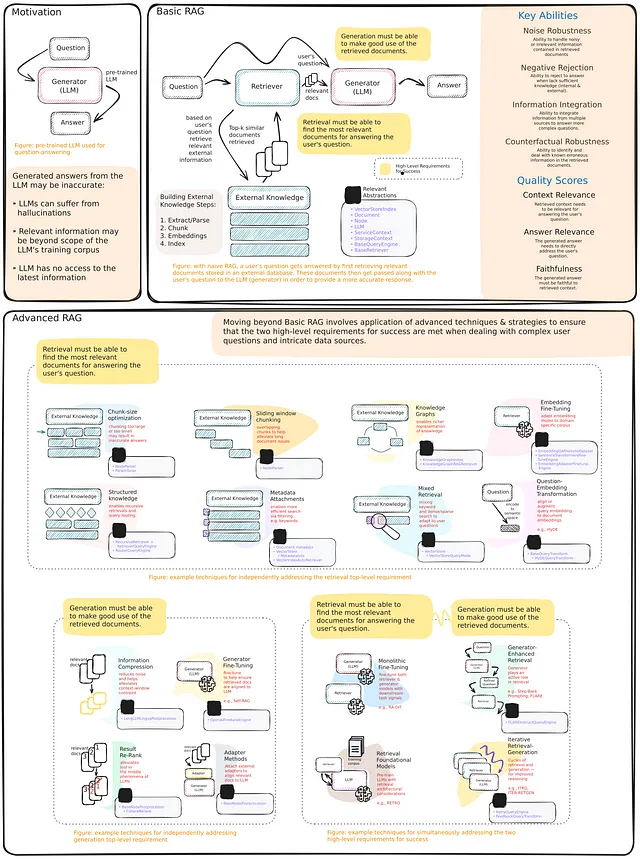
通过语义层增强语言模型和图数据库之间的交互
提供一套强大的工具,供LLM代理使用与图形数据库进行交互
知识图谱以灵活的数据模式提供了对结构化和非结构化信息进行存储的良好表示。您可以使用Cypher语句从Neo4j这样的图数据库中检索信息。其中一种选择是使用LLMs生成Cypher语句。虽然这种选择提供了出色的灵活性,但事实上,基本LLMs在始终生成精确的Cypher语句方面还是有些脆弱。因此,我们需要寻求一种替代方案,以确保一致性和健壮性。那么,如果LLM不是开发Cypher语句,而是从用户输入中提取参数,并根据用户意图使用预定义函数或基于Cypher模板的方式呢?简而言之,您可以为LLM提供一套预定义的工具和指示,告诉它何时以及如何根据用户输入使用这些工具,也就是所谓的语义层。
一个语义层由多种工具组成,这些工具对LLM(语义层管理器)可用,以便与知识图进行交互。它们可以具有不同的复杂性。您可以将语义层中的每个工具视为一个函数。例如,请查看以下函数。
def get_information(entity: str, type: str) -> str:
candidates = get_candidates(entity, type)
if not candidates:
return "No information was found about the movie or person in the database"
elif len(candidates) > 1:
newline = "\n"
return (
"Need additional information, which of these "
f"did you mean: {newline + newline.join(str(d) for d in candidates)}"
)
data = graph.query(
description_query, params={"candidate": candidates[0]["candidate"]}
)
return data[0]["context"]
工具可以具有多个输入参数,就像上面的例子一样,这样您可以实现复杂的工具。此外,工作流可以包括多个数据库查询,使您能够根据需要处理任何边缘情况或异常。优点是您将可能在大多数情况下起作用的即兴工程问题转化为每次都按照脚本准确执行的代码工程问题。
电影代理商
在这篇博文中,我们将展示如何实现一个语义层,使得一个LLM代理可以与一个包含有关演员、电影和评级信息的知识图进行交互。
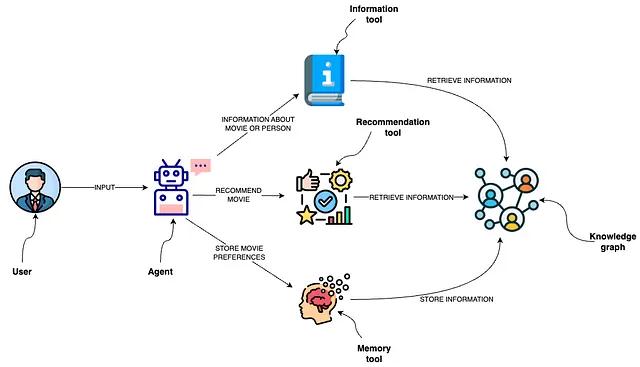
取自文档(也由我编写):
代理使用多种工具与Neo4j图数据库进行有效的交互。
* 信息工具:检索电影或个人的数据,确保代理人可以获得最新和最相关的信息。
* 推荐工具:根据用户的偏好和输入提供电影推荐。
* 记忆工具:将用户偏好信息存储在知识图谱中,从而实现在多次互动中个性化的体验。
代理人可以使用信息或推荐工具从数据库中检索信息,或者使用记忆工具将用户偏好存储在数据库中。预定义的功能和工具使代理人能够策划复杂的用户体验,引导个体朝特定目标前进,或提供与用户当前旅程中的位置相符的定制信息。这种预定义的方法增强了系统的稳健性,通过减少LLM的艺术自由,确保回复更加结构化和与预定的用户流程相符,从而改善整体用户体验。
电影代理的语义层后端已被实现并可作为LangChain模板使用。我已使用该模板构建了一个简单的streamlit聊天应用程序。
代码可在GitHub上获取。您可以通过定义环境变量并执行以下命令来启动项目:
docker-compose up
图模型
这个图表基于MovieLens数据集。它包含有关演员、电影和100k用户对电影的评分的信息。
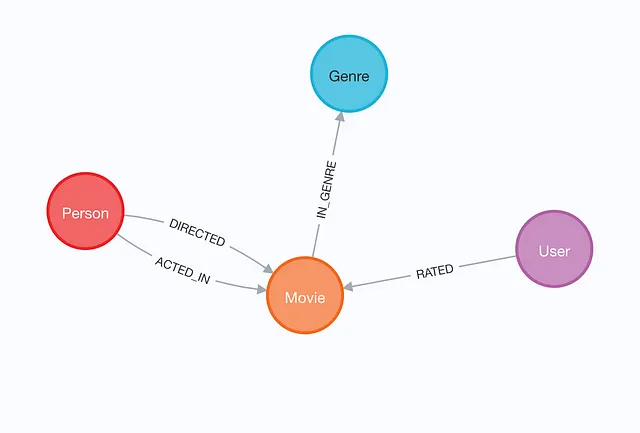
可视化展示了一个知识图谱,包含了参演或导演过电影的个人,并按照电影的类型进行了分类。每个电影节点都包含了它的上映日期、标题和IMDb评分的信息。该图谱还包含了用户评分,我们可以利用这些评分提供推荐。
您可以通过执行位于文件夹的根目录中的ingest.py脚本来填充图形。
定义工具
现在,我们将定义代理可以用来与知识图谱进行交互的工具。我们从信息工具开始。信息工具旨在获取有关演员、导演和电影的相关信息。Python 代码如下所示:
def get_information(entity: str, type: str) -> str:
# Use full text index to find relevant movies or people
candidates = get_candidates(entity, type)
if not candidates:
return "No information was found about the movie or person in the database"
elif len(candidates) > 1:
newline = "\n"
return (
"Need additional information, which of these "
f"did you mean: {newline + newline.join(str(d) for d in candidates)}"
)
data = graph.query(
description_query, params={"candidate": candidates[0]["candidate"]}
)
return data[0]["context"]
print(get_information("John", "person"))
# Need additional information, which of these did you mean:
# {'candidate': 'John Lodge', 'label': 'Person'}
# {'candidate': 'John Warren', 'label': 'Person'}
# {'candidate': 'John Gray', 'label': 'Person'}
在这种情况下,工具通知代理需要额外的信息。通过简单的提示工程,我们可以引导代理向用户提出后续问题。假设用户提供的信息足够具体,使工具能够识别特定的电影或人物。在这种情况下,我们使用参数化的Cypher语句检索相关信息。
print(get_information("Keanu Reeves", "person"))
# type:Actor
# title: Keanu Reeves
# year:
# ACTED_IN: Matrix Reloaded, The, Side by Side, Matrix Revolutions, The, Sweet November, Replacements, The, Hardball, Matrix, The, Constantine, Bill & Ted's Bogus Journey, Street Kings, Lake House, The, Chain Reaction, Walk in the Clouds, A, Little Buddha, Bill & Ted's Excellent Adventure, The Devil's Advocate, Johnny Mnemonic, Speed, Feeling Minnesota, The Neon Demon, 47 Ronin, Henry's Crime, Day the Earth Stood Still, The, John Wick, River's Edge, Man of Tai Chi, Dracula (Bram Stoker's Dracula), Point Break, My Own Private Idaho, Scanner Darkly, A, Something's Gotta Give, Watcher, The, Gift, The
# DIRECTED: Man of Tai Chi
有了这些信息,代理人可以回答大部分与基努·里维斯有关的问题。
现在,让我们来指导代理人如何有效地利用这个工具。幸运的是,使用LangChain,这个过程是简单而高效的。首先,我们使用一个Pydantic对象来定义函数的输入参数。
class InformationInput(BaseModel):
entity: str = Field(description="movie or a person mentioned in the question")
entity_type: str = Field(
description="type of the entity. Available options are 'movie' or 'person'"
)
在这里,我们描述了entity和entity_type参数都是字符串。entity参数输入被定义为问题中提到的电影或人物。另一方面,对于entity_type,我们还提供可用选项。当处理低基数时,也就是当存在小数量的不同值时,我们可以直接向LLM提供可用选项,以便它可以使用有效的输入。正如我们之前所看到的,我们使用全文索引来消除电影或人物的歧义,因为直接在提示中提供太多值。
现在让我们将所有内容整合在一个信息工具定义中。
class InformationTool(BaseTool):
name = "Information"
description = (
"useful for when you need to answer questions about various actors or movies"
)
args_schema: Type[BaseModel] = InformationInput
def _run(
self,
entity: str,
entity_type: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return get_information(entity, entity_type)
准确和简明的工具定义是语义层的重要组成部分,使得代理能够在需要时正确选择相关工具。
推荐工具稍微复杂一些。
def recommend_movie(movie: Optional[str] = None, genre: Optional[str] = None) -> str:
"""
Recommends movies based on user's history and preference
for a specific movie and/or genre.
Returns:
str: A string containing a list of recommended movies, or an error message.
"""
user_id = get_user_id()
params = {"user_id": user_id, "genre": genre}
if not movie and not genre:
# Try to recommend a movie based on the information in the db
response = graph.query(recommendation_query_db_history, params)
try:
return ", ".join([el["movie"] for el in response])
except Exception:
return "Can you tell us about some of the movies you liked?"
if not movie and genre:
# Recommend top voted movies in the genre the user haven't seen before
response = graph.query(recommendation_query_genre, params)
try:
return ", ".join([el["movie"] for el in response])
except Exception:
return "Something went wrong"
candidates = get_candidates(movie, "movie")
if not candidates:
return "The movie you mentioned wasn't found in the database"
params["movieTitles"] = [el["candidate"] for el in candidates]
query = recommendation_query_movie(bool(genre))
response = graph.query(query, params)
try:
return ", ".join([el["movie"] for el in response])
except Exception:
return "Something went wrong"
第一件需要注意的事情是,两个输入参数都是可选的。因此,我们需要引入处理所有可能的输入参数组合以及缺少它们的工作流程。为了生成个性化的推荐,我们首先获取一个 user_id,然后将其传递到下游的Cypher推荐语句中。
与之前类似,我们需要将函数的输入呈现给代理。
class RecommenderInput(BaseModel):
movie: Optional[str] = Field(description="movie used for recommendation")
genre: Optional[str] = Field(
description=(
"genre used for recommendation. Available options are:" f"{all_genres}"
)
)
由于只有20个可用的类型存在,我们将它们的值作为提示的一部分提供。为了进行电影消歧义,我们再次在函数内使用全文索引。与之前一样,我们最后使用工具定义来通知LLM何时使用它。
class RecommenderTool(BaseTool):
name = "Recommender"
description = "useful for when you need to recommend a movie"
args_schema: Type[BaseModel] = RecommenderInput
def _run(
self,
movie: Optional[str] = None,
genre: Optional[str] = None,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return recommend_movie(movie, genre)
到目前为止,我们已经定义了两个从数据库中检索数据的工具。然而,信息流不一定是单向的。例如,当用户告知代理人他们已经观看过一部电影并可能喜欢它时,我们可以将这些信息存储在数据库中,并在进一步的推荐中使用。这就是记忆工具派上用场的地方。
def store_movie_rating(movie: str, rating: int):
user_id = get_user_id()
candidates = get_candidates(movie, "movie")
if not candidates:
return "This movie is not in our database"
response = graph.query(
store_rating_query,
params={"user_id": user_id, "candidates": candidates, "rating": rating},
)
try:
return response[0]["response"]
except Exception as e:
print(e)
return "Something went wrong"
class MemoryInput(BaseModel):
movie: str = Field(description="movie the user liked")
rating: int = Field(
description=(
"Rating from 1 to 5, where one represents heavy dislike "
"and 5 represent the user loved the movie"
)
)
记忆工具有两个必填的输入参数,用来定义电影及其评分。这是一个简单直接的工具。但需要提及的一点是,在我的测试中我注意到,最好提供一些示例,说明何时给出特定的评分,因为预设情况下,该工具的准确度可能不是最高的。
代理商
让我们现在使用LangChain表达式语言(LCEL)将其全部结合起来,来定义一个代理。
llm = ChatOpenAI(temperature=0, model="gpt-4", streaming=True)
tools = [InformationTool(), RecommenderTool(), MemoryTool()]
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that finds information about movies "
" and recommends them. If tools require follow up questions, "
"make sure to ask the user for clarification. Make sure to include any "
"available options that need to be clarified in the follow up questions "
"Do only the things the user specifically requested. ",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = (
{
"input": lambda x: x["input"],
"chat_history": lambda x: _format_chat_history(x["chat_history"])
if x.get("chat_history")
else [],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True).with_types(
input_type=AgentInput, output_type=Output
)
LangChain 表达式语言使定义代理和暴露其所有功能变得非常方便。我们不会详述 LCEL 语法,因为这超出了本博文的范围。
电影代理后端使用LangServe公开作为API端点。
Streamlit聊天应用
现在我们只需要实现一个与LangServe API端点连接的streamlit应用程序,然后我们就可以开始了。我们只需要查看用于获取代理人回复的异步函数即可。
async def get_agent_response(
input: str, stream_handler: StreamHandler, chat_history: Optional[List[Tuple]] = []
):
url = "http://api:8080/movie-agent/"
st.session_state["generated"].append("")
remote_runnable = RemoteRunnable(url)
async for chunk in remote_runnable.astream_log(
{"input": input, "chat_history": chat_history}
):
log_entry = chunk.ops[0]
value = log_entry.get("value")
if isinstance(value, dict) and isinstance(value.get("steps"), list):
for step in value.get("steps"):
stream_handler.new_status(step["action"].log.strip("\n"))
elif isinstance(value, str):
st.session_state["generated"][-1] += value
stream_handler.new_token(value)
函数get_agent_response的设计目的是与电影智能助理API进行交互。它会发送包含用户输入和聊天历史的请求给API,然后异步处理响应。该函数处理不同类型的响应,通过更新流处理程序的新状态并将生成的文本附加到会话状态中,使我们能够将结果实时发送给用户。
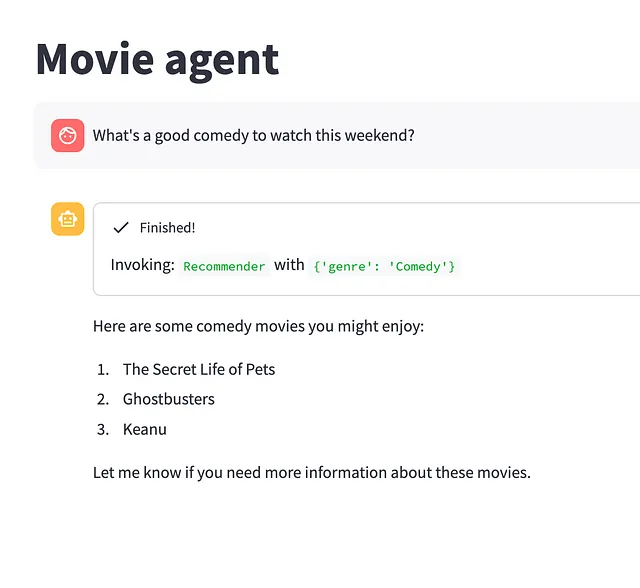
让我们现在来测试一下

最终生成的电影代理人能够与用户进行令人惊喜的良好引导交互。
结论
总之,通过在语言模型与图数据库交互中加入语义层,如我们的电影代理所示,可以显著提升用户体验和数据交互效率。通过将重点从生成任意的Cypher语句转变为利用结构化、预定义的工具和函数套件,语义层为语言模型的交互带来了新的精确性和一致性水平。这种方法不仅简化了从知识图谱中提取相关信息的过程,而且确保了更加目标导向和用户中心的体验。
语义层作为桥梁发挥作用,将用户意图转化为具体的可执行查询,以便语言模型能够准确可靠地执行。因此,用户不仅可以更有效地理解他们的查询,还可以更轻松地实现他们所期望的结果,并避免歧义。此外,通过将语言模型的响应限制在这些预定义工具的参数内,我们可以减轻错误或不相关输出的风险,从而提高系统的可信度和可靠性。
代码可以在 GitHub 上找到。
数据集
F. Maxwell Harper和Joseph A. Konstan。2015年。“MovieLens数据集:历史与背景。” ACM交互智能系统(TiiS)5,4:19:1-19:19. https://doi.org/10.1145/2827872