比较不同的AI在Android应用中进行翻译

在快节奏的人工智能和机器学习世界中,能够比较和对比不同的模型已经成为一个关键需求。开发人员,数据科学家和企业在为他们的项目选择正确的人工智能解决方案时经常陷入困境。在我的实习学期中,我有幸在arconsis公司进行实践,探索了应用开发和机器学习的领域,我接受了一个激动人心的挑战,将四个独立的人工智能模型集成到一个安卓应用程序中。
这个项目特别适合作为对公司的介绍和融入,是一个激动人心的为更大的项目做准备的过程。
这项努力不仅标志着我初次涉足机器学习和应用开发的领域,还旨在创建一个用户友好且简化的设置,以迅速交付结果。
本文概述:
- 模型概览:我将测试和讨论集成到应用中的 AI 模型。我使用了 DeepL、ChatGPT、Google 的 ML Kit 框架以及 Microsoft Azure Portal 的翻译器。此外,我也会分享测试 Meta 的 Llama2 在应用之外的洞见,因为没有现成的 API 可供使用。在测试过程中,我发现 Llama 2 并不适合翻译,所以我干脆不再将其集成到应用中。
- 发展见解:我将深入探讨此应用程序背后的软件工程和整洁结构,通过截图展示其设计、代码和功能的重要方面。
- 绩效评估:为了进行全面的分析,我将使用一个德语例句,并在对比表中展示其翻译成英语、法语、波斯语和中文的版本。我还将比较整合的人工智能模型的平均响应时间。
加入我,一起探索这个创新的Android应用的发展历程,揭示构建和允许比较不同AI模型的关键功能的步骤。让我们在人工智能的世界里迎来一个新的理性决策领域。
在文章末尾,您可以找到GitHub存储库的链接,其中包含源代码。
DeepL:DeepL is an artificial intelligence-powered translation service.
谈到翻译质量,DeepL在其人工智能同行中突显出色。
DeepL仅支持31种语言,但提供相当准确的翻译。DeepL还提供语言检测功能,以便您可以根据待翻译的文本识别出源语言。
它提供了一个免费版本,包括对所有功能的访问权限,每月可翻译多达500,000个字符。对于更广泛的使用,DeepL提供每月4.99欧元的订阅计划,为个人使用提供无限字符翻译。对于企业用户,存在特殊商业许可证。
谈到性能,DeepL在高可用性和快速响应时间方面表现突出。这确保翻译不仅准确无误,而且能够快速交付,使其成为对时间敏感的项目的有价值工具。
聊天GPT
保持HTML结构,将以下英文文本翻译为简体中文: ChatGPT以提供可靠的回答而闻名,尽管这些回答的质量可能因查询的性质和要翻译的文本长度而有所不同。文本越长,遇到超时或其他异常的可能性就越高,这是需要注意的事项。
聊天GPT的显著特点之一是其语言多样性。它可以有效地以多种语言进行回应,消除了对语言支持的担忧。它是真正面向全球受众的强大语言模型。
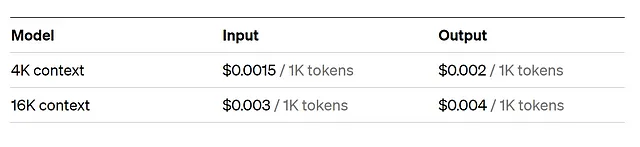
在定价方面,ChatGPT为新用户提供了一个有吸引力的激励措施。用户在开设一个帐户时,将获得初始的5美元信用,可用于ChatGPT的所有API服务。需要注意的是,这5美元的信用仅在四个月内有效,此后用户可以选择付款计划以继续使用。此外,ChatGPT的定价是基于令牌的,1000个令牌相当于大约750个字(参见下表,以gpt-3.5-turbo为准)。
除了定价之外,ChatGPT还有一些使用限制。在这个模型中,用户每分钟限制为3个请求,每天限制为200个请求。然而,对于gpt-3.5-turbo模型,用户每分钟可以生成多达40,000个标记。这些限制仅适用于免费版。高级版本有更高的限制。
Google的ML Kit
Google的ML Kit提供了一种简单直接的方法来翻译,无需手动调用API。开发人员可以通过在Gradle文件中添加简单的依赖来集成翻译能力。
implementation ("com.google.mlkit:translate:17.0.1")
一旦集成,开发人员可以创建一个翻译器对象,并根据所需的源语言和目标语言进行配置。
此外,ML Kit 提供语言检测功能,支持超过100种语言。然而,需要注意的是,翻译功能本身仅限于58种语言。要启动翻译,唯一的要求是下载特定的语言模型,大约30MB大小。开发者可以根据需要将下载偏好设置为仅限Wi-Fi或允许通过任何网络下载,为用户提供便利。
Google的ML Kit的一大明显优势是其成本效益。在翻译服务方面没有额外费用;用户只需下载所需的语言模型,使其成为一个经济实惠的选择。此外,本地化模型允许用户仅下载并使用他们经常需要的语言,从而实现离线使用。
就准确性而言,翻译的质量相当不错,尽管可能会因文本的长度和复杂性而有所不同。虽然可能不能与一些专业的翻译服务的精确度相媲美,但它提供了许多日常翻译需求的解决方案。
Google的ML Kit凭借其简洁性、经济性和本地模型方法,为基本的翻译需求提供了实用解决方案。在我的探索中,我发现它是寻求本地化离线翻译能力的用户的一个选择。
微软的AI翻译服务:
微软的人工智能翻译服务拥有强大的实力,支持129种语言。除了翻译功能,它还提供语言识别功能。
微软的服务之一的特点是其可用性和快速响应时间。无论您是在翻译文本还是使用语音识别功能,微软确保高响应性,最大程度减少延迟,让用户能够顺利完成任务。
在定价方面,微软提供灵活性,以满足各种需求。免费版本(F0)每月提供2百万字符的宽容分配。对于更广泛的使用,微软提供多种不同成本的订阅计划。定价范围从每月10美元的1百万字符(S1标准)到每月4.5万美元的10十亿字符(S4标准)可以有所不同。还有其他计划选项如C2、C3、C4和D4,以满足不同需求。需要注意的是,您必须拥有Microsoft Azure订阅才能使用这些服务。这就是为什么它不是完全免费的原因。但仍然提供免费试用期,您可以测试任何服务。
这种成本结构为用户提供了根据他们的使用情况选择最合适的方案的灵活性。
微软的翻译服务的准确性值得赞扬,不仅在常用语言之间提供精确的翻译,还能够处理结构复杂的波斯语和阿拉伯语等语言(基于我个人的经验)。
羊驼2:
Meta的Llama2以独特的方式与AI模型进行交互,注重可访问性和多样性。虽然使用RESTful web服务的传统方法很普遍,但Llama2在特定条件下运行,并提供使用API调用的替代解决方案。
对于更广泛的Hugging Face平台,开发人员可以方便地向各种AI模型发出API调用。Hugging Face主机上有大量的模型,设计用于多种目的,包括文本到图像,图像到文本,文本到语音等等。这是通过使用类似于“https://api-inference.huggingface.co/models/t5-base”的基本URL,并在末尾附加所需模型的名称来实现的。此外,API调用只需包含授权详细信息的标头和输入文本的主体即可。
然而,Llama2的运作方式不同。它不符合传统的RESTful web服务模型,并且在特定条件下才能访问。Llama2是Meta提供的一个相对较新且正在发展的选择。开发者可以通过其他选择与Llama2进行交互,比如利用基于miniconda的现有脚本"Oobabooga"。还有一个名为https://localai.io/的网站。它提供了一个ChatGPT API,您可以调用Llama模型。安装完成后,它会提供一个本地的TextGen Web UI,使用户能够与Llama2进行交互。调整GPU内存设置是必要的,因为Llama2在本地运行并需要资源。
Llama2 提供三个不同版本:7B、13B 和 70B。目前使用 Llama2 模型是没有费用的(所以模型本身是免费的,但运行模型需要花费金钱)。然而,如果用户想要创建自己的 TextGen API,他们可以选择利用像 RunPod 这样的 GPU 资源,相应地产生费用。
谈到翻译质量时,Llama2在某些语言和简单文本方面只能达到可接受的水平。对于更复杂的翻译,它的表现不如人意,因此在翻译任务中不太适用。Llama2可能在其他场景中找到更好的应用,当其独特能力与手头任务相吻合时。
继续我们的旅程,现在我们将探索应用背后的整体软件工程和结构,以及通过对这些人工智能模型的评估所获得的迷人见解和结果。
发展见解:打造一个敏捷多功能的应用程序
这个应用的主要目标是促进各种人工智能模型翻译能力的比较,为用户提供有关其表现的见解。该应用面向广泛的受众,包括对人工智能和翻译技术感兴趣的个人。安卓应用的开发是一次利用尖端工具并遵循软件工程的基本原则的旅程。通过这次旅程,我能够为比较各种人工智能模型创建一个结构良好、多功能且用户友好的应用程序。
这是对开发过程的一瞥:
工具选择:我利用 Android Studio 作为集成开发环境(IDE),采用 Kotlin 作为编程语言,并使用 Jetpack Compose 来设计应用的用户界面(UI)。这些技术共同简化了开发流程,并确保了现代化、响应式的UI。
软件工程原则:遵循谷歌推荐的应用架构原则,基于模型-视图-视图模型(MVVM)的原则。为数据管理建立了单一真实来源。利用ViewModel来管理数据和用户界面交互逻辑,为每个翻译器创建了专用的类。
用户界面设计:遵循“状态提升”的原则,我设计了用户界面,确保事件向上发送,状态向下传播,作为单向数据流的一部分,这是建议的应用架构的原则。这增强了UI元素的可预测性和可管理性。大部分时间使用无状态的组件来创建可重用的UI组件,提高了应用的可维护性。
本地化:为了迎合不同语言的用户,文本字符串被存储在资源文件(res -> values)中,分别为德语和英语。这使得应用能够根据用户设备的设置,以用户偏好的语言显示文本内容。
安全的API密钥处理:API密钥从Gradle文件中读取,允许在编译期间自动生成到BuildConfig文件中。请注意,这样做确保了API密钥不会存储在代码库中,但它们仍将包含在应用程序中,并实际上是公开可见的。我在这个简单的测试应用程序中这样做是为了不过于增加其范围。在真实的应用程序中,人们会利用一个后端前端来处理密钥,并代理调用服务。
动态模型集成:为了确保应用的通用操作,创建了一个JSON文件(res -> raw -> translators_info.json)。该文件仅在应用启动时加载一次,包含每个翻译器的名称及其对应的实现类。这种极简主义的方法允许通过一行代码轻松集成新的翻译器(但仍需要实现翻译器类,并且仅凭这一行代码无法实现魔法)。
[
{
"name": "DeepL",
"className": "com.example.aitranslators.services.DeepLTranslator"
},
{
"name": "ChatGPT",
"className": "com.example.aitranslators.services.ChatGPTTranslator"
},
{
"name": "Google",
"className": "com.example.aitranslators.services.GoogleTranslator"
},
{
"name": "Microsoft",
"className": "com.example.aitranslators.services.MicrosoftTranslator"
}
]
翻译服务接口:定义并由每个翻译类实现的通用接口TranslatorService,用于保持函数名称和结构的一致性。
interface TranslatorService {
suspend fun translateText(query: TranslationQuery,):Result<TranslationResult>
fun canDetectLanguage(): Boolean
suspend fun detectSourceLanguage(text: String): DetectedLanguage
}
数据库集成:该应用还提供了一个数据库,供用户存储翻译。实施了一个单独的屏幕来显示已保存的翻译列表,增强了应用的功能性。
编写导航图:为了将所有组件保持在一个单独的活动中,引入了Compose导航图,实现了屏幕导航和过渡的无缝切换。
状态管理:每个屏幕从ViewModel中获取其数据作为一个整体,描述屏幕的当前状态。这样,屏幕可以由一个唯一的真实数据源一致地创建。状态由一个流提供,因此每当ViewModel更新流时,UI会自动更新。
private val _translationData: MutableStateFlow<TranslationData> =
MutableStateFlow(TranslationData())
val translationData: StateFlow<TranslationData> =
_translationData.asStateFlow()
依赖注入(DI):为了方便管理类的创建和依赖关系,应用程序广泛使用Hilt进行依赖注入。例如,用于ViewModels和repository类。
水平分页器集成:该应用的用户界面具有水平分页器,当用户在页面之间滑动时,会更新当前索引。当用户点击“翻译”按钮时,ViewModel会调用translateText()函数,并传递当前索引以确定调用适当的翻译器类。
语言选择:选择了固定的语言列表,以便更容易比较不同的AI模型,因为并非所有模型都支持全部语言。语言名称被映射到API调用的语言代码(在映射函数中)。
响应时间测量:测量响应时间并显示在用户界面上,以便用户可以比较各种人工智能模型的性能。
在这些开发见解的指导下,我们努力以敏捷方式创建一个灵活、有洞察力的应用程序,为用户提供了一个强大的比较人工智能模型的工具。我们对于清晰的软件工程原则的承诺确保了稳健而用户友好的体验。
以下是小应用的一些屏幕截图,以视觉形式展示其结构和功能。设备语言为德语,因此应用程序中的所有文本都是德语。如果设备语言不受支持,应用程序的默认显示语言为英语。在开发应用程序时,我目前只考虑了英语和德语。


绩效评估:人工智能模型的比较分析
为了衡量不同人工智能模型的性能和效果,我进行了一项简单的评估,将一句德语句子分别使用集成的翻译服务翻译成英语、法语、波斯语和中文。在谷歌和Llama 2翻译不正确的情况下,使用英语作为源语言进行了后续测试以评估改进效果。为了测量平均响应时间,每个翻译都进行了10次。
以下是展示性能评估结果的表格(颜色表示翻译质量):



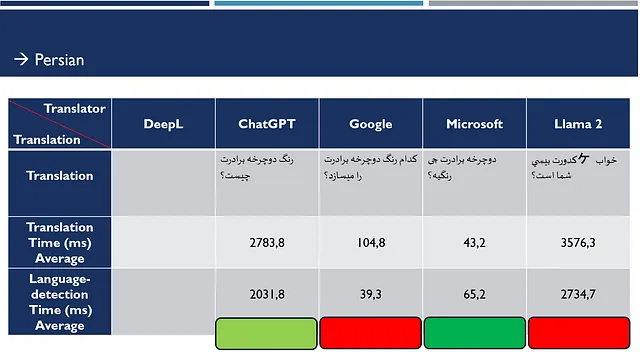
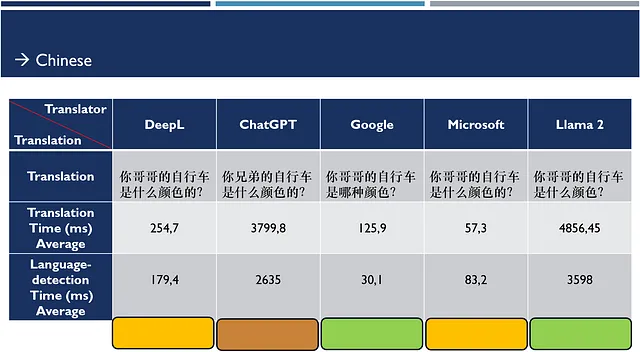
在从德语翻译为中文时,DeepL和Microsoft并不差,Google和Llama还可以,但是ChatGPT有些奇怪。因此再次从英语翻译为中文:

这一次的翻译质量有所提升,但是谷歌的结果较差。
正如我们所看到/核实的,Google 和 Lama 没有正确翻译(从德语到英语)。这就是为什么我再次测试它(从英语到德语)。以下是结果:
谷歌
你弟弟的自行车是什么颜色?
美洲骆驼2:
你兄弟的自行车是什么颜色?
我也特别针对波斯语再次测试了Llama 2,希望以英语作为源语言会有更好的结果…即使作为一个波斯语使用者,我也不理解这句话: چراغ کولر بیک خود آقا است?(Cheragh-e koolor beik khud ast?)
结论:
在AI翻译服务的整体方案中,最终的选择取决于您的具体需求。让我们用简明的结论总结我们的评估:
如果您最重要的是迅速回应,谷歌的 ML Kit 是一个选择。它提供了快速的(因为有离线功能),但不是高质量的翻译。
对于那些追求快速且高质量翻译的人来说,DeepL处于领先地位。
如果您需要快速响应、准确性和广泛的语言范围,Microsoft的人工智能翻译服务是不错的选择。Microsoft在提供广泛的语言和可靠的翻译方面做得很出色。
如果您看重便利性和相对准确的翻译而不一定需要迅速的回应,ChatGPT就是您的选择。它是一个用于各种目的的强大语言模型。
关于我个人的前三选择,它们分别是微软、ChatGPT和DeepL。
在寻找合适的人工智能翻译模型时,需要考虑您的具体需求,无论是速度、准确性、语言支持还是多功能性。
需要注意的是,这些评估是截至2023年12月的最新数据,由于人工智能模型不断演进的特性,这些排名可能会随着时间变化而变化。不能保证这些模型特性的持久性。
恭喜您完成本文的阅读!您对阅读的热情值得奖励,这就是我们的GitHub存储库的链接,那里存放着整个源代码,等待您好奇的目光。
GitHub 仓库链接
谢谢您与我一同走过AI翻译应用的开发和性能评估之旅。希望这些见解为您的AI模型选择过程提供有价值的信息。祝您翻译愉快!