RAG挑战数据集I — 高级RAG能否击败神经数据库的在线调优?
市场正逐渐意识到现有的用于构建AI聊天机器人的RAG技术栈无法满足商业期望。有许多推荐方案在流传,并且每天都有新的想法冒出来。高级RAG是一个相当复杂的系统,有太多组件和相关的调节开关,现在是被推荐的解决方案。调节高级RAG中的开关对于任何给定的用例都需要专业团队进行,这使得解决方案无法复制。
在线调优 — 为何需要以及与微调的区别
微调是更新嵌入模型以使其适应特定用途的过程。模型更新在建立向量索引之前离线进行。值得注意的是,如果概念发生变化或发现新的关联,例如“流感”与“新冠”之间有密切关联,您需要更新嵌入模型。不幸的是,对嵌入模型的任何更新都需要重新构建向量数据库。现有语义搜索生态系统的希望是,概念漂移很少发生,而且使用手工定制的高级RAG组件可以克服使用过时模型的缺点。
有一些无需嵌入的“学习索引”技术,例如NeuralDB [链接],可以在线进行端到端神经索引的调整,并且该模型能够推断并跟上生产使用中的概念漂变。我们将这种能力称为根据使用驱动的概念漂变进行在线调整的能力。目前,NeuralDB是唯一具备这种能力的商业库。
在神经搜索的背景下,微调和在线调整的区别如下图所示:
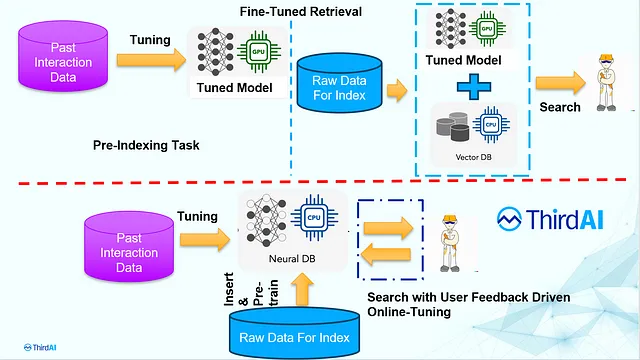
在线调试有两个主要优势:
- 声明一:在线调优结果在很大程度上提高了准确性,因为能够持续地适应用户行为。
- 声明2—在线调整是一种在不同领域和用例中可重复使用的神经搜索解决方案。它不需要任何特定应用的旋钮来实现准确性提升。
下面,我们提供可以验证的证据和案例研究来支持上述两个观点:我们正在发布一份实际的亚马逊产品搜索案例研究,使用的是公开可用的数据集。此外,我们还提供了所有的脚本,以便复制我们的数字和发现[此处]. 注意:在之前的一篇帖子中,我们提供了另一个具有类似发现的案例研究,但使用的数据集是专有的。
挑战数据集和在线调试亚马逊产品上真实用户查询的高门槛。
AmazonTitles-1.3MM数据集是公开可用的,包含了用户在amazon.com上输入的真实查询。该数据集由真实的用户文本查询和与该查询相关的具有统计显著性的产品标题组成,其相关性是通过用户在生产系统中记录的隐式或显式行为来衡量的。在这个数据集上表现良好直接体现了点击相关性。我们将这个数据集与Kaggle上的300万Amazon产品目录进行交叉引用,以通过连接产品标题获得产品的文本描述。
总的来说,我们获得了大约49,602个产品以及它们的文本描述的数据集。此外,我们还有约870,000个(647,127个用于训练,238,435个用于测试)查询和产品关联。任何一个正在运行的产品搜索系统都将具有这些关联。注:训练-测试分区是亚马逊1.3M数据集中所有具有产品描述的原始训练和测试集的直接子集,以确保我们不以任何方式偏向某个分区。
我们在这个数据集上进行了初步的评估。我们评估了在这个数据集上的语义搜索,并提供了准确性指标。为了进行比较,我们使用了默认的弹性搜索、默认的ChromaDB,以及默认的带有在线调整的NeuralDB解决方案。ChromaDB使用了“all-mini-LM-v6”嵌入模型。我们大多数情况下使用默认配置,因为我们的目标是从开箱即用中获得实际的准确性。NeuralDB在产品描述上进行了预训练,并在可用的训练集上进行了微调。
我们还向更广泛的社区开放数据集,以查看RAG或先进的RAG解决方案是否能够达到或超越在线调整的效益。
下表总结了基本的比较。
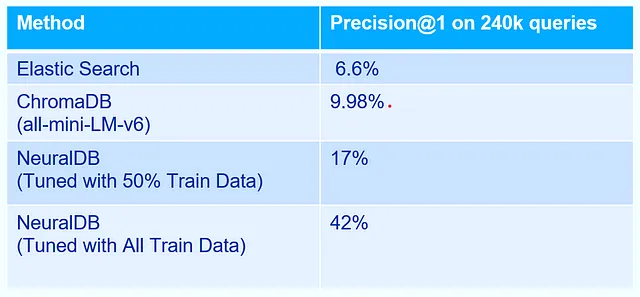
我们想要强调四个观察结果:
1. 在线调优为实时搜索相关性带来了急剧改善:相关性(Precision@1)从9%提高到惊人的42%。
2. 纯语言理解不太可能带来这样的改进。我们可以辩称比Chroma有更好的基准,但它们不太可能填补366%相对改进的突出差距。快速浏览一些例子,其中vectordbs在与NeuralDB相比证明是错误的,揭示了为何语言理解不太可能解决这个问题。
例如,在评估集中,有一个查询,用户输入了“旧金山巨人黑色可重复使用手提袋”。结果发现没有与之完全匹配的产品。Vectordbs提供了一个最佳的近似匹配,为“舒适可重复使用购物手提袋”,更加强调“手提袋”这个概念,这在我们对英语的了解基础上是合理的。然而,根据用户对商品表现真实兴趣的黄金标准,具有统计显著性的产品实际上是“旧金山巨人一次性钢笔”。显然,用户行为显示出对“旧金山巨人”的商品偏好,强调了它在这个特定领域上的重要性。相比之下,“手提袋”则优先级较低。
毫不奇怪,可以在数据集上进行在线调整的神经数据库NeuralDB解决了这个问题,表明用户的偏好可以从他们过去的行为中自动推断出来。
3. 简化中文翻译,保留HTML结构: 3. 在线调整相比微调的需求:正如我们所见,更多的调整数据可以提高准确性。仅使用50%的调整数据时,我们只能达到17%的准确率,而使用完整的调整数据集时,我们可以达到42%的准确率。考虑到调整数据现在是静态的,而评估数据集是固定的,一个固定的微调也可以解决问题。然而,它忽略了一个重要的问题。显然,在生产中,随着更多用户与系统交互,调整数据会不断增长。我们需要一种机制来持续使用这些数据。不幸的是,向量数据库和嵌入模型的性质需要在嵌入模型发生任何变化时进行完全重建,这在实践中会变得非常繁琐。
4. 这些改进不需要与应用程序或领域特定的旋钮有关。我们所用的只是默认的NeuralDB配置,而且我们没有使用任何应用程序特定的调整,完全是通过反馈驱动的改进。这是一个关键点,因为NeuralDB可以在各种用例和领域中使用和部署,而无需进行大量的定制和复杂的工作流程,就像RAG中使用的那样。NeuralDB可以自动适应任何领域,并具有在线调整的能力。
最后的评论
尽管AI社区通过大型语言模型(LLMs)在零样本能力方面取得了显著的改进,但在零样本和领域特定改进的结合方面,它们与企业实际所能实现的还有很大差距。
尽管Advanced RAG包含许多组件,但令人惊讶的是,微调并不是其中之一,尽管许多研究表明微调可以带来显着的好处。对微调的忽视可能是因为向量数据库与不断演化的嵌入模型不兼容。这种局面的讽刺之处在于,在一个嵌入模型日益过时的世界中,如果你在一个嵌入模型上投入足够的精力来构建你的向量存储,你希望这个嵌入模型不会发生演化。
目前,所有的比较都是在人为策划的数据集上进行的,测试集本身是以临时人工的方式生成的,甚至更糟的是,评估查询是从GenAI模型中生成的。这可能是为什么基准测试的进展没有转化为业务效率的主要原因之一。
不要低估正确基准的重要性。您是否考虑到以下事实 - 所有表现最好的90年代甚至早期2000年代的基准都是SVM(或先进的SVM),而深度学习在两个十年中一直落后。








