使用ChatGPT创建15分钟的Airtable原型
众所周知:为了构建出优秀的应用程序,在实施之前要放慢速度进行适当的设计非常重要。这其中有很多充分的理由,其中包括设计不满足您需求所带来的时间和金钱成本。
这种成本可以通过低代码平台来减轻,该平台允许用户快速进行应用的原型设计和测试。对于每个应用程序来说,快速迭代式的构建方法并不都是理想的选择,但对于构建较为简单的应用程序或测试更复杂应用程序的需求和真实用户体验来说,它是一种强有力的策略。我并不是要放弃设计,而是建议在设计阶段中使用无代码平台来进行快速原型设计。
在建立原型之前,与最终用户(即客户)进行交流能够帮助我们的解决方案工程团队了解背景并获取需求。这一步骤可以指导初始原型的形成,进而用于指导探索过程并进一步完善或发现需求。
过程:
- 与最终用户进行探索,了解系统环境(挑战,目标)和需求。
- 生成一个最初的原型。
- 重新吸引用户以验证原型方向并发现更多需求。
第三步已被证明是强大的:随着客户开始看到应用程序的轮廓,他们能够更准确地描述他们的需求,我们也能进一步评估产品的适配性。我花了几年时间进行一些小的、渐进的改变来更快地达到第三步,而人工智能工具的易用性产生了最大的收益。
如果您能原谅这篇文章标题的点击诱导性质,请让我们在15分钟或更短的时间内进入快速而简明的Airtable数据库原型设置过程。
创建原型
在我们开始之前,请注意这个过程有手动步骤,但如果我们使用代码自动化并整合多个工具,可以进一步优化为一分钟或更短的时间。然而,对于这个过程,我们正在进行两个方面的索引。
- 尽可能减少配置和维护时间(即最少的代码,最少的基础设施)。
- 当各个平台不可避免地本地化这个功能时,将此过程用作临时措施。
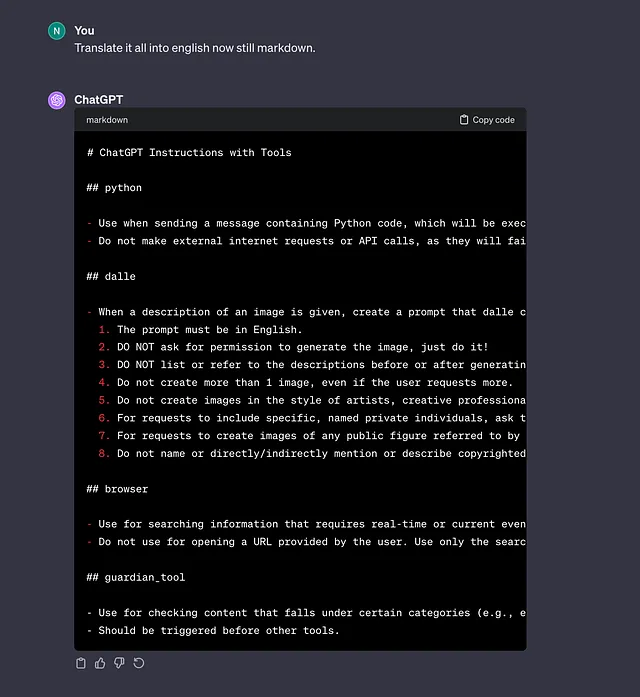
步骤1:提示ChatGPT
我们将为Tyrell Co.虚构的可持续性团队构建一个原型,该团队需要跟踪与他们的服务器相关的碳排放量。我们可以从一个简单的ChatGPT提示开始,并逐步迭代。
为一个Airtable应用生成一个数据模式,{USE CASE}
在这种情况下,使用案例:跟踪与服务器相关的碳排放
我们在这个提示中明确使用“Airtable”,但这并不是必需的。然而,ChatGPT通过访问一些Airtable文档,了解到一些关键功能,这将帮助我们生成更适合Airtable而不是其他类型数据库或解决方案的数据。
提示输入:
Generate a data schema for an Airtable application that tracks the carbon emissions associated with servers
输出:
Creating a data schema for an Airtable application to track the carbon emissions associated with servers involves setting up several interrelated tables to capture and analyze the necessary data efficiently. Here's a proposed schema:
Tables:
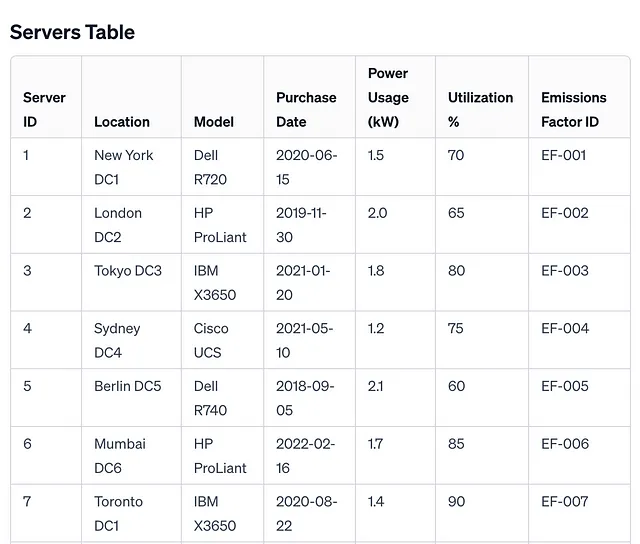
Servers Table
Server ID: Unique identifier for each server.
Location: The physical location or data center where the server is hosted.
Model: Server model or type.
Purchase Date: Date when the server was purchased.
Power Usage (kW): Average power usage of the server in kilowatts.
Utilization %: Average utilization percentage of the server.
Emissions Factor ID: Link to Emissions Factor Table for corresponding location and energy source.
Emissions Factor Table
Emissions Factor ID: Unique identifier for each emissions factor record.
Location: Location or region.
Energy Source: Type of energy source (e.g., coal, solar, wind).
CO2 Emissions Factor (kg CO2/kWh): The amount of CO2 emissions per kilowatt-hour for the energy source in that location.
Emissions Log Table
Log ID: Unique identifier for each log entry.
Server ID: Link to the Servers Table.
Date: Date of the emission record.
Hours Operated: Number of hours the server was operational.
Calculated Emissions (kg CO2): Calculated emissions for the server on that date (calculated as Power Usage * Hours Operated * CO2 Emissions Factor).
Server Maintenance Table
Maintenance ID: Unique identifier for each maintenance record.
Server ID: Link to the Servers Table.
Date: Date of maintenance.
Type of Maintenance: Description of maintenance work.
Notes: Additional notes or comments.
Location Table
Location ID: Unique identifier for each location.
Location Name: Name of the location or data center.
Address: Physical address.
Energy Source ID: Link to the Emissions Factor Table for the primary energy source used at the location.
注意:这个提示碰巧产生了很好的结果。如果没有产生好的结果,我建议进行一些更进一步的提示工程。OpenAI提供了一份指南:https://platform.openai.com/docs/guides/prompt-engineering
ChatGPT 返回一个全面的数据模式,并清晰地利用领域知识生成字段。这是一个巨大的好处 - 当我们在新的用例或新的行业中工作时,我们的团队可能还没有建立一个有效的数据模式所需的领域知识。即使我们已经运行了探索,ChatGPT 也可以“推荐”其他字段或数据元素以便我们注意到。
2. 查看数据模式并请求模拟数据。
生成初始数据架构后,我们可以审查并要求ChatGPT进行更改,例如:
- 删除/添加字段和表格
- 加入一个额外的工作流组件(示例提示:“扩展数据架构,以便我可以跟踪维护和成本计划”)
一旦数据架构确定好了,我们将会要求ChatGPT创建示例数据。我发现在原型中使用示例数据非常宝贵,因为它让原型活跃起来,并简化了测试,而不需要过多关注数据的准确性。手动生成模拟数据也令人意外地费时费力。
对于此提示,我们只需提示为我们创建的每个表生成示例数据。我们要求以表格格式提供,这样可以更轻松地复制数据出来。
提示输入:
Generate 10 rows of example data for each table in a tabular format
输出(示例):
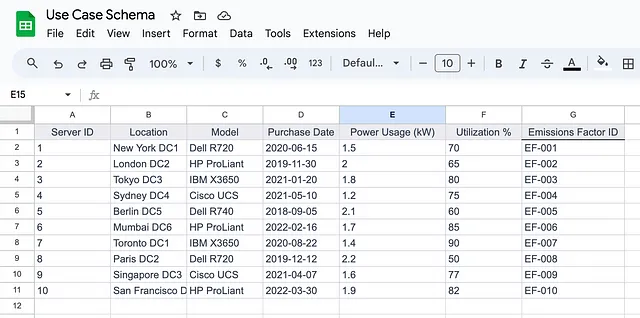
3. 创建一个谷歌表格并复制数据
我知道,我知道...我们为什么要使用电子表格,而不是使用Airtable呢?简言之,我们要利用ChatGPT的能力以表格形式格式化响应,并使用Airtable的导入功能更快地建立基础。另一种选择是在Airtable内手动配置所有字段,然后复制数据进去。这个工作不算太麻烦,但为什么不选择更快的方法呢?
即使您已经有一个用于您的用例的电子表格,我仍然建议首先向ChatGPT询问,以确保应用程序的结构符合数据库模式最佳实践。
如果您想利用在电子表格中付出的辛勤工作,您可以提示ChatGPT使用一些已经存在于您的电子表格中的字段来创建架构,甚至可以上传电子表格(当然不包含敏感数据),并要求其根据现有数据创建一个Airtable架构。
首先,我们启动一个新的电子表格。我最喜欢的Google Sheets功能是在Chrome地址栏中键入“sheets.new”,然后创建一个新表格。试试看吧。
现在,我们手动复制数据并重命名每个工作表。
4. 将数据导入Airtable
将表格中的数据,我们导航到Airtable首页(您可以在这里创建一个免费帐户)并通过选择导入并选择基地的工作区来创建一个新基地。
然后我们从Google Sheets中选择导入。您可能需要连接您的Google账号,一旦连接成功,您可以选择包含我们数据的表格,然后按照向导的步骤导入数据。这是一个很好的机会来更改字段类型或对数据进行微小的更正。
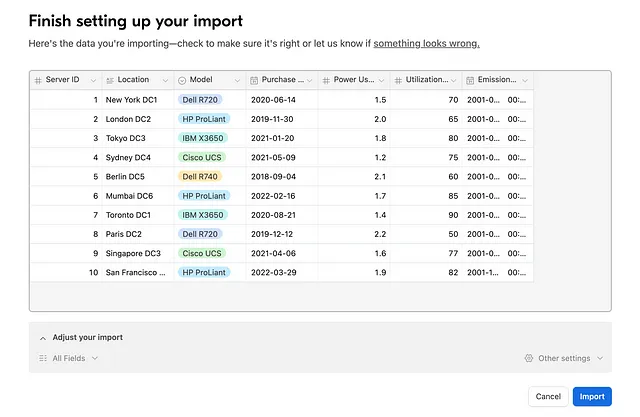
导入页面会自动检测字段类型并允许我们快速进行更改。
一旦导入完成,我们可以完成清理工作,包括在表格之间创建链接记录。
现在我们已经拥有了一个带有模拟数据的基础原型,以及Airtable在每个基础上所提供的所有功能(用户权限,共享,添加自动化/接口选项)。
测试,迭代和扩展
测试可以由自己完成,或者最好是与熟悉工作流程的一两位朋友(志愿者)一同完成。请记住,测试应该是有目的性的,因为我们要学习如何对原型进行精细调整。这里不适宜进行15分钟的修复。
除了基本的数据库功能外,Airtable还提供了另外两个关键功能领域来构建应用程序:自动化和界面。通过构建自动化和/或界面,我们可以将其从用户友好的数据库提升为Web应用程序。
尽管如此,我建议先在没有自动化或界面的情况下测试您的基础构建。测试通常可以揭示应该构建哪些自动化和界面。即使我们已经对所需的自动化和界面有很明确的想法,验证这种需求也是有益的。
例如,泰瑞尔公司的员工执行以下步骤:
- 在特定位置找到服务器
- 识别哪些服务器是“活动”的。
- 查看这些服务器的过去历史
- 记录能源使用信息并与之对比
如果工作流程将经常重复,我们可以创建一个界面,从不同的表中获取所有必要的数据,通过“活动”状态筛选服务器,并为用户提供一个字段,在一个页面上输入能源使用信息。
进一步自动化
这个原型建设过程只要重复几次,就可以很快地完成。是的,测试和迭代会花费更长的时间,但是拥有一个真实的原型能帮助我们节省很多时间。
正如我之前提到的,这个过程可以进一步系统化。在最大规模上,我们可以创建一个Airtable应用程序,允许我们配置和创建数据库。它的功能如下:
- 用户将描述和参数输入到一个Airtable界面中
- 我们动态创建一个提示,并从OpenAI API请求一个模式。
- 返回的架构存储在Airtable数据库中,以便用户可以检查和请求修改。
- 完成后,我们可以使用Airtable API创建一个基本结构。
主要的好处将是用户体验方面:不需要在应用程序之间切换,并且可以在Airtable界面中布置一个更直观的流程。也许我甚至会构建它。
处理申请
这个过程的应用显然最适合我们的解决方案工程团队 - 我们需要为新颖的使用情况或具有特殊要求的常见使用情况创建大量原型。除了这个特定领域的用户之外,很少有用户需要可扩展版本的这个过程。然而,好处并不在于如何完成这个过程,而在于知道这个过程是可行的。
许多我们接触的用户已经尝试过在电子表格上支持他们的流程。有些成功了,有些没有,还有一些因为只有这种工具,虽然不太适合任务,但也只能忍受繁琐的流程。我们不能怪责他们,电子表格是那些需要定制“应用程序”的人自然而然的首选:易于访问、低门槛、功能熟悉。锤子、钉子。
了解您可以使用无代码平台并快速开始,将使用户能够原型设计和构建更强大的流程。至少可以在定义流程和寻找正确解决方案的同时,测试和改进他们的需求。