在Google Cloud的VertexAI中使用大型语言模型(LLMs)
从概念到代码:想要开始使用GenAI的LLMs构建应用程序,您需要了解的一切。
始终采用新方法始终是个好主意,那为什么不尝试一下全新的热门话题:GenAI呢?大规模语言模型在各个领域都提供了几个优势和机会,没有人想被落下。在本博文中,我们将介绍GenAI的大规模语言模型及其潜力,我们将深入探讨VertexAI和VectorSearch的贡献,这将帮助您为您的组织做出决策。
拥抱人工智能
生成式人工智能:不断的下一个
人工智能(AI)是一种理论和发展,使机器能够模仿人类的思维和解决问题的能力,而机器学习(ML)是AI的一个子集,使机器能够在无需明确编程的情况下学习。
一个生成模型可以利用其从暴露的示例中获得的知识,并根据这些信息产生全新内容。它可能已经看到其中的部分内容,并且能够综合并生成新的东西,如文本、视频、图片、代码和音频。
这种创造新事物的特征是为什么它被称为“生成”的原因。
它属于ML的广泛范畴,其中一些系统包括ChatGPT和Bard。
语言模型:概率引擎
大型模型或LM是生成式人工智能的引擎,可以帮助预测和创建连贯的文字。它们能够预测一个词序列中的下一个词。
这些模型正在通过大量的文本进行训练,以便更好地理解并预测接下来会出现的单词 — 就像我们从多套学习材料中学习一样。
它得到在一个令牌序列中出现的令牌(单词/字符/子词)的概率。考虑以下情况:
"When I see a rainbow in the sky, I _______."
假设令牌是一个词,语言模型会得到不同词语可以填充句子的概率。
take a photo - 8.7%
make a wish - 6.3%
call a friend - 4.1%
dance with joy - 3.5%
sing a song - 2.9%
通过这样的概率,可以用于预测下一个可以用于生成文本、翻译语言、回答问题等的序列。
大型语言模型:GenAI的基础
深度学习- 就像给机器人一个大脑来理解事物,而不是我们在每个细节上都告诉它(就像教孩子区分猫和狗一样)。多年前,我们习惯于编写每个细节并传递给机器让其理解,但通过深度学习,我们更喜欢给机器提供大量相关数据,让它自己找出区别。它是机器学习的一个子集,使用人工神经网络,受到人脑的启发。
大型语言模型 (LLMs) 是深度学习的一个子集,通过大量数据训练,可以生成类似人类文本并解决与语言相关的问题,如文本澄清、问答、文档摘要、文本生成等。
以下是他们之间的关系总结:
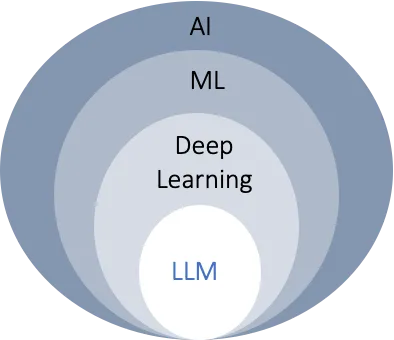
它们是推动生成式人工智能的引擎。
- 这些模型是使用大量数据进行预训练的——通常包括数十亿个参数的数据量,这些参数用于衡量模型的技能水平。
- 他们具有零样本或少样本学习的最小现场训练数据,这意味着这些模型可以预测或创建它们未经明确训练的新输出/数据。
- 它们可以根据业务需求进行微调,这意味着您可以通过使用您的数据来训练它们,并根据您的需求进行调整,从而开发出生成型人工智能应用程序。它们可以在大规模的文本和代码数据集中进行训练。
- 开发者和爱好者不需要先前的机器学习或专家水平的培训知识;所需的只是对提示设计的头脑风暴。这是一个试错的过程,我们通过向GenAI模型提供高效输入来实现期望的结果。就像对谷歌搜索提出适当的查询以获取所需结果一样(如果你搜索狗,你不会获得猫的详细信息)。或者试着向雄鹰要求一个机器学习流程图示——它不会给你的。
- 几种框架可以用于快速设计以创建基于LLM的应用程序。其中一个广受欢迎的是LangChain,它提供了LLMs接受字符串输入和输出的接口。为了验证LangChain文档中的数据,广泛使用Pydantic工具,有助于对我们的模型的输入和输出响应进行形塑。
VertexAI - 无代码选项构建模型
GenAI 模型需要多个 GPU、计算资源进行训练,甚至还需要更多资源将其扩展至企业级别。
为了解决包括扩展性和安全性在内的所有技术麻烦,作为一个以人工智能为核心的公司,谷歌推出了VertexAI,让开发者能够更专注于项目开发和实验,而无需担心基础设施问题。
Google Cloud提供了几个解决方案,借助VertexAI平台以开放、负责和安全的方式构建和使用人工智能。通过使用VertexAI的PaLM API和Codey API,我们可以为我们的AI应用程序定制LLM。以下是我们在文本模型中使用PaLM 2的示例代码:
from google.cloud import aiplatform
from vertexai.language_models import TextGenerationModel
import langchain
llm = TextGenerationModel.from_pretrained("text-bison@002")
response=print(llm.predict(
"What is Bengaluru famous for?",
max_output_tokens=256,
temperature=0.1,
top_p=0.8,
top_k=40,
))
print(f"LangChain version: {langchain.__version__}")
print(f"Vertex AI SDK version: {aiplatform.__version__}")
输出的结果结构将类似于以下内容:
...
4. **Aerospace Industry:** Bengaluru is a significant center for the aerospace industry in India. It is home to several aerospace companies, including Hindustan Aeronautics Limited (HAL), the National Aerospace Laboratories (NAL), and the Indian Space Research Organisation (ISRO).
5. **Cultural Diversity:** Bengaluru is a cosmopolitan])
LangChain version: 0.0.323
Vertex AI SDK version: 1.39.0
我们使用了Vertex AI的语言模型和TextGenerationModel类,其中text-bison002是它的一个实例。
有几个GenAI API和模型按内容类型进行分类,包括文本、聊天、图像、视频、嵌入、编码和多模态数据。
Google提供了Gemini和超过130个基础模型供用户在Model Garden中选择,用户可以根据使用情况使用各种调优选项自定义模型。
而且别忘了还有VertexAI Studio,可以用来原型设计和测试模型。
矢量搜索
矢量搜索用于存储和高效检索由文本嵌入模型生成的向量,用于相似度搜索或推荐系统的上下文中。
为了更好地理解,让我们从基础知识开始:
嵌入:它是使用机器学习技术创建的将任何数据表示为空间中的点的方式。当我们将文本输入提供给文本嵌入模型时,我们得到的只是它的向量表示,这只是一组浮点数字的数组。
然后通过使用相似性搜索,我们可以通过比较向量之间的数值距离来找到文本或对象之间的相似性。这就是我们可以根据我们的浏览历史得到最佳电影推荐的方式。
考虑下面的例子:
from vertexai.language_models import TextEmbeddingModel
def text_embedding() -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings(["LLM"])
for embedding in embeddings:
vector = embedding.values
print(f"Embedding Vectors: {vector}")
print(f"Length of Embedding Vector: {len(vector)}")
return vector
if __name__ == "__main__":
text_embedding()
在这里,我们使用嵌入模型来获取文本“LLM”的向量表示。输出的结尾将类似于以下内容:
...
0.03451257199048996, 0.02128589153289795, 0.003418264677748084, -0.046265438199043274]
Length of Embedding Vector: 768
这些输出嵌入现在可以被索引和存储在向量数据库中,即向量搜索,以实现高效的低延迟检索。
业务机会
在金融领域中,数据为王,防止金融犯罪是一个不断发展的挑战。想象一下,一支取证团队面对着堆积如山的无关文件数据,以寻找关键证据进行调查。恶名昭彰的案例之一就是发生在2000年代初的安然丑闻。LLM模型可以应对这样的挑战。
在 healthcare 领域的一次演变中,大薇达(DaVita)通过使用基于数据驱动的个性化和预防性药物,从仅仅是一个透析公司转变为肾脏护理公司。患者数据洞察帮助早期发现疾病,并改善治疗计划。
在制造业中,工程师们不必从头开始构建AI/ML算法,而是利用LLM,工厂员工现在可以在几分钟内获取任何需要调整或更换的零件的机械健康状态,而无需手动滚动数周的数据。LLM可以分析历史数据、市场趋势和外部因素,提供准确的需求预测,帮助优化库存水平。
这只是一些例子,随着技术的发展,LLM的潜在应用不断扩大。它们的多功能性使它们在教育、人力资源、客户支持等各个行业都具有价值,可以自动化任务、提高生产力并提供智能见解。从更多使用案例中学习,看到许多企业通过采用GenAI获益。
毕竟,GenAI时代已经来临了 :)
Unfortunately, as a text-based AI, I am unable to access or interpret external links. However, if you provide the text that needs to be translated, I will be more than happy to assist you with translating it into simplified Chinese.
结论
虽然我们目睹了机器成功地完成简单的任务,比如文件生成,但生成型人工智能的潜力甚至可以扩展到更有雄心的事业,包括解决需要深思熟虑的问题。
我们承担着认真考虑LLM实际应用并确保其影响具有进化性而非破坏性的责任。它不仅仅是一种高级工具,也非常实用。我们可以利用它来提出全新的产品设计并改进业务流程。
使用自己的数据集并对模型进行细化调整,可以成为一名诗人、开发者,或者两者兼而有之!不要犹豫,尝试一下生成式人工智能,看看你可以创造出什么令人惊叹的事情。
不容忽视的是,下一步我将看到的是多模式双子座,很快我将对它进行研究结果的分享。







