评估Cypher语句生成中的LLMs
评估生成的Cypher语句准确性的逐步教程

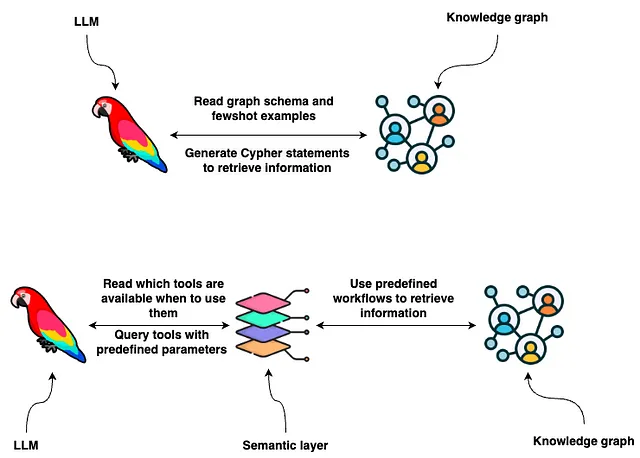
随着大型语言模型(LLMs)的普及,我们意识到它们对将自然语言翻译为SQL和Cypher等数据库查询方面表现不错。为了使LLM能够为您的特定数据库创建定制查询,您必须提供其模式和可选的一些示例查询。有了这些信息,LLM可以根据自然语言输入生成数据库查询。
虽然 LLM 在将自然语言翻译成数据库查询方面显示出很大的潜力,但它们还远未完美。因此,了解它们的表现如何,通过评估过程至关重要。幸运的是,生成 SQL 语句的过程已经在像 Spider 这样的学术研究中进行了研究。我们将使用以下指标评估 LLM 的 Cypher 生成能力。
- Jaro-Winkler: 这是一种基于编辑距离的文本相似度度量方法。我们将生成的Cypher查询与正确的Cypher查询进行比较,并通过编辑一个查询使其与另一个查询相同的程度来衡量字符串的差异。
- 通过@1:如果生成的查询结果与正确的Cypher查询从数据库返回相同的结果,则得分为1.0,否则得分为0.0。
- Pass@3: 与Pass@1相似,但是我们生成3个查询,如果其中任何一个与正确查询的结果相同,得分为1.0,否则得分为0.0。
- 雅卡尔相似度:它衡量了生成的Cypher返回结果与正确Cypher返回结果之间的雅卡尔相似度。该指标用于捕捉模型可能返回几乎正确结果的示例。
代码可在GitHub上找到,并与Adam Schill Collberg合作开发。
正如您所看到的,焦点是评估来自数据库的响应,而不是实际的Cypher语句本身。一个原因是Cypher语句可以以多种方式编写来检索相同的信息。我们不关心LLM更喜欢哪种语法;我们只关心它能产生正确的响应。此外,我们对LLM在响应中命名列的能力没有明确的偏好,因此,我们不希望评估它的列命名能力等等。
测试数据集
测试数据集包含问题和相应的Cypher语句对。
您可以使用LLM生成对于测试数据集的建议。然而,您需要手动验证示例,因为LLM会出错,不是100%可靠的。如果它们可靠,我们就不需要测试它们了。因为我们是基于数据库结果而不是Cypher语句本身进行评估,所以我们需要一个运行中的数据库,其中包含相关信息可以供我们使用。在本博客文章中,我们将使用Neo4j Sandbox中的推荐项目。该推荐项目使用MovieLens数据集,其中包含电影、演员、评分和其他信息。该推荐项目也可以作为演示服务器上的只读访问,这意味着如果您不想创建新的数据库实例,您就不需要这样做。
在这个例子中,我使用GPT-4来提出训练数据集的建议,然后对其中需要更正的进行了修正。我们将使用只有27个测试对。在实践中,你可能希望使用至少几百个示例。
data = [
{
"question": "How many movies were released in 1995?",
"cypher": "MATCH (m:Movie) WHERE m.Year = 1995 RETURN count(*) AS result",
},
{
"question": "Who directed the movie Inception?",
"cypher": "MATCH (m:Movie {title: 'Inception'})<-[:DIRECTED]-(d) RETURN d.name",
},
{
"question": "Which actors played in the movie Casino?",
"cypher": "MATCH (m:Movie {title: 'Casino'})<-[:ACTED_IN]-(a) RETURN a.name",
},
{
"question": "How many movies has Tom Hanks acted in?",
"cypher": "MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)",
},
{
"question": "List all the genres of the movie Schindler's List",
"cypher": "MATCH (m:Movie {title: 'Schindler\\'s List'})-[:IN_GENRE]->(g:Genre) RETURN g.name",
},
...
]
生成Cypher语句
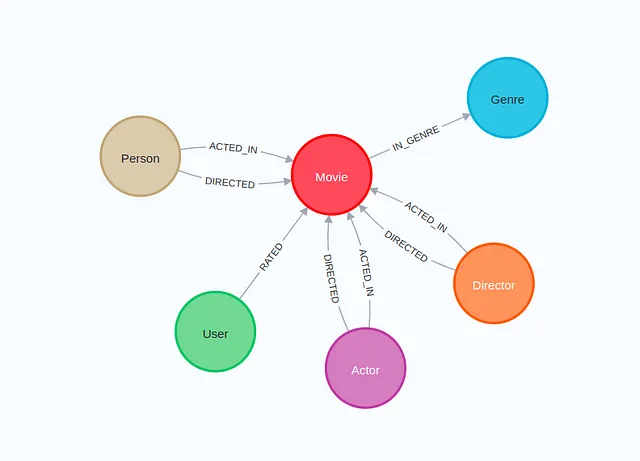
我们将使用LangChain来生成Cypher语句。LangChain中的Neo4jGraph对象建立与Neo4j的连接并检索其模式信息。
graph = Neo4jGraph()
print(graph.schema)
# Node properties are the following:
# Movie {posterEmbedding: LIST, url: STRING, runtime: INTEGER, revenue: INTEGER, budget: INTEGER, plotEmbedding: LIST, imdbRating: FLOAT, released: STRING, countries: LIST, languages: LIST, plot: STRING, imdbVotes: INTEGER, imdbId: STRING, year: INTEGER, poster: STRING, movieId: STRING, tmdbId: STRING, title: STRING}
# Genre {name: STRING}
# User {userId: STRING, name: STRING}
# Actor {url: STRING, bornIn: STRING, bio: STRING, died: DATE, born: DATE, imdbId: STRING, name: STRING, poster: STRING, tmdbId: STRING}
# Director {url: STRING, bornIn: STRING, born: DATE, died: DATE, tmdbId: STRING, imdbId: STRING, name: STRING, poster: STRING, bio: STRING}
# Person {url: STRING, bornIn: STRING, bio: STRING, died: DATE, born: DATE, imdbId: STRING, name: STRING, poster: STRING, tmdbId: STRING}
# Relationship properties are the following:
# RATED {rating: FLOAT, timestamp: INTEGER}
# ACTED_IN {role: STRING}
# DIRECTED {role: STRING}
# The relationships are the following:
# (:Movie)-[:IN_GENRE]->(:Genre)
# (:User)-[:RATED]->(:Movie)
# (:Actor)-[:ACTED_IN]->(:Movie)
# (:Actor)-[:DIRECTED]->(:Movie)
# (:Director)-[:DIRECTED]->(:Movie)
# (:Director)-[:ACTED_IN]->(:Movie)
# (:Person)-[:ACTED_IN]->(:Movie)
# (:Person)-[:DIRECTED]->(:Movie)
该模式包含节点标签、它们的属性以及相应的关系。接下来,我们将使用LangChain表达式语言来定义一个提示,发送给LLM,包含将自然语言翻译为Cypher语句的指令,以检索相关信息来回答问题。请访问官方文档以了解更多关于LangChain表达式语言的详细信息。
cypher_template = """Based on the Neo4j graph schema below,
write a Cypher query that would answer the user's question.
Return only Cypher statement, no backticks, nothing else.
{schema}
Question: {question}
Cypher query:""" # noqa: E501
cypher_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input question, convert it to a Cypher query. No pre-amble.",
),
("human", cypher_template),
]
)
cypher_chain = (
RunnablePassthrough.assign(
schema=lambda _: graph.get_schema,
)
| cypher_prompt
| llm.bind(stop=["\nCypherResult:"])
| StrOutputParser()
)
如果你熟悉对话型LLM,你可以识别出系统和人类消息的定义。正如你所观察到的,我们将图谱模式和用户问题都放在人类消息中。准确的提示工程指令来生成Cypher语句并不是一个解决的问题,这意味着这里可能有一些改进的空间。通过评估过程,你可以找出最适合特定LLM的方法。在这个例子中,我们使用的是gpt-4-turbo。
我们可以使用以下示例来测试密码生成。
response = cypher_chain.invoke(
{
"question": "How many movies have the keyword 'love' in the title and a runtime under 2 hours?"
}
)
print(response)
# MATCH (m:Movie)
# WHERE m.title CONTAINS 'love' AND m.runtime < 120
# RETURN count(m) as NumberOfMovies
我们可以观察到gpt-4-turbo在将自然语言翻译成Cypher语句方面具有一定的能力。现在我们来定义评估过程。
# Iterate over each row with tqdm to show a progress bar
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
# Fetch data based on the test Cypher statement
true_data = graph.query(row["cypher"])
# Generate 3 Cypher statement and fetch data
example_generated_cyphers = []
example_eval_datas = []
for _ in range(3):
cypher = cypher_chain.invoke({"question": row["question"]})
example_generated_cyphers.append(cypher)
# Fetch data based on the generated Cypher statement
try:
example_eval_datas.append(graph.query(cypher))
except ValueError: # Handle syntax error
example_eval_datas.append([{"id": "Cypher syntax error"}])
# These metrics require only the first cypher/response
jaro_winkler = get_jw_distance(row["cypher"], example_generated_cyphers[0])
pass_1 = (
1
if df_sim_pair(
(row["cypher"], true_data),
(example_generated_cyphers[0], example_eval_datas[0]),
)
== 1
else 0
)
jaccard = df_sim_pair(
(row["cypher"], true_data),
(example_generated_cyphers[0], example_eval_datas[0]),
)
# Pass@3 check all 3 responses
pass_3 = 1 if any(
df_sim_pair((row["cypher"], true_data), (gen_cypher, eval_data)) == 1
for gen_cypher, eval_data in zip(example_generated_cyphers, example_eval_datas)
) else 0
# Append the results to their respective lists
generated_cyphers.append(example_generated_cyphers)
true_datas.append(true_data)
eval_datas.append(example_eval_datas)
jaro_winklers.append(jaro_winkler)
pass_1s.append(pass_1)
pass_3s.append(pass_3)
jaccards.append(jaccard)
运行代码大约需要5分钟,因为我们需要生成81个响应来计算3关键字的通过率指标。
代码有点长。然而,主要内容非常容易理解。我们遍历存储测试样例的数据框中的所有行。接下来,我们为每个训练样例生成三个Cypher查询,并从数据库中检索相应的数据。然后,我们计算相关指标并将它们存储在列表中,以便进行评估和可视化。我们在博客文章中没有包括辅助函数,因为我认为审查每个度量代码实现并不相关。然而,所有这些函数都包含在笔记本中。
现在让我们评估结果。
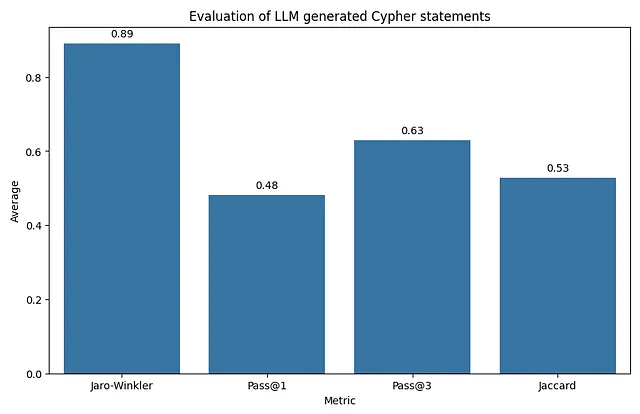
评估基于四个不同的指标:
- Jaro-Winkler:此度量显示平均值为0.89,表明LLMs生成的Cypher查询在字符串级别上与正确的Cypher查询非常相似。
- Pass @ 1:这里的平均分数为0.48,这意味着当每个查询独立评估时,近一半生成的Cypher查询结果与正确查询完全相同。
- Pass@3:平均值为0.63,该指标显示相比于Pass@1有所改善。这表明虽然在第一次尝试中LLM可能不能总是准确回答查询,但通常在三次尝试内能提供正确的版本。
- Jaccard相似度:平均得分0.53是所有指标中最低的,但仍表明超过一半的时间,从LLM生成的Cypher查询结果集与正确查询结果集共享超过一半的元素。
总体而言,这些指标表明LLM在生成与正确查询相似且往往产生功能等效的Cypher查询方面表现尚可,尤其是在多次尝试的情况下。然而,在首次尝试中生成正确的查询仍有改进的空间。此外,在评估过程中也有改进的空间。让我们看一个例子:
row = df.iloc[24]
# Print the desired information
print("Question:", row["question"], "\n")
print("True Cypher:", row["cypher"], "\n")
print("Generated Cypher", row["generated_cypher"][0], "\n")
# Question: Which directors have never had a movie with a rating below 6.0?
# True Cypher:
# MATCH (d:Director)-[:DIRECTED]->(m:Movie)
# WITH d, MIN(m.imdbRating) AS lowestRating WHERE lowestRating >= 6.0
# RETURN d.name, lowestRating
# Generated Cypher
# MATCH (d:Director)-[:DIRECTED]->(m:Movie)
# WHERE NOT EXISTS {
# MATCH (d)-[:DIRECTED]->(m2:Movie)
# WHERE m2.imdbRating < 6.0
# }
# RETURN DISTINCT d.name
对于哪些导演从未拍摄过评分低于6.0的电影的问题,LLM在获取结果方面做得不错。它使用了与测试数据集不同的方法,但这并不是个问题,因为它应该能得到相同的结果。然而,在测试数据中我们将标题和电影评分都返回了。另一方面,LLM只提供了标题而没有评分。我们不能责怪它,因为它只是简单地按照指示操作。不过,你必须知道,在这个例子中,pass@1得分为0,而Jaccard相似度仅为0.5。因此,你必须非常谨慎地构建测试数据集,包括如何定义提示以及相应的Cypher语句。
LLMs的另一个特点是它们是非确定性的,这意味着每次运行都可能得到不同的结果。现在让我们连续运行评估三次。这个评估大约需要15分钟。
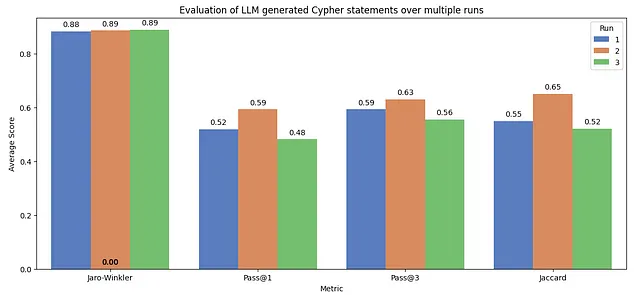
柱状图突出了LLMs的非确定性特性。Jaro-Winkler分数在所有运行中始终保持较高水平,在0.88和0.89之间波动,这表明生成的查询具有稳定的字符串相似度。然而,在Pass@1中,存在明显的变化,第一次运行得分为0.52,后续运行得分为0.59和0.48。Pass@3得分的差异较小,大约在0.56到0.63之间,表明多次尝试能够产生更一致的正确结果。
总结
通过这篇博客文章,我们了解到像GPT-4这样的LLMs在生成Cypher查询方面具有很大的潜力,但这项技术并非完美无缺。所提出的评估框架提供了对LLM性能的详细定量评估,使您能够不断尝试和更新提示工程和其他生成有效和准确Cypher语句所需的步骤。此外,它还展示了LLMs的非确定性特性如何影响从一个评估到另一个评估的性能。因此,您可以期望在生产中出现类似的非确定性行为。
代码可以在GitHub上找到。
数据集
F. Maxwell Harper和Joseph A. Konstan。2015年。MovieLens数据集:历史与背景。ACM交互智能系统(TiiS)5,4:19:1–19:19。https://doi.org/10.1145/2827872