强化学习已死。变压器万岁!
大型语言模型比你想象的更强大

为了开始这篇文章,我想要说我没有任何偏见。如果你以批判性的眼光在网上搜索,你会找到无数其他的文章和经历,解释强化学习在实际应用中根本不起作用。唯一声称相反的是课程创作者和该领域的学者。
我本来希望强化学习能够起作用。5年前,当我第一次听说它时,有人向我承诺它将彻底改变世界。一个可以通过聪明的奖励来优化任何事物的算法似乎可以普遍应用于从设计药物到高级机器人的领域。2016年,当AlphaGo在围棋这个著名复杂游戏中击败了李世石,这应该是强化学习开始占主导地位的转折点。
然而,八年过去了,所有这些都没有实现。强化学习在现实世界中一无所获。它仅在玩具问题和视频游戏中占主导地位。过去八年中强化学习的唯一显著进步是使用人类反馈(RLHF)进行训练的大型语言模型,如ChatGPT。就我个人而言,我认为我们不会再长时间使用它。其他算法能够更好地完成这些任务。
什么是强化学习?
强化学习是机器学习的一个子领域。与传统的监督学习不同,我们有一堆输入示例和标签。我们训练模型将正确的标签应用于输入示例。我们使用8台超级计算机和数百万个训练示例进行这样的训练,最终获得一个能够识别图像、生成文本和理解口语的模型。
在另一方面,强化学习通过不同的方法进行学习。通常情况下,强化学习并没有标记的示例。但是,我们可以设计一个“奖励函数”来告诉我们模型是否在我们希望的方式下工作。奖励函数本质上是在模型没有按照我们期望的方式运行时惩罚模型,而在模型按照我们期望的方式运行时奖励模型。
这个公式看起来很神奇。获取数百万个有标签的示例非常耗时且对于大多数问题来说并不实际。如今,由于强化学习的出现,我们只需要制定一个奖励函数,就能够生成解决复杂问题的方案。但事实是,它并不奏效。
我(可怕的)强化学习经历
我陷入了强化学习的炒作之中。一切始于我在康奈尔大学学习的《人工智能导论》课程。我们简要讨论了强化学习及其可以解决的问题类型,我被深深地吸引。于是,我决定参加阿尔伯塔大学的在线课程,深入研究强化学习。我获得了一张证书,证明了我在这个领域的专业知识和技能。

在从康奈尔大学毕业后,我去了卡内基梅隆大学攻读软件工程的硕士学位。我决定选修一门声名狼藉的课程——《深度学习介绍》,因为我对这个主题很感兴趣。正是在这里,我能够将强化学习应用到一个实际问题中。
在课程中,我们被要求完成一个期末项目。我们有自由选择实现任何深度学习算法,并撰写一篇关于我们经历的论文。我决定将我对金融的热情与我对强化学习的兴趣相结合,实现一个用于股市预测的深度强化学习算法。
该项目以惊人的失败告终。设置起来非常困难,一旦设置完成,总是会出现一些问题。调试问题非常痛苦,因为一旦所有内容编译和运行成功,你就不知道系统的哪个部分没有正常工作。可能是用于学习状态到动作映射的演员网络,可能是用于学习状态-动作对的“价值”的评论家网络,也可能是网络的超参数,甚至是其他任何东西。
我对RL并不生气因为项目失败了。如果一群研究生能够在一个学期内开发出一个广受欢迎的股票交易机器人,那将会颠覆股市。不,我对RL感到生气是因为它很糟糕。我将在下一节做更详细的解释。
对于这个项目的源代码,请查看下面的存储库。您还可以在这里阅读更多的技术细节。想要获取有关人工智能的更多有趣见解,请订阅 Aurora 的 Insight。
为什么强化学习如此糟糕?
增强学习存在许多问题,使其无法在实际情况下使用。首先,它非常复杂。虽然传统的增强学习有些合理,但深度增强学习则完全没有意义。
作为一个提醒,我曾就读于一所常春藤联盟学校。我大部分的朋友和熟人都会说我很聪明。但是深度强化学习让我感到很愚笨。有太多术语涉及其中,除非你在攻读博士学位,否则你不可能完全理解所有内容。有“演员网络”,“评论员网络”,“策略”,“Q值”,“剪辑替代目标函数”以及其他需要在任何实际操作时查词典才能明白的不合常理的术语。
它的复杂性超越了难以理解的术语。当你尝试为比购物车池更复杂的问题设置强化学习时,它却无法工作,而你又不知道原因。
例如,当我进行使用强化学习预测股市的项目时,我尝试了几种不同的架构。我不会详细讲解技术细节(如果你想了解,请查看这篇文章),但是我尝试过的所有方法都无效。在文献中,可以看到强化学习存在许多问题,包括计算上的昂贵性、稳定性和收敛性问题,以及样本效率低下。这真让人难以置信,考虑到它使用了深度学习,而深度学习被广泛认为可以处理高维大规模问题。对于我的交易项目来说,最影响最终结果的是神经网络的初始化种子。这真是可悲。
为什么变压器将要取代强化学习算法?
变压器解决了传统强化学习算法的所有问题。首先,它可能是最简单、最有用的人工智能算法。一旦你理解了注意力机制,你可以开始在Google Colab中实现变压器。而且最好的部分是,它实际上起作用。
我们都知道,当实现类似ChatGPT的模型时,变压器是非常有用的。但是大多数人没有意识到它也可以用作传统深度强化学习算法的替代品。
我最喜欢的论文之一是《决策变换器》。我很喜欢这篇论文,以至于我给作者们发送了电子邮件。决策变换器是一种新思路的强化学习方法。与使用多个神经网络、敏感的超参数和没有理论基础的启发式引导的复杂优化相反,我们使用的是一种已被证明适用于许多问题的架构——变换器。
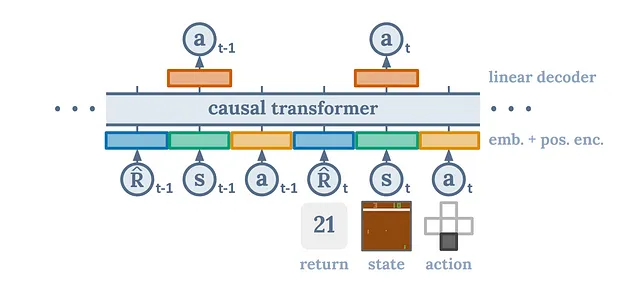
我们基本上想把强化学习重新构想为一个序列建模问题。我们仍然有像传统强化学习中的状态、动作和奖励一样的元素,只是我们以一种不同的方式表达这个问题。我们以自回归的方式对我们的状态、动作和奖励进行布局。这导致了一个非常自然且高效的框架,其中转换器理解和预测序列的能力被用来寻找最优的动作。通过这种方式来构建问题,决策Transformer可以有效地解析状态、动作和奖励的序列,并直观地预测最佳行动方案。这导致了一种算法,无缝地揭示出最有效的策略,优雅地绕过传统强化学习方法中经常遇到的复杂性和不稳定性。
为了透明度,这是一种离线算法,这意味着它无法实时工作。然而,正在进行额外的工作以使决策变压器能够在线使用。即使是算法的离线版本也比传统的强化学习要好得多。本文表明,该架构更加稳健,尤其适用于奖励稀疏或干扰的情况。此外,该架构非常简单,只需要一个网络,并且能够达到或超过最先进的强化学习基线。
对于Decision Transformer的更多详细信息,请查阅原始论文或Yannic Kilcher的这个非常有帮助的视频。
结论
基於傳統強化學習,真的很差勁。除非業界出現一種新的、穩定且高效利用樣本的算法,不需要博士學位才能理解,否則我不會改變我的觀點。決策轉換器就是新的強化學習方法,只是還沒有被普及。我期待有一天研究人員使用它來進行各種任務,包括使用人類反饋進行強化學習。
非常感谢您的阅读!
🤝 连接我的领英账号
👨💻 在GitHub上浏览我的项目
📸 在Instagram上找我
🎵 跳入我的TikTok