为当它们融入人类主导的团队中时,不同的观点和专业知识将协同解决复杂的数据挑战。
结论
LLM(语言模型)的目的并非取代数据科学家,而是转变他们的角色和技能集。未来的数据科学家将是技术专长、领域知识和强大软技能的综合体。LLM将处理自动化的繁重工作,使人类能够专注于数据科学的真正战略性方面:解释、理解和问题解决。在LLM时代,应拥抱这个不断演变的领域,培养技术与软技能将对数据科学家的发展至关重要。
建设性的批评值得思考
- 可以通过使洞见对非技术人员可访问,LLMs能够使数据科学民主化吗?
- 我们如何确保在数据科学中道德和负责任地使用LLMs,以避免偏见和滥用的发生?
- LLM能力与人类理解力之间的差距是否会带来新的挑战和伦理困境?
以下是在数据科学这一令人兴奋的新篇章中值得思考的几个问题。关键的观点是将LLMs视为合作伙伴而不是竞争对手,并以好奇心、批判思维和持续学习的心态拥抱不断发展的领域。
在我结束这次讨论时,我希望它能够为在LLM时代的数据科学职业的未来提供令人深思的视角。